
自然语言处理:标注
Natural Language Processing: Tagging
作者:Regina Barzilay(MIT,EECS Department, November 15, 2004)
译者:我爱自然语言处理(www.52nlp.cn ,2009年3月26日)
三、 马尔科夫模型(Markov Model)
g) 有效标注(Efficient Tagging)
i. 对于一个单词序列,如何寻找最可能的标记序列(How to find the most likely a sequence of tags for a sequence of words)?
1. 盲目搜索的方法是可怕的(The brute force search is dreadful)— 对于N个标记和W个单词计算代价是
2. 主意(Idea): 使用备忘录(Viterbi算法)(use memoization (the Viterbi Algorithm))
——结束于相同标记的序列可以压缩在一起,因为下一个标记仅依赖于此序列的当前标记(Sequences that end in the same tag can be collapsed together since the next tag depends only on the current tag of the sequence)
图示如下:
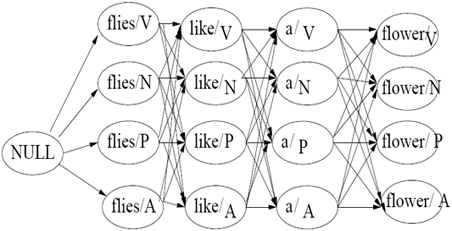
h) Viterbi 算法(The Viterbi Algorithm)
i. 初始情况(Base case):
对所有其他的
ii. 递归情况(Recursive case):
1. 对于i = 1...S.length及对于所有的
2. 回朔指针允许我们找出最大概率序列(Backpointers allow us to recover the max probability sequence):
i) 性能(Performance)
i. HMM标注器对于训练非常简单(HMM taggers are very simple to train)
ii. 表现相对很好(Perform relatively well) (over 90% performance on named entities)
iii. 最大的困难是对p(单词|标记)建模(Main difficulty is modeling of p(word|tag))
四、 结论(Conclusions)
a) 标注是一个相对比较简单的任务,至少在一个监督框架下对于英语来说(Tagging is relatively easy task (at least, in a supervised framework, and for English))
b) 影响标注器性能的因素包括(Factors that impact tagger performance include):
i. 训练集数量(The amount of training data available)
ii. 标记集(The tag set)
iii. 训练集和测试集的词汇差异(The difference in vocabulary between the training and the testing)
iv. 未登录词(Unknown words)
c) TBL和HMM框架可用于其他自然语言处理任务(TBL and HMM framework can be used for other tasks)
第四讲结束!
第五讲:最大熵和对数线性模型
附:课程及课件pdf下载MIT英文网页地址:
http://people.csail.mit.edu/regina/6881/
注:本文遵照麻省理工学院开放式课程创作共享规范翻译发布,转载请注明出处“我爱自然语言处理”:www.52nlp.cn
本文链接地址:
https://www.52nlp.cn/mit-nlp-fourth-lesson-tagging-fourth-part/
[...] MIT自然语言处理第四讲:标注(第四部分) [...]