
这两天技术群都在传阿里通义 Qwen3 五一前后发布,然后昨晚各种消息满天飞:
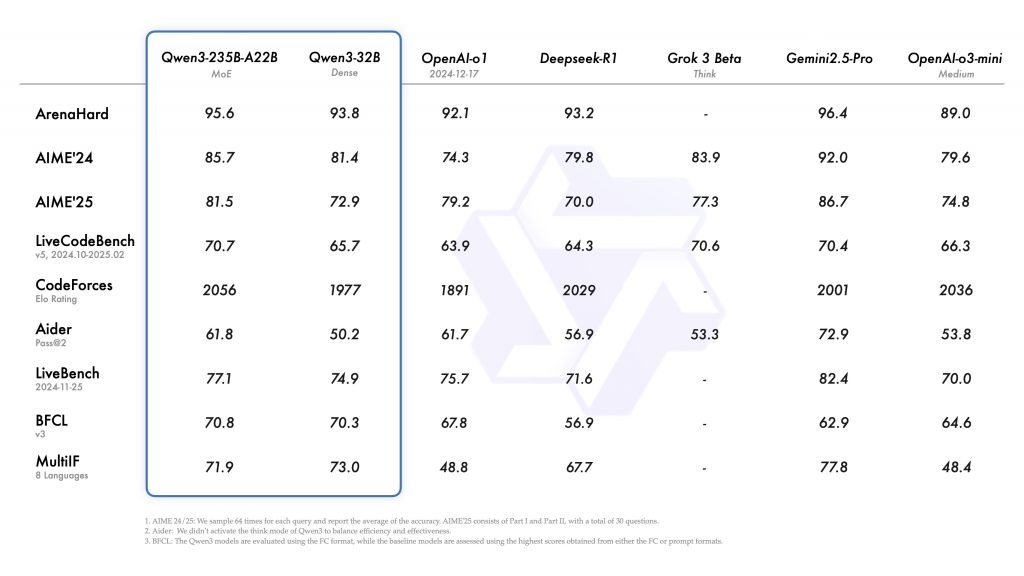
一觉醒来,千问果然没有让人失望,赶在五一前发布并开源Qwen3,效率杠杠的。作为国内首个实现"混合推理"能力的开源模型,Qwen3不仅达到了36万亿token的训练数据量,还支持119种语言和方言。通过混合专家(MoE)架构与混合推理机制的深度整合,在参数效率与任务适应性层面实现双重突破。旗舰模型Qwen3-235B-A22B在数学证明、代码生成等核心基准测试中,展现出与DeepSeek-R1、Grok-3等顶尖模型的竞争优势。
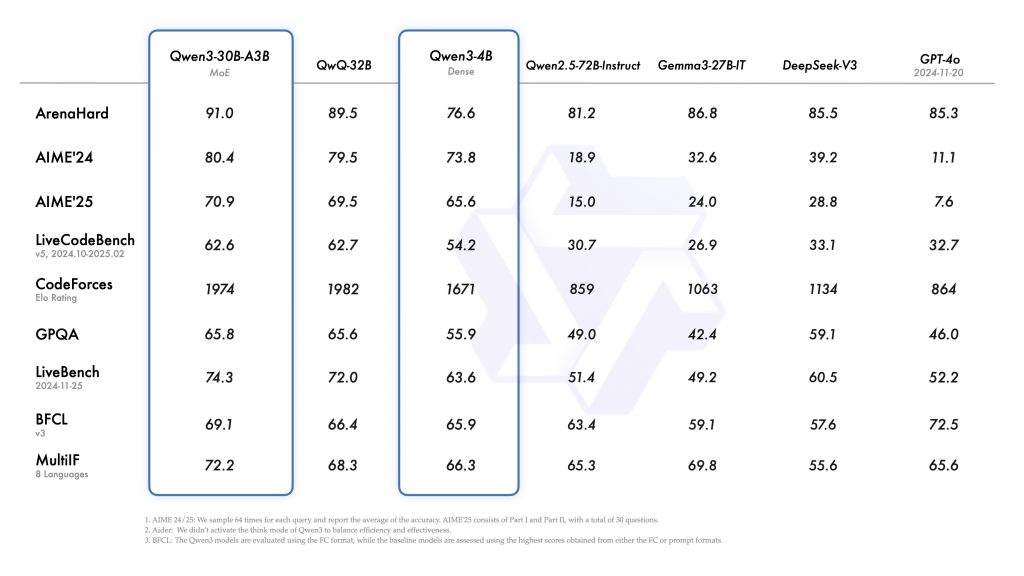
此外,小型 MoE 模型 Qwen3-30B-A3B 的激活参数量仅为 QwQ-32B 的 10%,但性能却更胜一筹。甚至像 Qwen3-4B 这样的小型模型,也能与 Qwen2.5-72B-Instruct 的性能相媲美。
