
背景
CIKM Cup(或者称为CIKM Competition)是ACM CIKM举办的国际数据挖掘竞赛的名称。CIKM全称是International Conference on Information and Knowledge Management,属于信息检索和数据挖掘领域的国际著名学术会议,由ACM SIGIR分会(ACM Special Interest Group on Information Retrieval)主办。
随着数据挖掘技术越来越重要,CIKM会议的影响力也水涨船高,逐渐逼近KDD、WWW、ICDE。2014年是CIKM第一次在中国大陆举办,邀请了Google大神Jeff Dean,微软EVP陆奇博士和德国Max Planck Institute的Gerhard Weikum教授担任Keynote Speaker,盛况空前。CIKM很重视工业界的运用,既有面向工业届的Tutorial/Workshop,也有CIKM Cup这样面向实战的国际数据挖掘竞赛(类似另一个著名的数据挖掘竞赛KDD Cup),比赛使用真实的工业界数据和应用课题,让全世界的数据挖掘选手们一较高下。

今年的CIKM Cup竞赛的题目是自动识别用户的查询意图(Query Intent Detection,QID),主办方提供了来自百度线上的真实的用户查询和点击的数据(总行数为6141万行),竞赛目标是根据已标注的用户行为数据,来判断其中用户查询时的真实意图,要求识别的准确率和召回率越高越好。比赛历时2个半月,共吸引了520支队伍参赛,最终我们的队伍Topdata脱颖而出,所提出的算法以F1值0.9296排名Final Leaderboard第一获得冠军!
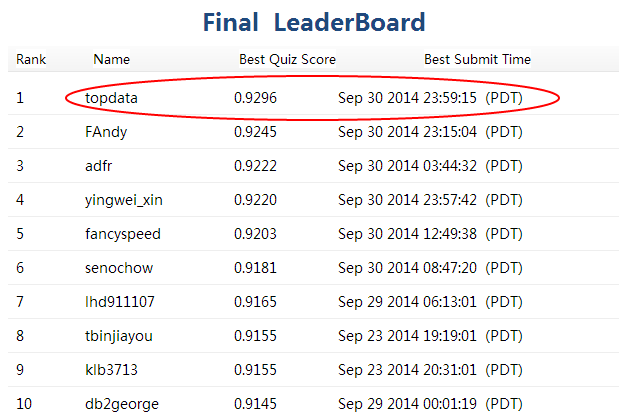
应很多朋友的邀请,发表这篇文章详细介绍我们使用的方法,给对大数据挖掘算法感兴趣的朋友们作个参考。另外在领奖现场我们和其他参赛队伍作了愉快的交流,因此本文也吸收了其他队伍的一些优秀思路,可以看作是这次竞赛整体方法和对策的总结。文章最后还附上了一些我个人的参赛感言(陈运文)。
竞赛题目介绍
百度提供的数据是用户在搜索引擎上真实完整的查询过程。用户与搜索引擎的一轮完整交互过程称为一个Search Session,在Session里提供的信息包括:用户查询词(Query),用户所点击的搜索结果的标题(Title),如果用户在Session期间变换了查询词(例如从Query1 -->Query2),则后续的搜索和点击均会被记录,直到用户脱离本次搜索,则Session结束。
训练样本中已标记出了部分Query的查询意图,包括“VIDEO”, “NOVEL”, “GAME”, “TRAVEL”, “LOTTERY”, “ZIPCODE”, and “OTHER”7个类别。另一些未知类型样本标记为“UNKNOWN”。标记为“TEST”的Query则是要预测类别的样本。竞赛的训练数据形如:
Class1 Query1 Title1
Class1 Query1 Title2
Class2 Query2 -
Class2 Query2 Title3
Class3 Query4 Title5
注: “-”号表示用户当前进行了Query变换(当次没有发生点击行为);空行表示Session结束。
需要指出的是竞赛提供的文本数据按单字(注:连续的字母或者数字串视为单字)进行了加密(以避免因中文NLP处理能力的差异影响竞赛结果)。用7位数字串加密后的训练样本形如:
CLASS=GAME 0729914 0624792 0348144 0912424 0624792 0348144 0664000 0267839 0694263 0129267 0784491 0498098 0683557 0162820 0042895 0784491 0517582 1123536 0517582 0931307 0517582 1079654 0809167
