
近日,小米开源社区发布了MiMo-VL-7B视觉语言模型技术报告,其SFT(监督微调)和RL(强化学习)版本在40多项多模态任务评测中表现惊艳,尤其在复杂推理和GUI交互领域刷新了开源模型记录。本文将深入解析其核心技术方案。
一、核心架构设计
MiMo-VL采用经典的三模块架构:
- 视觉编码器:基于Qwen2.5-ViT,支持原生分辨率输入保留细节
- 跨模态投影层:MLP结构实现视觉-语言特征对齐
- 语言模型:小米自研MiMo-7B基础模型,专为复杂推理优化
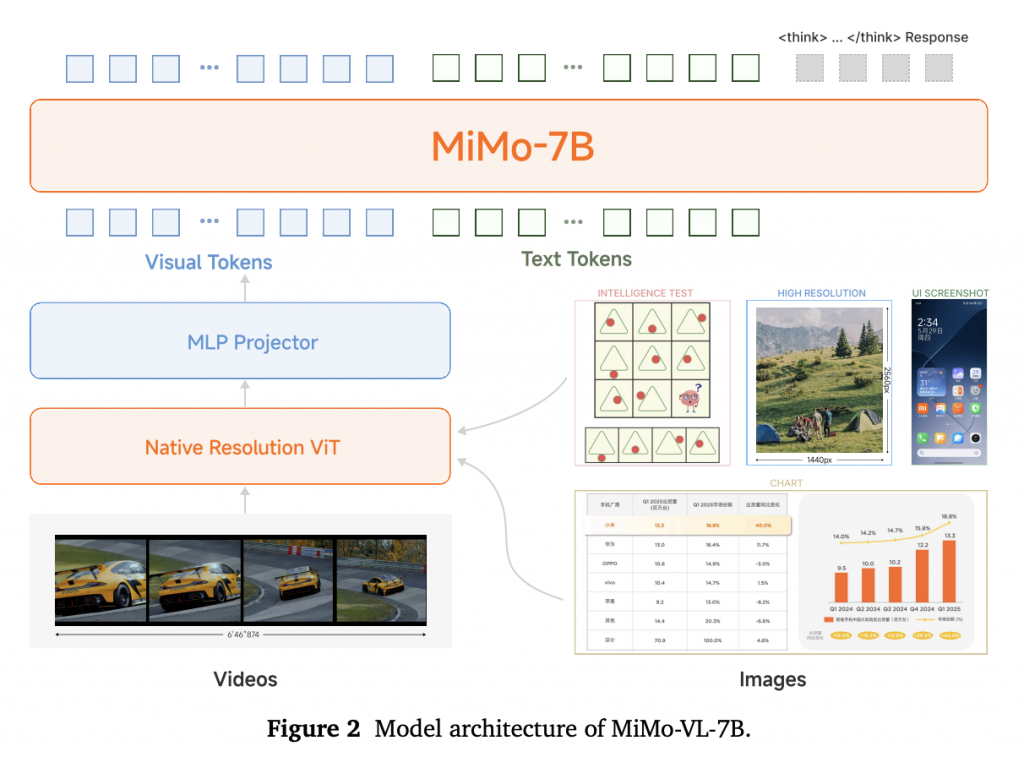
图:模型架构示意图(来源:技术报告Figure 2)
二、四阶段预训练策略(2.4万亿Token)
| 阶段 | 目标 | 关键数据 | 序列长度 |
|---|---|---|---|
| 1 | 投影层预热 | 图文对 | 8K |
| 2 | 视觉-语言对齐 | 图文交错数据 | 8K |
| 3 | 多模态预训练 | OCR/视频/GUI/推理数据 | 8K |
| 4 | 长上下文SFT | 高分辨率图像/长文档/长推理链 | 32K |
核心突破:在阶段4注入合成推理数据(含长思维链),使模型在MMMU任务响应长度从680 token跃升至2.5K token,推理深度显著提升。
三、混合强化学习(MORL)
创新性地融合两类奖励信号:
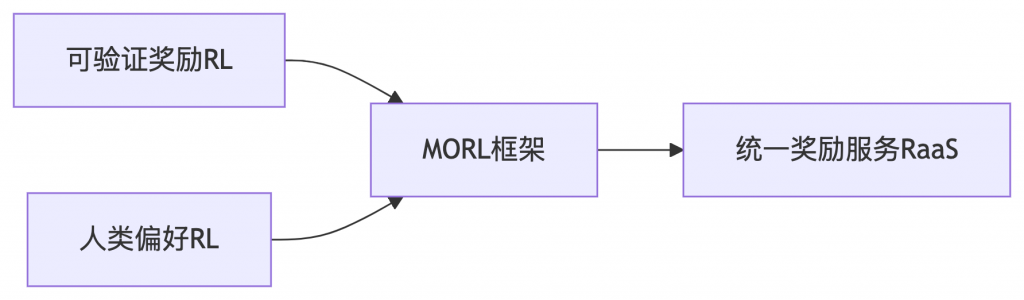
- 可验证奖励(RIVR):
- 数学推理:基于Math-Verify库自动验证
- 目标定位:GIoU计算边界框精度
- 视频时序定位:IoU评估时间片段
- 人类偏好奖励(RLHF):
- 构建双语偏好数据集
- 分离训练文本/多模态奖励模型