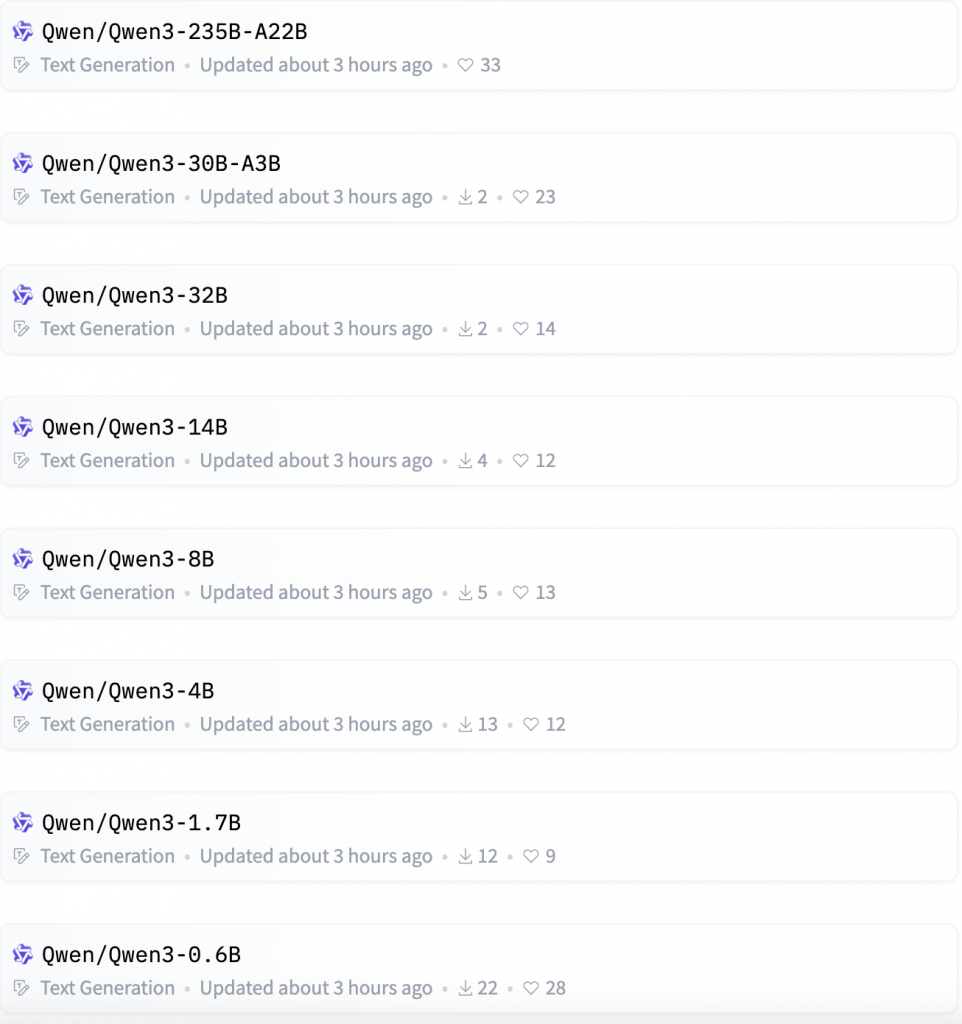
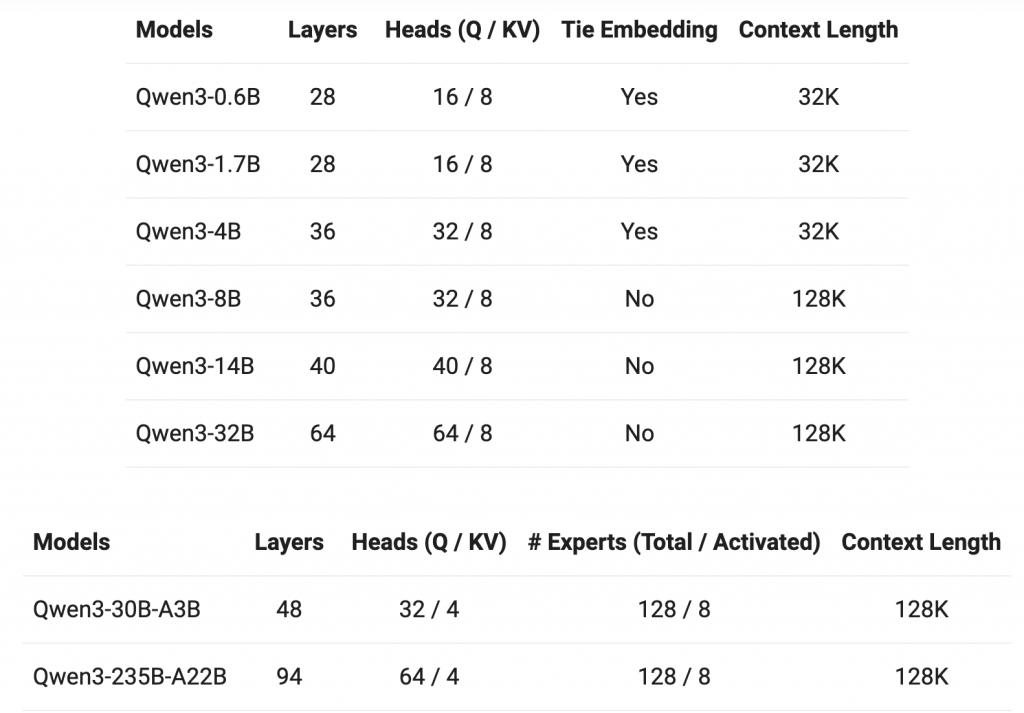
Qwen3 此次开源了六款Dense模型和两款Moe模型,Dense模型包括0.6B、1.7B、4B、8B、14B、32B 6个尺寸,Moe模型包括30B和235B,均采用Apache2.0协议开源,诚意满满。其中旗舰版 Qwen3-235B-A22B,总参数量 235B,激活参数仅 22B,可以低成本实现本地部署。而 Qwen3-30B-A3B,总参数量 30B,激活参数仅 3B,消费级别显卡即可部署,整体性能堪比Qwen2.5-32B。另外阿里还开源了小尺寸的 Qwen3-0.6B,可以在手机等端侧部署。
特别值得注意的是Qwen3是国内首个“混合推理模型”,在同一模型中集成了两种推理模式:
- 即时响应模式:针对简单查询(如信息检索),通过轻量化推理路径实现快速响应;
- 深度思考模式:应对复杂任务(如数学证明),激活MoE架构中的专家模块进行多步推理;