CLASS=VIDEO 0295063 0706287 0785637 0283234 0982816 0295063 0706287 0785637 0283234 0335623 0437326 0479957 0153430 0747808 0673355 1112955 1110131 0466107 0754212 0464472 0673355 0694263
CLASS=UNKNOWN 0295063 0706287 0785637 0283234 1034216 0999132 1055194 0958285 0424184 -
具体的数据产生方法、格式介绍等可以详见链接:
http://openresearch.baidu.com/activitycontent.jhtml?channelId=769
训练样本中已标记的Query类型包括“VIDEO”, “NOVEL”, “GAME”, “TRAVEL”, “LOTTERY”, “ZIPCODE”, and “OTHER”7个,注意存在一些跨两类的样本,例如CLASS=GAME | CLASS=VIDEO 0241068 0377891 0477545。
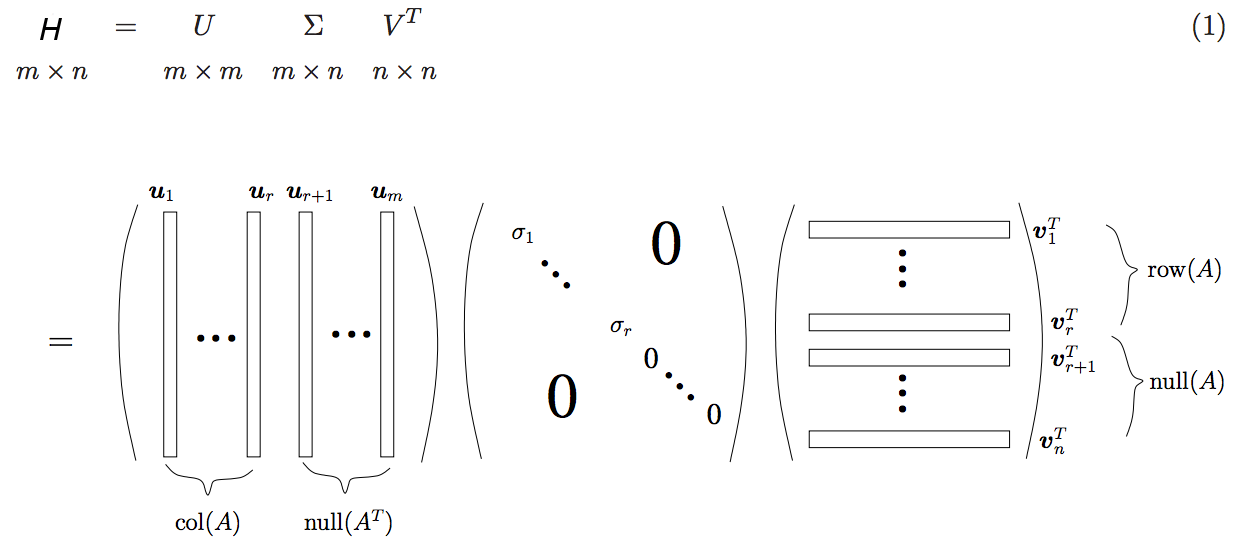
算法竞赛的评价方法是信息检索中常用的F1值,实际计算时会先计算各个类别的Precision和Recall值,再合并为F1(macro):

基础分析
本届CIKM竞赛题可视为一个经典的有监督机器学习问题(Supervised Learning),经典的模式分类(Pattern Classification)方法:包括特征抽取、分类训练等技术都能沿用,对机器学习有所了解的朋友们应该能很快上手。不过与经典的文本分类问题相比,这里有几个特别的注意点:
1 类别不完全互斥,存在交叉。即Query有可能同时属于多个类别,而存在交叉的Query往往是查询意图表达不明确、存在多义的情况。如搜“极品飞车”,既可能是指一款电脑游戏(CLASS=GAME),也有可能是同名的电影(CLASS=VIDEO)。
2 样本分布不均匀。包括两个方面:从类别方面来看,训练样本多寡不均(VIDEO类样本数量是ZIPCODE类的40倍);从Query频次方面来看,少数热门Query出现频次极高,大量冷门Query特征稀有,这和现实环境的搜索类似。这里尤其需要注意的是,在评估函数中,计算各类别的Macro Precision和Recall时,由于分母是该category的Query number,所以越是稀少的类别,其每个Query的预测精度对最终F1值的影响越大。换句话说冷门类别对结果的影响更大,需要格外关注。
3 训练样本里存在两个特殊类别。一个是“OTHER”、另一个是“UNKNOWN”。“OTHER”和其他6个已知类别并列,且不存在任何交叉,可以认为OTHER类别包含比较杂的Query需求,同时OTHER样本数量很多(仅次于VIDEO类)。UNKNOWN则是在生成训练集合时,由于同Session中有已知Category的样本而被带出来的,类别未标注。UNKNOWN样本的数量非常大,有2901万条,几乎占了训练样本总行数的一半。
4 Search Query以短文本为主,Query通常极为精炼(3-9个字为主,甚至存在大量单字Query),特征比较稀疏。而Query有对应的很多点击Title,充分挖掘好两类文本间的关系,对提升效果会有很大的帮助。
5 提供了Session信息。Session中蕴藏着上下文Query间、Query和对应的Title间的紧密关系。不同Session里相同Query所点击的不同Title、或不同Title反向对应的Query等关系网也能被用来提高识别效果。
基于上述的分析,我们首先尝试了一些最朴素的文本分类思路,包括基础性的一些数据统计和特征提取、Session信息统计、简单的分类算法或分类规则等(例如朴素贝叶斯、最近邻、决策树等分类器),这样F1值能达到0.8左右。这个初步尝试过程我认为是挺有必要的,因为能帮助我们把握数据分布的情况、加深对问题的理解,是后面精益求精的起点。
文本特征提取
Query和Title的加密后的文本信息是可以非常直观的提取基础的文本特征的。在赛后和其他优胜队伍交流时,发现几乎所有的队伍在这个环节都采用了N-gram的方法进行文本处理。 在使用N-Gram语法模型时,我们使用了double(right & left)padding的方法生成Unigram、Bigram、Trigram特征向量(如下图),实验中我们使用NLTK来完成开发:
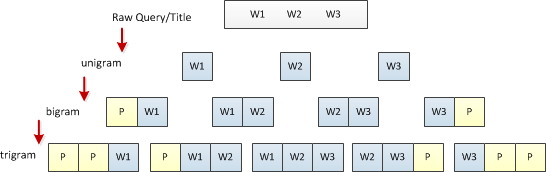
比赛中N-gram Model我们只用到了Tri-gram,原因是4-gram或更高维的N-gram特征带来的效果收益极其微小,但带来特征向量的巨大膨胀,模型训练时间大幅度延长,而竞赛提供的有限的训练样本数量无法让如此高维的特征向量得到充分训练,所以权衡后我们放弃了后面的特征。

除了上述通用的N-grams特征外,还有一些思路来判断表义能力强的词汇,加入训练样本的特征向量:
- 分析各个Category的N-grams词汇的分布,抽取只在某个category中出现的N-gram。这些词汇的区分度强,我们挖掘得到的各个类别的特征词典形如下图
- 根据TF(term frequency)、IDF等统计特征可以用来进行gram的筛选工作,降低特征维数并提高精度
- 统计某word和前后word的分布概率,通过P(w_i|w_pre)或P(w_i|w_after)选择成词概率高的词汇
- 有队伍强化了Query的尾部/头部gram的权重,可能也对提高识别准确率有所帮助

值得一提的是,在提取这些Bag of Words特征阶段,有几支队伍使用了Google开源工具Word2Vec来处理NGrams,SkipGrams,Co-occurrence Ngrams问题,Word2Vec提供了良好的词汇关系计算方法,很好的提高了开发效率。
统计特征提取
从实际问题中能抽取的基础统计特征非常多,各个队伍的方法可谓五花八门。用得比较多的特征包括:
- Query的长度
- Query的频次
- Title的长度
- Title的频次
- BM-25
- Query的首字、尾字等
其它细致的特征还能发现很多。需要指出的是,其中当特征为连续值时,后续形成特征向量时往往需要离散化,即分段映射特征到对应的feature bucket中。
分类框架的两个注意点
在设计基本的分类算法模型时,有两个点需要需要提前注意:
1 多分类问题的处理方式
前面已经提到过,一个需要关注的现象是样本中存在跨两个类别的数据。待测样本中也同样会有跨类的情况。应该如何处理这样的样本呢?一个直观的思路是将跨类的样本进行拆分,即如果一条训练样本为:
CLASS=A | CLASS=B Query1
则在生成训练样本时转变为:
CLASS=A Query1
CLASS=B Query1
在预测阶段,则根据分类的结果,取超过阈值Threshold的Top2 CLASS进行合并:
Query_TEST,<CLASS1, weight1>, <CLASS2, weight2> ... ---> Query_TEST CLASS1 | CLASS2
但上述方法会遇到两个问题:第一个问题是同一训练样本分拆到不同类别后,会导致两个类别样本重叠,分类平面难以处理,影响模型训练精度;第二个问题是在合并Top2 Class生成结果时阈值的设定对结果影响很大,但这个参数Threshold的确定又缺乏依据,因此最终精度的波动会很大。
所以比赛中我们没有选择上述的拆分处理方法,而是将多类的训练样本单独作为一个类别,这样总的待分类别数量增加到15类(注:一个细节是category的先后顺序要先归一,即CLASS1 | CLASS2 = CLASS2 | CLASS1)。动机是我认为跨类别的样本有其特殊之处(如往往较短的Query查询意图不明。而长Query跨类的相对少,搜“龙之谷”可能是找游戏或电影,但如果搜“龙之谷 在线观看”则明确在找电影)。将跨类样本作为独立类别来进行特征抽取和分类,能够将这些特征更好的运用起来,对识别效果是有帮助的,我们的对比实验也证实了这个想法。
2 Query-Title样本的组织方法
Taining Data中很多Query多次出现,并对应不同的Title。训练过程中可以将每一个<Query, Title>Pair作为一条训练样本来用。这样形成的训练样本的数量有数千万条,但是每则样本的文本很短,抽取的特征比较有限。
