
在上一节中,我们看到了HMM分词器的优势在于它的灵活性,能够联系上文情况作出是否分词的判断,但是过于灵活又会出现一些低级的分词错误。一种扬长避短的想法是使用词典限定HMM的分词。具体的做法是,用基于词典的分词方法分出N种结果,然后用HMM挑出最有可能的分词结果。
介绍一下分词使用的词典,在《中文分词入门之资源》有提到:
Mandarin.dic 分词词典,约40000条词汇
对于一段文本,找出所有可能的切分结果叫做全切分,全切分可以保证切分结果集对正确切分结果100%的召回率,换句话说全切分中一定包含正确结果(在不包含未登录词的前提之下)。长度为n的句子,最大全切分数量可以达到2`(n-1)个,因此全切分计算量会随着句子长度增加急剧上升。举例,句子“研究生命起源”的全切分如下:
研/究/生/命
研/究/生命
研究/生/命
研究/生命
研究生/命
共有5个切分方案,其中倒数第二个是正确切分。下面讲一下我对句子进行全切分用的具体算法。
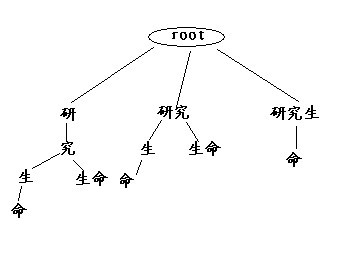 如上图,考虑构建一颗多叉树,其中每一条从root到叶子节点的路径均为一种分词结果,所有root到叶子节点的路径就是全切分的结果。树的建立方法是使用的递归:
如上图,考虑构建一颗多叉树,其中每一条从root到叶子节点的路径均为一种分词结果,所有root到叶子节点的路径就是全切分的结果。树的建立方法是使用的递归:
对句子进行正向词典匹配,结果为:
研 对剩余句子:究生命 进行词典匹配
研究 对剩余句子:生命 进行词典匹配
研究生 对剩余句子:命 进行词典匹配
全切分结果准备就绪,下面的问题是如何从备选分词中选出最佳分词结果,因为备选结果只有有限的数量,因此可以使用枚举算法求最佳解:
ArgmaxC,O P(C|O)
解法在第2集中已经提到,等价于求:
ArgmaxC,O P(O|C)P(C)
为了避免计算溢出(小数位数太多计算机无法表示),我们改为求:
ArgminC,O -lnP(O|C) – lnP(C)
对于句子“研究生命”,分词结果如下:
研/究/生/命:44.24491284128293
研/究/生命:37.12604972173189
研究/生/命:33.59480382540995
研究/生命:26.49050292705271
研究生/命:32.15705471620734
其中“研究/生命”拥有最低值,被选为最优解。再举一些有意思的分词结果:
研究生/研究/生活
结合/成/分子
他/说/的/确实/在/理
可以看出这种混合分词器能够灵活的掌握字符间的分和,消除一些歧义分词。
下面是我对几种分词方法的实验结果,同时使用了ICTCLAS2011作为一个权威的分词效果比对,其中ICTCLAS2011使用的是它自带的词典,其他分词方法使用的词典是Mandarin.dic:
每秒分词 P R F
普通最大词匹配 5482401 0.76 0.85 0.80
扩展的最大匹配 1118591 0.79 0.75 0.77
普通的Markov 1590173 0.76 0.72 0.74
混合的Markov 46818 0.73 0.84 0.78
ICTCLAS2011 942973 0.92 0.92 0.92
可以看出ICTCLAS果然是名不虚传,相对于混合的Markov,ICTCLAS使用的是层叠式的HMM模型,可以很好的识别出未登录词;其次ICTCLAS使用了基于N-最短路径的切分,对计算效率也有很大的提高。
PS:因为之前没有想过要分享分词的程序,所以写得比较混乱,最近也很忙,我会尽快整理发上来的。
写的很好,希望能分享下程序,让我们初学者知行合一就好了。
[回复]
您好!我非常想看看从普通最大匹配到混合的Markov代码的具体实现,希望您不吝赐教。谢谢了
[回复]
itenyh 回复:
6 5 月, 2013 at 11:47
不好意思,代码真的很久没去处理了,如果需要帮助加我的 qq 405243093
[回复]
博主,你好!
参考你的思路,我也用Python实现了一遍。
https://github.com/taozhijiang/chinese_nlp.git
目前感觉效果不是很理想,比如我的例子:
掌握字符间的分和
字符也被分开了。
我想,在HMM方向,如果要深入下去,还有哪些可以改进和增强的方向?
谢谢!
[回复]