
斯坦福大学机器学习斯坦福大学机器学习第九课“神经网络的学习(Neural Networks: Learning)”学习笔记,本次课程主要包括8部分:
1) Cost function(代价函数)
2) Backpropagation algorithm(BP算法 or 反向传播算法)
3) Backpropagation intuition(BP算法的直观解释)
4) Implementation note: Unrolling parameters(实现时的注意点:展开参数)
5) Gradient checking(梯度下降算法的验证)
6) Random initialization(随机初始化)
7) Putting it together(组合到一起-如何训练一个神经网络)
8) Backpropagation example: Autonomous driving (optional)(BP算法的例子-无人驾驶汽车)
以下是每一部分的详细解读。
1) Cost function(代价函数)
首先回顾一下神经网络的结构:
其中:
训练集是:
L = 神经网络的层数
 = 第l层的单元个数(不包括偏置单元)
= 第l层的单元个数(不包括偏置单元)
对于一个分类问题来说:
如果是一个二类分类(Binary classification),那么y = 0 或1,在神经网络的输出层上只有一个输出单元;
如果是一个多类分类(Multi-class classification), 那么
在神经网络的输出层上有K个输出单元。
Cost function:
在逻辑回归中,Cost Function的定义相对简单,如下所示:
由于神经网络的输出层通常有多个输出,属于k维向量,因此用如下的方式定义神经网络的Cost function:
注意,对于训练集的每一个样本,都需要对输出层所有的输出单元计算cost并求和。
2) Backpropagation algorithm(BP算法 or 反向传播算法)
和线性回归或逻辑回归相似,求取神经网络的参数也可以采用梯度下降算法,但是和它们二者略微不同的是,神经网络相对复杂,如果计算它的梯度?
我们知道,神经网络的Cost function是:
目标是最小化Cost function:
我们需要通过如下两个式子来计算梯度:
在上一课“神经网络的表示”里,我们给出了前馈网络的计算方法(向量化实现),对于一个给定训练样本(x, y)的神经网络,首先通过“前向传播”的方式从输入层开始计算神经网络的每一层表示,直到输出层。例如对于如下的4层神经网络:
计算的方法如下:
有了神经网络的“表示”,如何计算梯度?这个时候,我们引入反向传播算法,简称BP算法。反向算法的核心是最小化网络输出值和目标值之间的“误差”,所以这里首先引入一个关于误差的记号:
 = l 层 j 节点的误差(error)
= l 层 j 节点的误差(error)
对于神经网络输出层的单元来说,例如上例中的第4层,误差的计算比较直观:
但是对于隐藏层的误差计算,就不那么直观了:
注:有志于弄清楚为什么的同学可以参考Mitchell教授的经典书籍《机器学习》的第四章“人工神经网络”,有详细的说明。
现在我们可以给出一个完成的BP算法,至于BP算法的一些解释和说明,将会在之后的小节给出:
我们需要计算每个节点的梯度,这里通过反向传播算法达到了。
补充:关于前馈网络和BP神经网络的关系,可以参考这篇文章中的解释:
我们最常用的神经网络就是BP网络,也叫多层前馈网络。BP是back propagation的所写,是反向传播的意思。我以前比较糊涂,因为一直不理解为啥一会叫前馈网络,一会叫BP(反向传播)网络,不是矛盾吗?其实是 这样的,前馈是从网络结构上来说的,是前一层神经元单向馈入后一层神经元,而后面的神经元没有反馈到之前的神经元;而BP网络是从网络的训练方法上来说 的,是指该网络的训练算法是反向传播算法,即神经元的链接权重的训练是从最后一层(输出层)开始,然后反向依次更新前一层的链接权重。因此二者并不矛盾, 只是我没有理解其精髓而已。
随便提一下BP网络的强大威力:
1)任何的布尔函数都可以由两层单元的网络准确表示,但是所需的隐藏层神经元的数量随网络输入数量呈指数级增长;
2)任意连续函数都可由一个两层的网络以任意精度逼近。这里的两层网络是指隐藏层使用sigmoid单元、输出层使用非阈值的线性单元;
3)任意函数都可由一个三层的网络以任意精度逼近。其两层隐藏层使用sigmoid单元、输出层使用非阈值的线性单元。【注】参考自《机器学习》
3) Backpropagation intuition(BP算法的直观解释)
相对于线性回归或逻辑回归来说,BP算法不是很简洁和清晰,这一小节将解释神经网络BP算法的一些步骤,希望对大家直观的了解BP算法有一些帮助。不过Andrew Ng教授也说了:
And even though, you know, I have used back prop for many years, sometimes it's a difficult algorithm to understand.