另外一个处理方式是首先将相同Query对应的Title进行归并,以Query为单位来构成一条训练样本,形如:
Query1, Title_11, Title_12, Title_13 …… Title_1n
Query2, Title_21, Title_22, Title_23 …. Title_2n
归并后的训练样本总数降为3.87万条,待测样本数量为3.89万条,和前面的方法相比,这样来做有2个收益:第一是训练样本数量减少了3个数量级,训练速度大为加快;第二是每条训练样本的文本长度增加,能进行更复杂的特征抽取(例如利用LDA等抽取Topic信息)。因此在实践中我们采用了这种方式组织样本。
经过上述的过程,我们为训练样本和测试样本生成近100w维的特征向量(有的队伍进行了特征降维和筛选,如PCA变换等)。紧接着可以选择一个分类器(Classifier)进行模型的训练和分类。以常见的SVM(支持向量机)为例,我们可以轻松获得超过0.90的F1-Score:
./ svm-train -t 2 -c 10000 -m 3000 -b 1 ${train_feature_file} ${svm_model_file}
./svm-predict -b 1 ${test_feature_file} ${svm_model_file} ${pred_file}
顺便一提,SVM里对结果影响最大的是 -c 参数,这是对训练过程中错分样本的惩罚系数(或称损失函数)。另外-t参数确定的是核函数的类型,实践证明-t 2 RBF核(默认值)的效果要比线性核、多项式核等效果略好一些。
Query间关系的分析
除了Term级的特征抽取,围绕Query为粒度的特征分析也极为重要,Session提供了大量的上下文Query给我们参考,这对提高算法的识别精度有很大的帮助,下面是我们的处理方法:
1 Query间特征词汇的挖掘
在分析Session log的过程中,一个有意思的发现是往往用户的查询词存在递进关系。尤其在前面的Query查询满意度不高的情况下,用户往往会主动进行Query变换,期望获得更满意的结果。而此时Query变换前后的Diff部分能强烈的表达用户的查询意图。
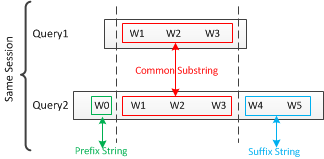
如上图,通过在同Session的上下文中(半径为R的范围内)提取出存在一定相似度的Query1和Query2,找到Diff部分的前缀(Prefix String)和后缀(Suffix String),它们可以认为是Query的需求词/属性词集中的部分,形成特征后对提高精度起到了很好的帮助。
2. Query间共现关系的运用
类似数据挖掘中“啤酒与尿布”的经典故事,Query和Query如果频繁在同一个Session中共现,则也可以认为两个Query有紧密的相关关系,事实上这也是搜索引擎挖掘生成相关查询词(related query)的一个思路。
实践中可以通过挖掘共现关系(Co-occurrent)生成当前Query的相关Query集合,将这些Query的属性作为特征来加以利用。进一步的,为保证精度,还可进一步通过Query Similarity的计算(例如各种距离公式)来过滤噪音,筛选出文本上具备一定相似度的Query。例如通过Jaccard distance或Dice Coefficient:
![]()
![]()
进一步筛选出文本相关性强的Query pair,将Query id,class作为特征向量的一部分发挥作用
3 生成Query的Family Tree
我们挖掘Query和Query间的传递关系并形成了一个家族树(Family Tree),家族树的概念是如果两个Query之间存在真包含关系,即Query1 ⊂ Query2,则Query1为Son,Query2为Father;Father和Son是多对多关系,两个Query如果有共同的Father且互相没有包含关系则为Brother。
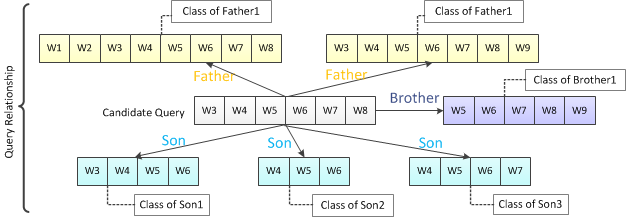
显然通过Family Tree我们可以将Query亲属的Category作为该Query的特征向量的一部分来发挥作用
