
无需蒸馏、抛弃SFT,Mistral用纯强化学习在数学与代码推理任务上实现50%性能飞跃
近日,Mistral AI发布了其首个纯强化学习训练的推理模型系列Magistral,并开源24B参数版本Magistral Small。这份技术报告揭示了其革命性的训练框架,不仅挑战了当前主流RLHF范式,更在多语言推理、跨模态泛化等方面带来突破性发现。本文将深入解析其技术脉络。
一、核心创新:纯RL训练框架
与传统RLHF依赖监督微调(SFT)蒸馏不同,Magistral采用完全从零开始的强化学习路径:
- 基础模型:基于Mistral Medium 3(数学/代码推理)和Small 3(轻量版)
- 训练方式:仅用强化学习(RL)优化,跳过任何预训练推理轨迹的蒸馏步骤
- 关键优势:避免教师模型偏差,直接探索模型原生推理能力
性能结果震撼:
- Magistral Medium在AIME-24数学竞赛基准上达到73.6% pass@1,较基础模型提升近50%
- LiveCodeBench(v5)得分59.4%,提升30%(见表2)
markdown
复制
下载
| 任务 | Mistral Medium 3 | Magistral Medium | 提升幅度 | |----------------|------------------|-----------------|--------| | AIME'24 (pass@1) | 26.8% | 73.6% | +174% | | LiveCodeBench v5 | 29.1% | 59.4% | +104% |
二、算法引擎:深度改造GRPO
Magistral的核心是改进版Group Relative Policy Optimization (GRPO),包含五大关键创新:
1. KL散度消除
- 传统PPO/GRPO依赖KL惩罚防止策略偏移
- Mistral发现KL计算成本高且效果有限,直接移除KL项
- 结果:训练速度提升20%,无性能损失
2. 损失归一化设计
- 原始GRPO存在生成长度偏差
- 创新方案:按组内总token数归一化损失
Loss = Σ(损失) / Σ(组内token数) - 消除长度对梯度的影响
3. 信任域上限放松
- 放宽ε-clipping上限至
ε_high=0.26-0.28 - 允许模型探索低概率但高价值推理路径
- 关键作用:防止熵崩溃,提升输出多样性(见图12)
4. 优势值归一化
- 提出三级归一化流程:
组内去中心化 → 小批次标准化 → 序列级平滑 - 公式简化:
Â_i = r_i - μ(μ为组内平均奖励)
5. 非多样性组过滤
- 自动剔除全对/全错的提示组(零优势组)
- 减少噪声梯度,提升训练稳定性
三、奖励工程:精准塑造推理行为
Magistral的奖励函数设计极为精细,覆盖四个维度:
1. 格式奖励(0.1分)
- 数学输出:要求
\boxed{}包裹答案 - 代码输出:需包含带语言标识的代码块
- 格式错误直接得0分(终止评估)
2. 正确性奖励(0.9分)
- 数学:基于SymPy的符号等价验证
- 代码:执行20个测试用例(10秒编译+4秒/测试)
- 全对才获得0.9分
3. 长度惩罚
python
复制
下载
if len(y) ≤ l_max - l_cache: penalty = 0 elif len(y) ≤ l_max: penalty = -0.1*(len(y)-l_max+l_cache)/l_cache else: penalty = -0.1 # 硬截断
4. 语言一致性奖励(0.1分)
- 用fastText检测问题、思维链、答案语言一致性
- 支持六种语言(法/西/德/意/俄/中)
- 实现效果:用户用中文提问,模型全程用中文推理(见表4)
四、基础设施:异步RL训练系统
为支撑大规模RL训练,Mistral构建了分布式架构:
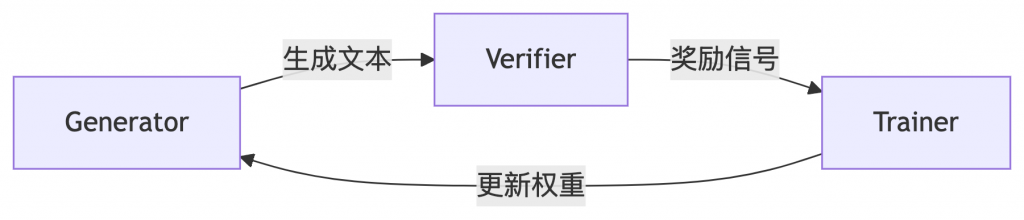
- 三大组件:
- Generator:实时生成文本(不中断当前生成)
- Verifier:并行评估奖励
- Trainer:聚合梯度更新
- 关键技术:
- 权重通过NCCL广播(更新延迟<5秒)
- 动态批次分割:按token数贪婪分桶,减少19%填充
- KV缓存复用:避免重新计算隐藏状态
五、颠覆性发现
1. RL提升多模态能力
- 反直觉现象:纯文本训练竟提升多模态性能
- MMMU-Pro视觉子集准确率+12%(图10)
- 归因:文本推理能力泛化到多模态场景(见图14-16案例)
2. 小模型RL训练可行
- 传统认知:小模型需蒸馏才能达到RL效果
- Magistral Small(24B)纯RL训练:
- AIME-24 pass@1 65.8% → 接近蒸馏模型水平
- 推翻DeepSeek等团队的结论(表3)
3. 跨领域泛化
- 数学单领域训练 → 代码任务提升15.6%
- 代码单领域训练 → 数学任务提升17.5%(表5)
- 证明RL习得的是通用推理能力
六、重要取舍:无效方案披露
报告坦承分享失败实验:
- 代码部分奖励:
- 按测试通过率给分 → LiveCodeBench下降2%
- 最终采用二进制奖励(0/0.9)
- 熵奖励项:
- 传统熵奖励导致训练不稳定
- 改用调整
ε_high控制探索程度
七、开源与影响
- 开源模型:
Magistral Small(24B)Apache 2.0许可(HuggingFace链接) - 行业意义:
- 证明纯RL训练大模型的可行性
- 为轻量化模型提供新路径(避免依赖教师模型)
- 未来方向:
- 多模态RL训练
- 自我引导推理轨迹优化
附Magistral技术报告英中对照版,仅供学习参考: