
五、前向算法(Forward Algorithm)
前向算法定义(Forward algorithm definition)
我们使用前向算法计算T长观察序列的概率:
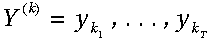
其中y的每一个是观察集合之一。局部(中间)概率(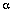 's)是递归计算的,首先通过计算t=1时刻所有状态的局部概率:
's)是递归计算的,首先通过计算t=1时刻所有状态的局部概率:
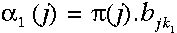
然后在每个时间点,t=2,... ,T时,对于每个状态的局部概率,由下式计算局部概率:
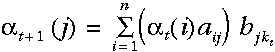
也就是当前状态相应的观察概率与所有到达该状态的路径概率之积,其递归地利用了上一个时间点已经计算好的一些值。
最后,给定HMM,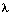 ,观察序列的概率等于T时刻所有局部概率之和:
,观察序列的概率等于T时刻所有局部概率之和:
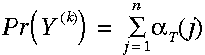
再重复说明一下,每一个局部概率(t > 2 时)都由前一时刻的结果计算得出。
对于“天气”那个例子,下面的图表显示了t = 2为状态为多云时局部概率的计算过程。这是相应的观察概率b与前一时刻的局部概率与状态转移概率a相乘后的总和再求积的结果:
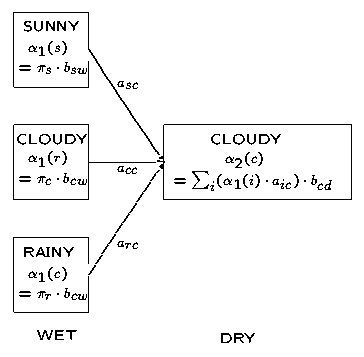
(注:本图及维特比算法4中的相似图存在问题,具体请见文后评论,非常感谢读者YaseenTA的指正)
总结(Summary)
我们使用前向算法来计算给定隐马尔科夫模型(HMM)后的一个观察序列的概率。它在计算中利用递归避免对网格所有路径进行穷举计算。
给定这种算法,可以直接用来确定对于已知的一个观察序列,在一些隐马尔科夫模型(HMMs)中哪一个HMM最好的描述了它——先用前向算法评估每一个(HMM),再选取其中概率最高的一个。
未完待续:前向算法4
本文翻译自:http://www.comp.leeds.ac.uk/roger/HiddenMarkovModels/html_dev/main.html
部分翻译参考:隐马尔科夫模型HMM自学
转载请注明出处“我爱自然语言处理”:www.52nlp.cn
本文链接地址:https://www.52nlp.cn/hmm-learn-best-practices-five-forward-algorithm-3
这个图里面
https://www.52nlp.cn/images/example.forward.gif (原文里面的图)
t=1,Rainy状态那一部分有错误吧?
应该是
α1( r )= πr *brw
就是括号里面(r)还有cw应该是rw
[回复]
52nlp 回复:
5 4 月, 2010 at 22:28
不好意思,这两天出游晚上刚回来。
应该是你所写的这个公式,我摘录的原文公式,没有仔细看,谢谢。
[回复]
YaseenTA 回复:
6 4 月, 2010 at 13:00
还有一个地方 Cloudy 应该是α1( c )= 而不是 α1( r )=
同样这些错误也在https://www.52nlp.cn/images/example.viterbi.gif
[回复]
52nlp 回复:
6 4 月, 2010 at 18:55
非常感谢,已在相关图下做了注明!
您好,我想问一下,计算t+1时刻的局部概率时,最后的混淆矩阵为什么是bjkt,我觉得应该是bjkt+1吧?呵呵,谢谢了
[回复]
52nlp 回复:
19 11 月, 2010 at 21:34
谢谢指正,这个应该是bjkt+1,抱歉,摘录原图时没注意,关于HMM,建议看一下论文:Lawrence R. Rabiner (February 1989). "A tutorial on Hidden Markov Models and selected applications in speech recognition",这个比较经典。
[回复]
博主您好有个问题没明白
https://www.52nlp.cn/images/example.forward.gif
这张图里的wet状态是哪里来的
前面的混淆矩阵b里面只有4个状态 dry dryish damp soggy,而没有wet
难道wet = damp + soggy?
[回复]
谢谢,我也没注意有这样的变化,不过这个不影响前向算法的说明。
[回复]
“最后,给定HMM,,观察序列的概率等于T时刻所有局部概率之和:”后面那个式子我没看明白, 这样看起来最后计算的结果和观察序列一点关系都没有啊...
[回复]
夕阳武士 回复:
11 6 月, 2012 at 15:56
我一开始和你疑问一样,仔细一想和观察序列还是有关系的,因为在T之前每一时刻都使用了混淆矩阵计算,而选择混淆矩阵中具体的值的选择就是根据观察序列选择的,希望能帮到你!
[回复]
NJU_NLP 回复:
11 6 月, 2012 at 19:01
我注意到了,谢谢~
[回复]
第三个公式,计算阿尔法(t+1)j公式里面右边最后一项bjki是否应该是bjkj?
另外关于NJU_NLP的问题不知道自己理解的对不对:是否可以用神经网络的方式理解?
[回复]
minenki 回复:
15 12 月, 2012 at 14:30
我觉得那个地方b下标应该是jk_{t+1}, 上一部分里的公式还有+1,这一部分这个公式就没+1了
[回复]
minenki 回复:
15 12 月, 2012 at 14:34
刚看到,博主已经给出解释了,看楼上candy_636 那里
[回复]
52nlp 回复:
20 12 月, 2012 at 19:15
o(∩_∩)o
[回复]
能否说明一下T长观察序列的数学符号Y(k),这个k是什么意思?k还可以有下标1~T,然后混淆矩阵b也带有k和它的下标,这是说在不同时刻t有不同的混淆矩阵吗?
[回复]
t=2时刻的隐藏状态的概率和t=1时刻的观察的序列这个要算概率吗?
如果要算是需要根据贝叶斯来算吧。
[回复]
然后在每个时间点,t=2,... ,T时,对于每个状态的局部概率,由下式计算局部概率alpha:下面的公式有点问题吧?最后的 b j kt,应该是b j k t+1 吧?谢谢
[回复]
推导了半夜这个公式,越推导越糊涂
认为文章里有些概念混乱了 ,隐藏状态的局部概率和
隐藏状态的局部概率的计算和观察状态的局部概率并没有关系,
o1o2o3...on观察序列的概率,应该是P(o1)*P(o2)*...*P(on)。。。
我有点糊涂了。。。
[回复]
52nlp 回复:
4 6 月, 2019 at 08:18
找本经典书去读吧,这个系列翻译于10年前,原文链接现在已经无法访问,看看有没有机会重新review一下。
[回复]
李怀仁 回复:
5 6 月, 2019 at 20:34
谢谢 ,昨天推导了半夜,理解了你们的思路,我用的是另外一种思路。英文原版的不太好找。此外,向您致上谢意,五年前保研时,第一次看见这篇文章,打开了我的眼界。让我发现计算机更宽广的世界
[回复]
52nlp 回复:
5 6 月, 2019 at 22:53
谢谢