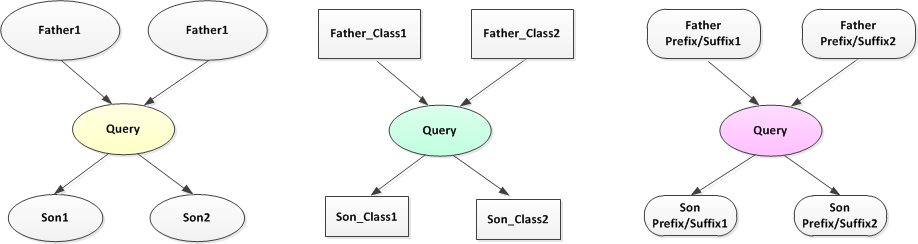 4 Query的Macro Features
4 Query的Macro Features
整体来分析Query所在的Session的category分布情况,可以提取search behavior的Macro Feature,
另外当前Query上下文的query、title,以及这些query对应的类别,这些Context信息也都可以纳入使用
Query-Title关系的分析
这次竞赛比较有意思的是Query和对应的Title构成了一个个的关系对<Query, Title>,从微观(Word粒度)和宏观(Q-T之间的关系网结构)等不同角度来观察Query-Title间关系,我们有以下发现:
1.Query-Title关系的微观分析
我们发现Query和Title往往是存在共同的词汇(公共子串)。搜索引擎通常会把Title里和Query相同的词汇重点提示给用户(例如百度文字飘红,Google加粗文字),这些Query-Title中相同的词汇往往是最为重要的语料,对这些词汇的使用方法又可以包括:
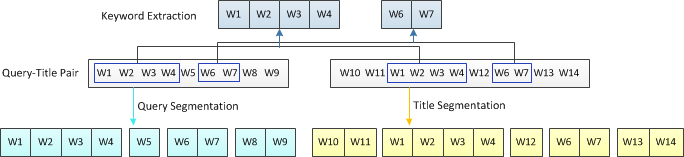
- 将Query-Title的公共子串作为Keyword进行提取,形成特征(上图上部蓝色块)
- 对Keyword进一步构成N-gram词袋
- 利用公共子串作为分割点,对Query和Title进行分词(弥补没有原文导致常用的文本分词方法无法使用),将Query、Title分别切割所得的大粒度phrase片段可作为特征使用
- Query-Title关系的宏观关系挖掘
如果将Query和Title都视作一个图(Graph)结构中的节点,则Query-Title点击对则是Graph的边(Edge),Query和Title的多对多的关系能形成类似下图的结构,很像一个社交网络
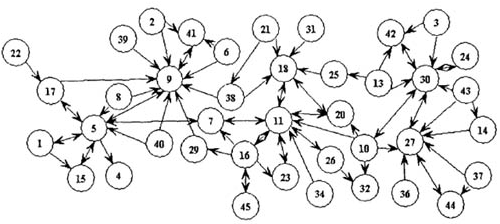
社交网络中的智能推荐的思想也可以在这里运用。类似推荐系统中的<User, Item>关系对,这里<Query, Title>的关系可以使用协同过滤(Collaborative Filtering)的思想,当两个Query所点击的Title列表相似时,则另外Query的category可以被“推荐”给当前Query;
协同过滤既可以自定义距离计算公式的方法(Distance-based)来计算,也可以采用基于矩阵分解(Model-based)方法来计算,后者精度往往更高。因此比赛中我们采用了SVD分解的方法来解析Query-Title关系,实践中我们发现SVD++算法没有在SVD基础上有提升,Title或Query的特征作为隐式反馈引入后反而会降低,因此我们将特征放入Global bias Feature里使用
- Click Model的使用
用户的搜索点击模型(Click Model)其实是一个非常大的话题,涉及到用户查询满意度的建模和分析。在今天的搜索引擎技术中,通过Click Model衍生出了众多的功能,包括搜索满意度的自动监控、搜索结果的自动调权调序等。而这些技术的出发点都是User Behavior数据。
在Session信息里,用户的点击行为往往能提供丰富的信息:在搜索结果从上至下被用户浏览的过程中,当被点击的结果中间出现了跳跃,例如Query1对应的自然排序结果是Result1, Result2, Result3…, 但是如果大量用户的点击是Result1, Result3, 则Result2的相关性可能存在问题;
另外一种情况是,如果同一个Query产生了一次点击后,间隔一段时间后再次出现了对后面结果的点击,则也许说明了之前结果的满足度不够高。
在同一个Session里,用户发生主动Query变换(或称为Query Re-write)也往往能说明问题,前面的Query如果搜索结果质量不高,则很多用户会选择修改查询词,此时前面被点击的Title重要程度往往不如后续的Title,等等各类场景很丰富。
以上各类的Click Model思想虽然在实际线上系统中被广泛运用,但竞赛中没有提供更详细的信息,包括点击结果在搜索中的排序(对于分析点击模型至关重要)、点击发生的时间、点击停留间隔、用户的Cookieid/Userid等,限制了发挥,真实应用里,通过Click Model来对用户查询意图的把握,应该可以更深入的进行挖掘
Title关系以及其他特征
Title的文本分析也可以进一步提供有价值的特征。例如很多网页的Title中会携带网站的机构名称或者网页的属性词(例如Title可以是 “XXXXX---东方航空公司”、“XXXXX---爱奇艺网”、“XXXXX---第一视频门户”等)
这些语素对精确的预测用户的需求会有非常高的价值。通过分析存在相关点击的Title之间的公共子串,提取出这些高价值的子串是有价值的。但竞赛中Title的文字被加密处理,实践上述思路比较困难。实践中这条路应该是完全行得通的。
另外Title和Title之间的关联关系也同样可以沿用Query-Query之间关系的处理方法,在此不再赘述。
Topic Model也是经常被使用的文本分析方法。有队伍将每个Query点击的所有Title合并起来进行LDA进行主题建模,据说也起到了不错的效果
本次竞赛中,特征的抽取和运用仍然是极为重要的环节,虽然Deep Learning等摆脱特征工程的机器学习新框架逐步在成长,但是在实际运用中,面向具体应用的“特征抽取+模式分类算法”仍然是解决问题不可或缺的利器。
模式分类算法
分类(Classification)可谓是机器学习(Machine Learning)领域的经典话题,学术界多年来提出了种类繁多的方法,经典教材也有很多,例如Sergios Theodoridis等著的《Pattern Recognition》、Christopher M. Bishop等著的《Pattern Recognition And Machine Learning》。这里不赘述方法原理,分享一些实战中总结的经验 (陈运文)。
实践中特征向量维数一般很高,训练样本的数量往往也很多,对模型的性能和效果都有很高的要求。竞赛中我们也尝试了很多分类方法,分以下几个侧面来谈一谈:
1 单模型分类算法
经典的单模型分类方法有很多,在对比了决策树、朴素贝叶斯、最大熵(EM)、人工神经网络(ANN)、k近邻、Logistic回归等方法后,我们选用了SVM(Support Vector Machine)作为单模型分类器。
这里尤其要感谢台大的林智仁老师,LibSVM这个著名的开源软件包训练快速、稳定,精度高,能够让SVM在各类工业应用中方便的使用。在CIKM会议期间有幸当面听了林老师的讲座,他分享了开发机器学习软件包的心得,尤其在通用性、易用性、稳定性等方面的一些注意点。
2 组合模型模式分类算法
基于组合思路的分类算法能提供非常高的分类精度,经典的组合模型思想包括Boosting(AdaBoost)和Bagging(Bootstrap Aggregating)两大类。这两种方法都有深刻的理论背景,在很多实践运用中都取得了显著的效果。组合思想在实践中最知名的包括GBDT(Gradient Boosting Decision Tree)和Random Forests(随即森林),这两类方法都是基于决策树发展演化而来(CART,Classification And Regression Tree),精度高,泛化能力强,通常比单模型方法效果出色,竞赛中被广泛采用,取得了不错的成绩。尤其当待处理特征是连续值时,GBDT和Random Forest处理起来要更优雅。
3 矩阵分解模型
矩阵分解(Matrix Factorization)通常作为分类辅助工具使用,如常用于特征降维的PCA变换等,在分类之前可以进行特征空间的压缩。
另外在推荐系统中(区别与分类),一般认为效果较好的方法是SVD(或其改进版本,俗称SVD++),在这次CIKM Competition中,我们也使用了SVD进行分类操作,通过对Query-Title关系进行SVD分解,并加入各种特征后,能达到0.9096的F1-Score,虽然SVM的单模型我们最好能达到0.9192,两者相差有1%,但SVD方法通过后续的Ensemble能发挥很好的作用。
4 Ensemble框架
Ensemble技术可谓是精度提升的大杀器,本次竞赛最终成绩Top3队伍都不约而同的采用了它。
Ensemble的基本思想是充分运用不同分类算法各种的优势,取长补短,组合形成一个强大的分类框架。俗话说“三个臭皮匠顶个诸葛亮”,而如果基础的分类算法也已经很优秀了,那就是“三个诸葛亮”组合起来,就更加厉害了。需要注意的是Ensemble不是简单的把多个分类器合并起来结果,或者简单将分类结果按固定参数线性叠加(例如不是 a1 * ALGO1 + a2 * ALGO2 + a3 * ALGO3),而是通过训练Ensemble模型,来实现最优的组合。
在Ensemble框架下,我们分类器分为两个Level: L1层和L2层。L1层是基础分类器,前面1、2、3小节所提的方法均可以作为L1层分类器来使用;L2层基于L1层,将L1层的分类结果形成特征向量,再组合一些其他的特征后,形成L2层分类器(如SVM)的输入。这里需要特别留意的是用于L2层的训练的样本必须没有在训练L1层时使用过。
Ensemble的训练过程稍微复杂,因为L1层模型和L2层模型要分别进行训练后再组合。实践中我们将训练样本按照特定比例切分开(由于竞赛的训练样本和测试样本数量比为1:1,因此我们将训练样本按1:1划分为两部分,分别简称为Train pig和Test Pig)。基于划分后的样本,整个训练过程步骤如下:
Step1:使用Train pig抽取特征,形成特征向量后训练L1层模型
Step2:使用训练好的L1层模型,预测Test pig,将预测结果形成L2层的输入特征向量
Step3:结合其他特征后,形成L2层的特征向量,并使用Test pig训练L2层模型
Step4:使用全部训练样本(Tain pig + Test pig)重新训练L1层模型
Step5:将待测样本Test抽取特征后先后使用上述训练好的L1+L2层Ensemble模型来生成预测结果
基于Ensemble技术,F1-Score可以从0.91XX的水平一跃提升到0.92XX。
5 Ensemble的几个设计思路
在设计Ensemble L1层算法的过程中,有很多种设计思路,我们选择了不同的分类算法训练多个分类模型,而另外有队伍则为每一个类别设计了专用的二分分类器,每个分类器关注其中一个category的分类(one-vs-all);也可以选择同一种分类算法,但是用不同的特征训练出多个L1层分类器;另外设置不同的参数也能形成多个L1层分类器等
L1层分类器的分类方法差异越大,经过L2层Ensemble后的整个分类系统的泛化效果往往更好,不容易出现过拟合(overfitting)。
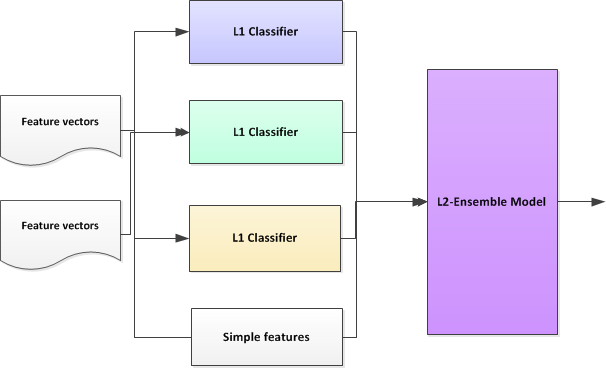
Ensemble的L2层算法也可以有很多种选择,常用的分类器都可以尝试使用,我们选择的L2层算法也是SVM。另外Logistic Regression, GBDT和RBM(Restricted Boltzmann Machines)也是使用得比较多的L2层组合算法。
数据预处理、后处理和其他一些操作
现实系统中的数据通常都是比较杂乱的,实际应用中往往50%的精力需要分配给数据的理解和清洗工作。尽管竞赛中百度提供的搜索日志已经处理过了,但是仍然可以进行一些归一、去重、填充等预处理(Preprocess)操作。实战中我们进行了一系列处理后(例如去除重复行,无意义的行等),Train文件的行数减少了约20%,一方面能加快运算速度,另一方面也使各类统计计算更准确。
对预测结果的后处理(Postprocess)也是有必要的。在Postprocess阶段可以对分类预测的结果最终再进行一些调整,包括对跨类别结果的合并(合成CLASS=A|B的结果);少量稀有类别的召回;针对一些特殊类型(如特别短或少)Query的定制规则等等,会对最终效果有些许的提升。
在数据处理的整个过程中,还会遇到一些数据的归一、平滑、离散等处理细节,篇幅所限不展开说了。
竞赛中UNKNOWN数据的填充也是一个思路,但是我们在这方面的各种尝试一直没有取得成效。其实前面提到的种种方法,也是从各种失败的尝试中总结和寻找出来的,10次尝试里有9次都是失败的,但是千万不要气馁,阳光总在风雨后。