- 动态切换机制:支持API参数控制(enable_thinking=True)或自然语言指令(/think)触发模式转换;
另外Qwen3的多语言能力进一步大幅跃升,从之前支持的29种提升至支持119种语言和方言:
- 国际通用语言:完整涵盖联合国六大官方语言(汉语、英语、法语、西班牙语、俄语、阿拉伯语);
- 国家官方语言:包括德语、意大利语、日语、韩语、泰语、越南语等国家官方语言;
- 特色方言及小语种:特别纳入中国粤语、非洲斯瓦希里语、中东意第绪语、西亚亚美尼亚语、东南亚爪哇语、美洲海地克里奥尔语等具有文化代表性的地方语言;
通过开源技术赋能,千问3为全球技术储备不足的国家和地区提供了可用的AI大模型,让语言不再成为数字时代的鸿沟。
同时Qwen3通过原生支持MCP多模态协作协议,构建了面向智能体(Agent)生态的核心能力,其深度集成的工具调用架构支持跨平台设备控制与工业协交互,结合开箱即用的Qwen-Agent框架,开发者可快速构建复杂工作流,如生产线调度、跨端自动化等,标志着大模型从"生成答案"向"完成任务"的范式跃迁。
目前可以在欢迎在 Qwen Chat 网页版和通义 APP 中直接体验 Qwen3,相关地址如下:
- Qwen Chat:https://chat.qwen.ai/
- GitHub:https://github.com/QwenLM/Qwen3
- HuggingFace:https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f
- ModelScope:https://modelscope.cn/collections/Qwen3-9743180bdc6b48
Qwen3 快速体验
说了这么多,我还是想动手体验一下 Qwen3,直接在Qwen Chat网页版上体验:
可下拉选择相关模型:
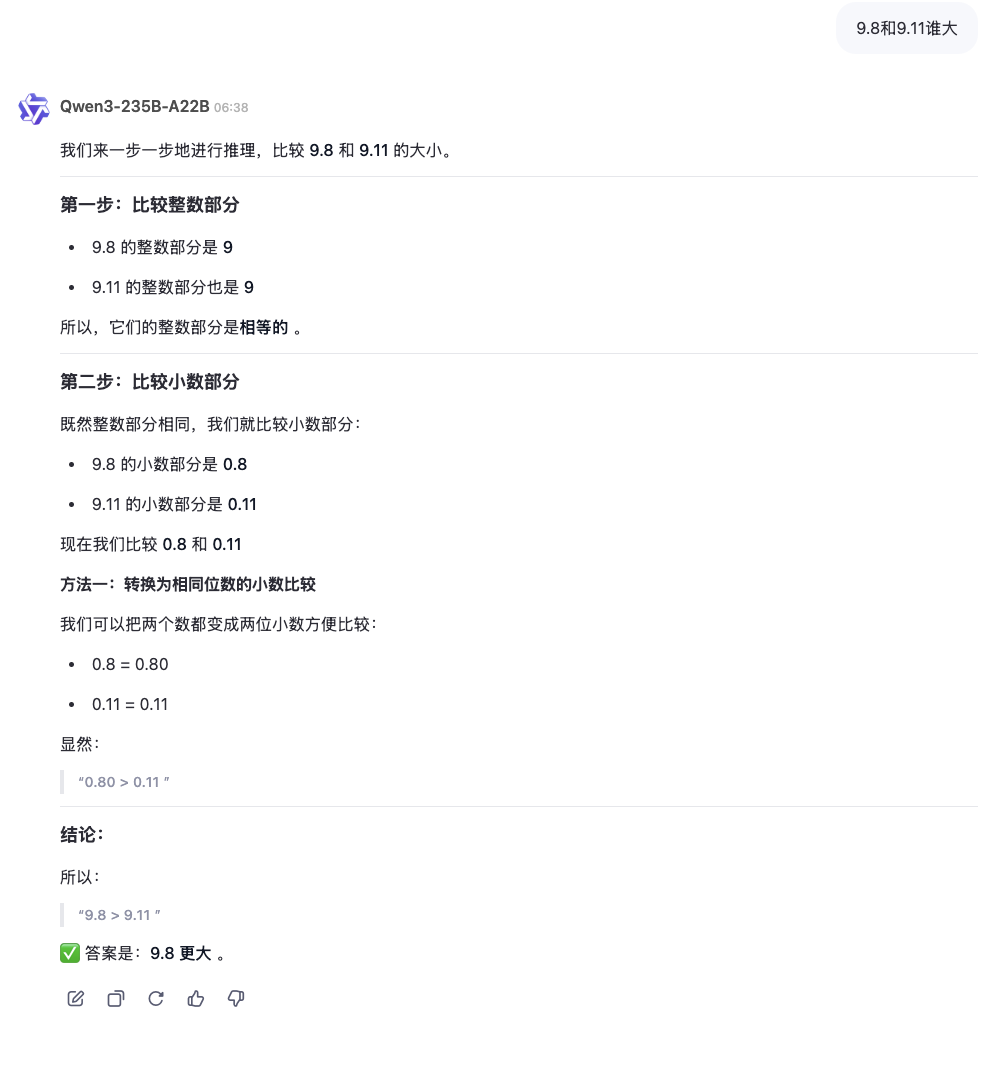
开始测试那个经典问题:9.8和9.11谁大,直接给了推理过程和答案,相当快:
再来一个经典大模型测试题:strawberry有几个r,还是直接给出推理过程和答案:
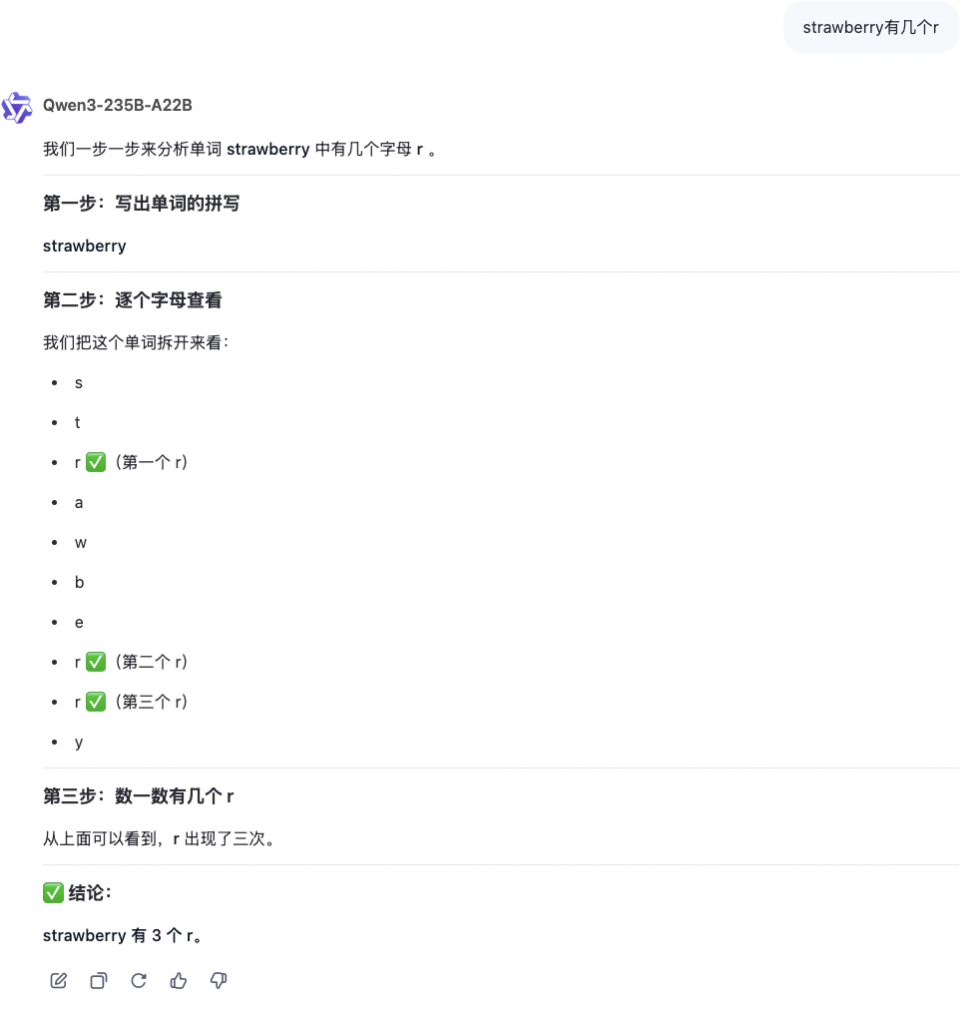
看起来一般问题难不倒大模型了,那就做一道中考级别的数学题吧:
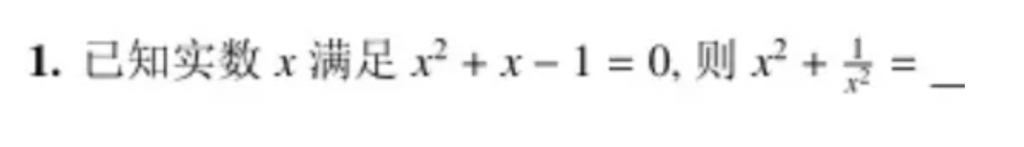


中考题难不住,继续上高考数学题,这是一道2024年年高考全国甲卷数学(文)试题:

这次思考的过程稍久,不过依然得到了正确答案:-7/2,看起来一般的高考题也难不住Qwen3了,这让我很期待今年高考数学题国内外这些顶尖大模型的PK了。

测试 Qwen3 模型
当然除了体验网页版,我还想上手体验一下开源的Qwen3模型,直接选择最小的0.6B模型,复用Qwen官方博客上提供的代码,只是简单修改了一下模型:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-0.6b"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switch between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