首先从前向传播说起,下面是一个前馈神经网络的例子:
对于这个神经网络来说,它有4层,除了输出层只有1个单元外,其他每层都有2个单元(除去偏置单元)。对于一个训练样本 来说,可以通过前向传播的方式计算各个相关单元,如下图所示:
来说,可以通过前向传播的方式计算各个相关单元,如下图所示:
那么反向传播到底在做什么?首先简化神经网络的代价函数:
我们仅关注一个样本 \lambda = 0), 这样Cost function可以简化为如下的形式:
\lambda = 0), 这样Cost function可以简化为如下的形式:
那么对于样本i, BP算法在神经网络上是如何生效的? 如果记
= l 层 j 节点 的cost的误差(error)
的cost的误差(error)
其中:
BP算法主要是从输出层反向计算各个节点的误差的,故称之为反向传播算法,对于上例,计算的过程如下图所示:
注:这里有些细节没有详细描述,具体的可参考视频课程或者Mitchell教授的经典书籍《机器学习》的第四章“人工神经网络”。
4) Implementation note: Unrolling parameters(实现时的注意点:展开参数)
本节主要讲的是利用octave实现神经网络算法的一个小技巧:将多个参数矩阵展开为一个向量。具体可以参考课程视频,此处略。
5) Gradient checking(梯度下降算法的验证)
神经网络算法是一个很复杂的算法,所以有必要在实现的时候做一些检查,本节给出一个检验梯度的数值化方法。
关于梯度,有一种比较简便的数值估计方法,例如,对于一元参数来说:
可以用如下公式近似估计梯度:
其中 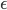 取较小的值。
取较小的值。
同理,对于多元参数或参数向量来说,上述方法同样适用:
我们的主要目标是检查这个梯度的近似向量与反向传播算法得到的梯度向量是否近似相等:
实现时的注意点:
- 首先实现反向传播算法来计算梯度向量DVec;
- 其次实现梯度的近似gradApprox;
- 确保以上两步计算的值是近似相等的;
- 在实际的神经网络学习时使用反向传播算法,并且关掉梯度检查。
特别重要的是:
- 一定要确保在训练分类器时关闭梯度检查的代码。如果你在梯度下降的每轮迭代中都运行数值化的梯度计算,你的程序将会非常慢。
6) Random initialization(随机初始化)
关于如何学习一个神经网络的细节到目前为止基本说完了,不过还有一点需要注意,就是如何初始化参数向量or矩阵。通常情况下,我们会将参数全部初始化为0,这对于很多问题是足够的,但是对于神经网络算法,会存在一些问题,以下将会详细的介绍。
对于梯度下降和其他优化算法,对于参数 向量的初始化是必不可少的。能不能将初始化的参数全部设置为0:
向量的初始化是必不可少的。能不能将初始化的参数全部设置为0:
在神经网络中:
如果将参数全部初始化为0:
会导致一个问题,例如对于上面的神经网络的例子,如果将参数全部初始化为0,在每轮参数更新的时候,与输入单元相关的两个隐藏单元的结果将是相同的,既:

这个问题又称之为对称的权重问题,因此我们需要打破这种对称,这里提供一种随机初始化参数向量的方法: 初始化  为一个落在 [
为一个落在 [ ]区间内的随机数, 可以很小,但是与梯度检验中的 没有任何关系。
]区间内的随机数, 可以很小,但是与梯度检验中的 没有任何关系。
7) Putting it together(组合到一起-如何训练一个神经网络)
关于神经网络的训练,我们已经谈到了很多,现在是时候将它们组合到一起了。那么,如何训练一个神经网络?
首先需要确定一个神经网络的结构-神经元的连接模式, 包括:
- 输入单元的个数:特征
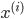 的维数;
的维数; - 输出单元的格式:类的个数
- 隐藏层的设计:比较合适的是1个隐藏层,如果隐藏层数大于1,确保每个隐藏层的单元个数相同,通常情况下隐藏层单元的个数越多越好。
在确定好神经网络的结构后,我们按如下的步骤训练神经网络:
1. 随机初始化权重参数;
2. 实现:对于每一个 通过前向传播得到 ;
;
3. 实现:计算代价函数 ;
;
4. 实现:反向传播算法用于计算偏导数 
5. 使用梯度检查来比较反向传播算法计算的和数值估计的 的梯度,如果没有问题,在实际训练时关闭这部分代码;
的梯度,如果没有问题,在实际训练时关闭这部分代码;
6. 在反向传播的基础上使用梯度下降或其他优化算法来最小化;
8) Backpropagation example: Autonomous driving (optional)(BP算法的例子-无人驾驶汽车)
关于通过神经网络来实现一个无人驾驶汽车的例子,请大家参考课程视频,此处略。
参考资料:
机器学习视频可以在Coursera机器学习课程上观看或下载: https://class.coursera.org/ml
http://en.wikipedia.org/wiki/Backpropagation
Mitchell教授的经典书籍《机器学习》
总结得超级棒
[回复]