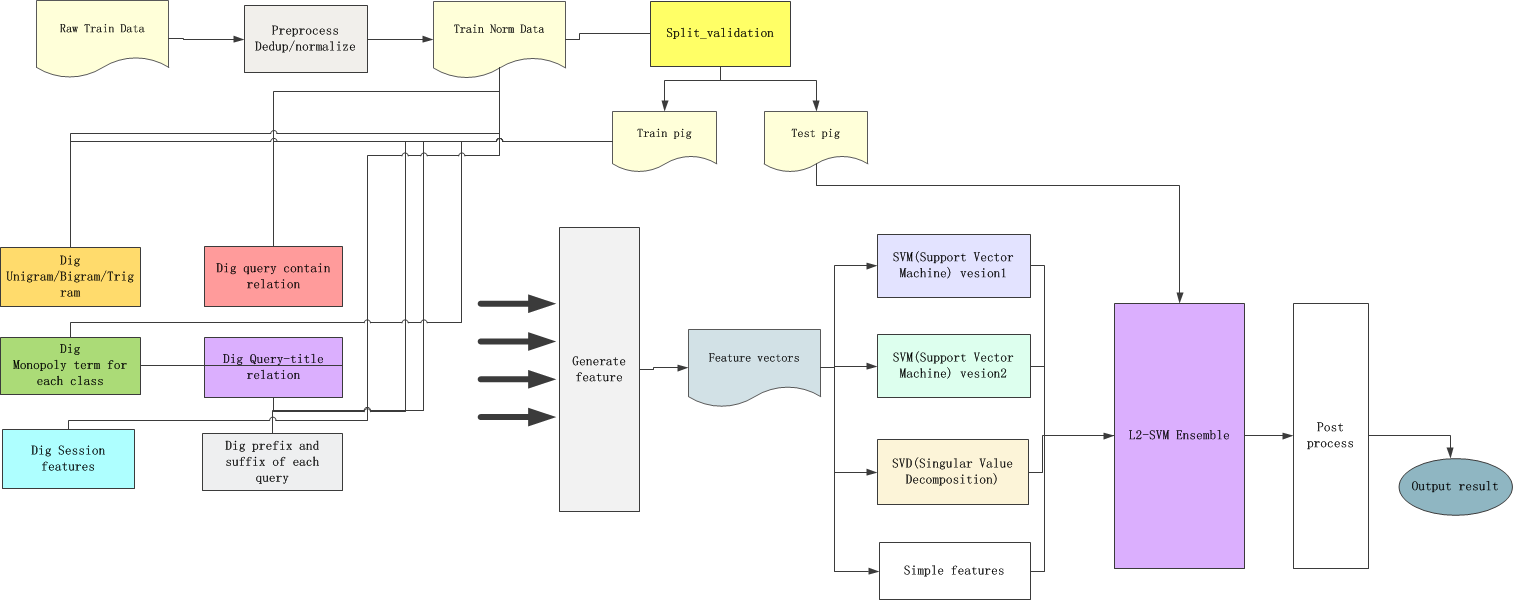
我们整体的处理流程图如下
夺冠经历和感言
回顾最近几年我们夺得过好名次的数据挖掘竞赛,包括KDD Cup 2012亚军、EMI推荐算法竞赛冠军、和这次的CIKM Competition 2014冠军,我最大的体会是任何时候都要坚持到底,不轻易放弃。
因为无论参加哪个比赛,竞赛期间总会遇到痛苦的瓶颈期,所有的尝试都验证是无效的,仿佛所有出路都被堵死了。这次的CIKM竞赛也不例外,在渡过初始阶段势如破竹的进展后(参赛一周时间后我们队伍就打入了排行榜Top10),很快我们就碰到了天花板,接下来的2周多时间里可谓倍受煎熬,满怀期望的各种思路与尝试都被冰冷的现实无情的击碎了,当时间在流逝而一筹莫展的时候,乐观的心态、坚持到底的毅力非常非常宝贵。竞赛是这样,其他很多事情其实也是如此。
另外一个体会是一定要让思路保持活跃和开阔,经常试着用不同的视角观察数据和问题,往往就能找到希望的突破口。
最后鸣谢主办方CIKM、百度、SIGIR精心举办的这次活动,让大家有一个很好切磋技艺的机会。在竞赛期间,和团队的伙伴们一起拼搏、努力、学习、成长的过程,是我最开心和难忘的事情!(文:盛大文学首席数据官 陈运文)


http://credit-n.ru/zaymyi-next.html
感谢分享,好文。祝贺!
[回复]
送上祝福,恭喜恭喜!!!很赞同“坚持到底不轻易放弃”这句话,也要以此来勉励我自己!
[回复]
“用于L2层的训练的样本必须没有在训练L1层时使用过”,是为了防止过拟合吗?
[回复]
miyanguangdajie 回复:
22 11 月, 2014 at 16:39
因为如果训练L2层的样本和训练L1层的样本有重合的话,说明在L1阶段训练和测试的时候,这部分重合的样本都被使用了
[回复]
Step4:使用全部训练样本(Tain pig + Test)重新训练L1层模型
这块貌似写错了,应该是
Step4:使用全部训练样本(Tain pig + Test pig)重新训练L1层模型
楼主写得比较系统,各个角度基本都涉及到了。
ensemble看来还是各类CUP的大杀器呀。哈哈
[回复]
好文顶
[回复]
想问一下,您处理这样大的数据是使用的什么平台呢?是百度的开发平台还是什么呢?
[回复]
陈运文 回复:
9 12 月, 2014 at 22:53
是自己开发的系统,evaluation是用百度开放平台
[回复]
hi,陈老师
方便把分享的ppt发我一份吗,xpjandy@qq.com
[回复]
不错,对目前的工作很有启发,TKS!
[回复]
感觉很受启发,不过有两个地方没太看明白,想咨询一下。1、进到L2 的simple feature是指什么呢?是从L1层用到的所有feature里挑出的子集么?(简单的feature)。2、在这里ensemble learning的思想是近似于bagging的做法么? 谢谢!
[回复]
太精彩了啊~~~~
[回复]
当前工作卡住了Orz..
想问下大大,Query的首尾字是怎么作为特征使用啊..
[回复]
有没有相关的paper可以参考一下的?
[回复]
做预测的时候L1层和L2 层是如何ensemble 的呢?L2层输入特征必须有L1层预测结果,那这个预测结果是哪里来的呢?
[回复]
请问有开源代码吗
[回复]
感谢分享,思路讲的也很细致,如果有paper就更好了
[回复]
请问是否有讲emsemble框架的paper,想详细看一下
[回复]
大牛您好,我想请教一下,因为最近尝试组合模型,分别用了GBDT,LR,Adaboost做单模型训练,结果在用LR进行二层组合模型训练,但是得到的结果多与GBDT结果接近或者一样,请问是什么原因导致的,又有什么好的解决办法吗?
[回复]
比赛的网站不能访问了,能否分享一下数据?
[回复]
Alan 回复:
18 6 月, 2019 at 17:58
你有数据了吗?能否发给我一份?
[回复]
有数据集吗?
[回复]
有数据集吗?可以发给我一份吗?1244830618@qq.com 谢谢。
[回复]
有数据集吗?能否分享一下?
[回复]
你有数据了吗?能否发给我一份?
[回复]
各位大佬有数据集吗?
[回复]