第一次运行模型下载速度挺快的,但是遇到了报错:
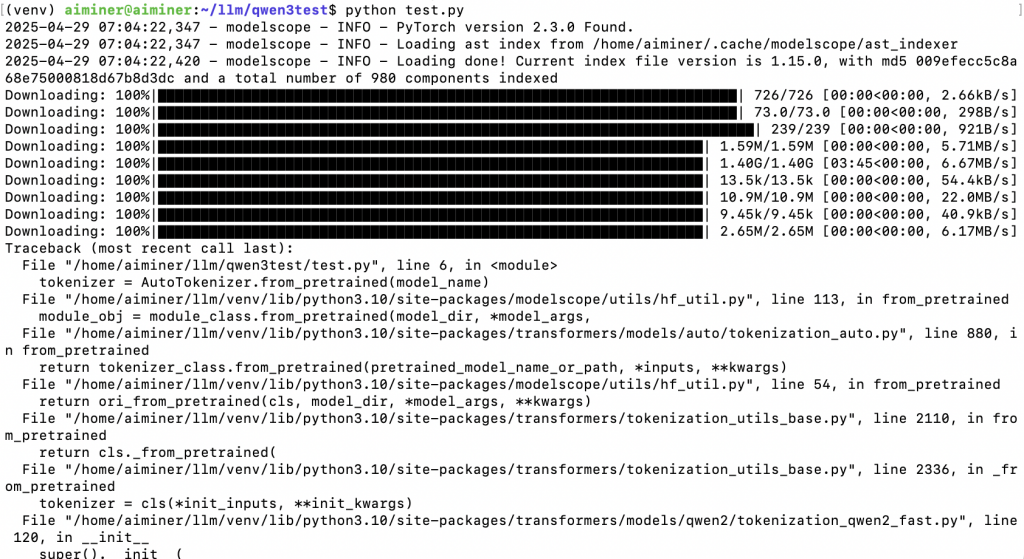
刚好看到一篇文章说运行Qwen3 transformers版本不能小于4.51.0,直接升级transformer到4.51.0,再次运行,没有问题了,测试成功:

要禁用思考模式,只需对参数 enable_thinking 进行如下修改:
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # True is the default value for enable_thinking.
)Qwen3模型还有很多高级玩法,包括在用户提示或系统消息中添加 /think 和 /no_think 来逐轮切换模型的思考模式,以及Agent和MCP等,限于时间关系,这里就不一一测试了,后续我会测一下更大尺寸的模型,到时候深入研究一下。刚好五一放假,大家可以好好安排五一了!