- 采用Bradley-Terry目标函数
技术优势:通过完全同策略GRPO算法避免传统RL性能饱和问题(见图7对比),实现稳定优化。
四、性能突破
- 基础视觉理解:
- MMMU-val:66.7%(超越Gemma 3 27B)
- CharXiv-RQ:56.5%(领先Qwen2.5-VL 14%)
- 复杂推理:
- OlympiadBench:59.4%(超越72B模型)
- MathVision:60.4%(较SFT提升2.5%)
- GUI交互:
- OSWorld-G:56.1%(超越专用模型UI-TARS)
- 统一动作空间支持跨平台操作(详见表5)
- 用户体验:
- 开源模型中最高Elo评分
- 接近Claude 3.7 Sonnet水平
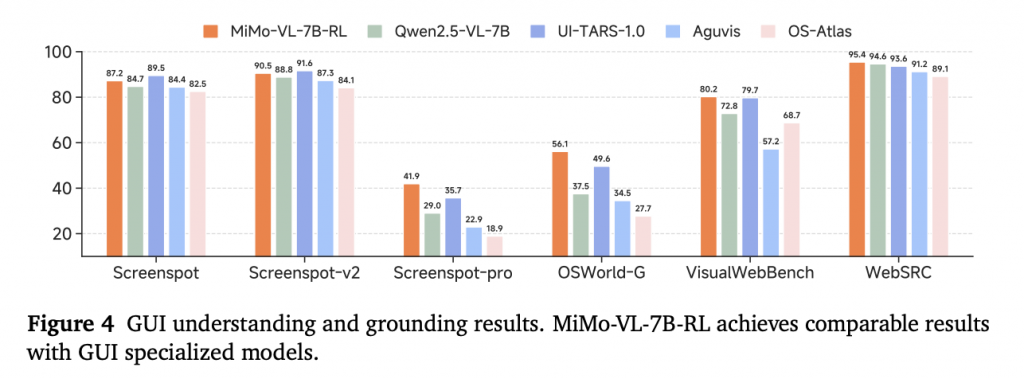
图:GUI任务性能对比(来源:技术报告Figure 4)
五、关键洞见
- 推理数据前置:预训练后期引入长链合成数据,比微调效果提升显著
- 多任务RL冲突:感知任务需简短输出,推理任务需长链思考,优化目标存在张力
- 奖励工程挑战:不同任务奖励量纲差异需归一化处理(RaaS服务实现)
六、开源生态
- 模型权重:完整开放SFT/RL版本
- 评测框架:覆盖50+任务的LMMs-Eval增强版
- 数据集:包含GUI动作空间定义等工业级数据
结语
MiMo-VL-7B通过三阶段创新—— 精细数据配比预训练、混合奖励强化学习、工业场景专项优化,证明了小模型在复杂多模态任务上的巨大潜力。其在STEM问题求解(见图13)、GUI自动化(见图9)、长文档解析等场景的表现,为开源社区提供了新的技术标杆。
附小米MiMo-VL技术报告英中对照版,仅供学习参考: