
前几天在AINLP公众号上分享了国内一个新兴AI算法竞赛平台FlyAI:FlyAI算法竞赛:百万现金奖励实时瓜分,FlyAI算法竞赛平台比较有意思的一点是可以实时分享相关赛道的奖金池,另外完全使用FlyAI官方的GPU资源在线训练模型和提交结果,这一点,对于没有GPU条件的同学来说也是很有吸引力的。
关于文本挖掘或者计算机视觉相关的AI数据竞赛,我觉得如果没有很好的实习机会,参加一些这样的比赛是可以积攒一定的实战经验的,赛事官方一般会为每个任务准备一套baseline流程来熟悉平台和任务,这也是一个很好的学习机会。我之前通过AIChallenger的中英机器翻译比赛熟悉了NMT的整套流程和相关工具和算法,感兴趣的同学可以参考:《AI Challenger 2017 奇遇记》 和 《AI Challenger 2018 简记》。
关于FlyAI算法竞赛平台,官方是这样介绍的:
FlyAI 是隶属于北京智能工场科技有限公司旗下,为AI开发者 (深度学习)提供数据竞赛并支持GPU离线训练的一站式服务平台。每周免费提供项目开源算法样例,样例所使用开发框架涉及TensorFlow、Keras、PyTorch. 支持算法能力变现以及快速的迭代算法模型。挑战者,都在FlyAI!
四大特点:
1. 高质量的数据集、多领域的开源项目案例
1.1 项目涉及领域:自然语言处理、图像识别、语音识别等
1.2 每周更新高质量项目专属代码样例,免费下载查看
1.3 支持多平台运行,一键配置学习环境
2 多卡GPU资源 一键使用
2.1 提供强大算力,快速迭代模型质量
2.2 一键提交离线训练服务,及时通知模型训练进度
3 能力变现、竞赛式项目实力打榜
3.1 挑战项目刷新排行榜,赢得高额悬赏
3.2 使用不同深度学习框架验证,提升自己的算法能力
4 全行业的数据化及AI需求发布平台
4.1 通过算法众包,建立精准的预测模型,为产品数据增长赋能
4.2 探索数据人才与企业需求的生态构建
FlyAI上目前的自然语言处理相关竞赛不是太多,不过官方表态会不断上新,感兴趣的同学可以密切关注。目前FlyAI上NLP相关的竞赛包括:搜狗新闻文本分类预测、美国点评网站Yelp评价预测赛、测测星座文本分类、根据商品评分推荐商品算法练习赛、人工智能和你对对联。前三个有实际的奖金、后两个是练习赛,奖励FAI积分,这个可用于平台上GPU训练资源消耗,不过目前如果你通过这里AINLP的专属链接(https://www.flyai.com/?s=u9Fn9rW4f)注册并且加入到FlyAI竞赛-AINLP官方群,是可以直接找FlyAI小姐姐要积分的,目前该群接近300人,里面有官方技术人员答疑,已无法通过直接扫码加入,加群前请通过AINLP专属链接注册,然后添加AINLP君(id: AINLP2)拉你入群,请务必注明FlyAI:
https://www.flyai.com/?s=u9Fn9rW4f
好了,废话少说,假期花了点时间趁机体验了一下FlyAI的比赛流程,以搜狗新闻文本分类预测比赛为例,这是一个典型的文本多分类问题:
大赛简介
该数据集来自若干新闻站点2012年6月—7月期间国内,国际,体育,社会,娱乐等18个频道的新闻数据。根据新闻正文内容分析新闻的类别参赛须知
参赛时间: 本次竞赛无时间限制,长期有效开放如何参赛?
请在项目详情页点击【立即报名】按钮,首次需验证手机号、完善报名信息
请点击本页的【资料下载】按钮,下载参赛资料并详细阅读README.md文件
首先即使注册FlyAI了,参加单项比赛点击【立即报名】的时候也需要再填写一下姓名和手机号信息,这个和之后的奖励有关,每个平台都差不多,填写完之后就会刷新为【资料下载】,下载资料后其实里面的README写得非常详尽,这里要赞一下FlyAI的团队,如果不出什么意外,其实通过这份README基本上可以在Linux、Mac OS和windows平台下走通FlyAI的比赛流程,以下是我在ubuntu16.04下的记录,走得是Linux & Mac方法,windows下的使用方法相似,请直接参考官方README文件。
首先对下载的sogouNews_FlyAI.zip进行解压,然后进入到项目的根目录下,相关文档、样例代码和执行脚本官方平台已准备好:

在Ubuntu下使用 ./flyai 脚本文件:
chmod +x ./flyai
执行下列命令并使用微信扫码登录
./flyai init
登录成功之后,会自动下载运行所需环境
本地开发调试
如果想本地开发测试,可以执行
./flyai test
或者安装项目所需依赖requirements.txt,运行 main.py
提交训练到GPU
项目中如有新的引用,需加入到 requirements.txt 文件中
我没有修改一行样例代码,所以在终端下直接执行
./flyai train
返回sucess状态,代表提交离线训练成功
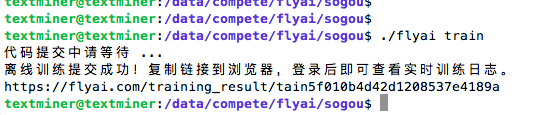
训练结束会以微信和邮件的形式发送结果通知
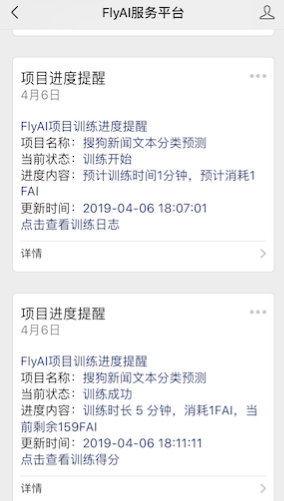
默认训练成功后不公开在项目排行榜中,如果你修改了代码并希望公开项目可以在提交训练时执行
./flyai train -p=1
完整训练设置执行代码示例:
./flyai train -p=1 -b=32 -e=100
通过执行训练命令,本次训练循环 100 次,每次训练读取的数据量为 32 ,公开提交模型
其实官方的README写得已经很详尽了,以下选择README中的代码部分的说明,样例代码已经实现了,也是一份不错的学习资源。
样例代码说明
app.yaml
是项目的配置文件,项目目录下必须存在这个文件,是项目运行的依赖。
processor.py
样例代码中已做简单实现,可供查考。
处理数据的输入输出文件,把通过csv文件返回的数据,处理成能让程序识别、训练的矩阵。
可以自己定义输入输出的方法名,在
app.yaml中声明即可。def input_x(self, text): ''' 参数为csv中作为输入x的一条数据,会被Dataset类中的next_batch()方法多次调用。 :params: 输入的数据列表 :return: 返回矩阵 ''' pass def input_y(self, label): ''' 参数为csv中作为输入y的一条数据,会被Dataset类中的next_batch()方法多次调用。 :params: 数据标签列表 :return: 返回矩阵 ''' pass def output_y(self, data): ''' 验证时使用,把模型输出的y转为对应的结果 :param data: 预测返回的数据 :return: 返回预测的标签 ''' pass
main.py
样例代码中已做简单实现,可供查考。
程序入口,编写算法,训练模型的文件。在该文件中实现自己的算法。
通过
dataset.py中的next_batch方法获取训练和测试数据。# 数据获取辅助类 dataset = Dataset() x_train, y_train, x_test, y_test = dataset.next_batch(BATCH)通过
model.py中的save_model方法保存模型# 模型操作辅助类 model = Model(dataset) model.save_model(YOU_NET)如果使用
PyTorch框架,需要在net.py文件中实现网络。其它用法同上。
model.py
样例代码中已做简单实现,可供查考。
训练好模型之后可以继承
flyai.model.base包中的base重写下面三个方法实现模型的保存、验证和使用。def predict(self, **data): ''' 使用模型 :param data: 模型的输入的一个或多个参数 :return: ''' pass def predict_all(self, datas): ''' (必须实现的方法)评估模型,对训练的好的模型进行打分 :param datas: 验证集上的随机数据,类型为list :return outputs: 返回调用模型评估之后的list数据 ''' pass def save_model(self, network, path=MODEL_PATH, name=MODEL_NAME, overwrite=False): ''' 保存模型 :param network: 训练模型的网络 :param path: 要保存模型的路径 :param name: 要保存模型的名字 :param overwrite: 是否覆盖当前模型 :return: ''' self.check(path, overwrite)
predict.py
样例代码中已做简单实现,可供查考。
对训练完成的模型使用和预测。
path.py
可以设置数据文件、模型文件的存放路径。
dataset.py
该文件在FlyAI开源库的
flyai.dataset包中,通过next_batch(BATCH)方法获得x_trainy_trainx_testy_test数据。FlyAI开源库可以通过
pip3 install -i https://pypi.flyai.com/simple flyai安装。
最后,如果你在实际操作前后依然遇到问题,欢迎加入FlyAI竞赛-AINLP官方群,这里可以直接找FlyAI小姐姐要积分的,里面有官方技术人员答疑,目前该群已接近300人,无法通过直接扫码加入,请添加AINLP君(id: AINLP2)拉你入群,请务必注明FlyAI:

注:原创文章,转载请注明出处及保留链接“我爱自然语言处理”:https://www.52nlp.cn
本文链接地址:FlyAI算法竞赛平台初体验 https://www.52nlp.cn/?p=11496
您说的那个中英文对照语料库,去哪里可以获得呢?
[回复]
52nlp 回复:
8 4 月, 2019 at 14:01
中英文对照语料库?你问的是ai challenger上的那个比赛语料库吧?
[回复]