
四、隐马尔科夫模型(Hidden Markov Models)
1、定义(Definition of a hidden Markov model)
一个隐马尔科夫模型是一个三元组(
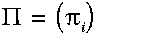 :初始化概率向量;
:初始化概率向量;
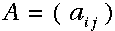 :状态转移矩阵;
:状态转移矩阵;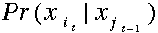
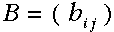 :混淆矩阵;
:混淆矩阵;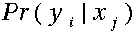
在状态转移矩阵及混淆矩阵中的每一个概率都是时间无关的——也就是说,当系统演化时这些矩阵并不随时间改变。实际上,这是马尔科夫模型关于真实世界最不现实的一个假设。
2、应用(Uses associated with HMMs)
一旦一个系统可以作为HMM被描述,就可以用来解决三个基本问题。其中前两个是模式识别的问题:给定HMM求一个观察序列的概率(评估);搜索最有可能生成一个观察序列的隐藏状态序列(解码)。第三个问题是给定观察序列生成一个HMM(学习)。
a) 评估(Evaluation)
考虑这样的问题,我们有一些描述不同系统的隐马尔科夫模型(也就是一些(
我们使用前向算法(forward algorithm)来计算给定隐马尔科夫模型(HMM)后的一个观察序列的概率,并因此选择最合适的隐马尔科夫模型(HMM)。
在语音识别中这种类型的问题发生在当一大堆数目的马尔科夫模型被使用,并且每一个模型都对一个特殊的单词进行建模时。一个观察序列从一个发音单词中形成,并且通过寻找对于此观察序列最有可能的隐马尔科夫模型(HMM)识别这个单词。
b) 解码( Decoding)
给定观察序列搜索最可能的隐藏状态序列。
另一个相关问题,也是最感兴趣的一个,就是搜索生成输出序列的隐藏状态序列。在许多情况下我们对于模型中的隐藏状态更感兴趣,因为它们代表了一些更有价值的东西,而这些东西通常不能直接观察到。
考虑海藻和天气这个例子,一个盲人隐士只能感觉到海藻的状态,但是他更想知道天气的情况,天气状态在这里就是隐藏状态。
我们使用Viterbi 算法(Viterbi algorithm)确定(搜索)已知观察序列及HMM下最可能的隐藏状态序列。
Viterbi算法(Viterbi algorithm)的另一广泛应用是自然语言处理中的词性标注。在词性标注中,句子中的单词是观察状态,词性(语法类别)是隐藏状态(注意对于许多单词,如wind,fish拥有不止一个词性)。对于每句话中的单词,通过搜索其最可能的隐藏状态,我们就可以在给定的上下文中找到每个单词最可能的词性标注。
C)学习(Learning)
根据观察序列生成隐马尔科夫模型。
第三个问题,也是与HMM相关的问题中最难的,根据一个观察序列(来自于已知的集合),以及与其有关的一个隐藏状态集,估计一个最合适的隐马尔科夫模型(HMM),也就是确定对已知序列描述的最合适的(
当矩阵A和B不能够直接被(估计)测量时,前向-后向算法(forward-backward algorithm)被用来进行学习(参数估计),这也是实际应用中常见的情况。
3、总结(Summary)
由一个向量和两个矩阵(
1. 对于一个观察序列匹配最可能的系统——评估,使用前向算法(forward algorithm)解决;
2. 对于已生成的一个观察序列,确定最可能的隐藏状态序列——解码,使用Viterbi 算法(Viterbi algorithm)解决;
3. 对于已生成的观察序列,决定最可能的模型参数——学习,使用前向-后向算法(forward-backward algorithm)解决。
未完待续:前向算法1
本文翻译自:http://www.comp.leeds.ac.uk/roger/HiddenMarkovModels/html_dev/main.html
部分翻译参考:隐马尔科夫模型HMM自学
转载请注明出处“我爱自然语言处理”:www.52nlp.cn
本文链接地址:https://www.52nlp.cn/hmm-learn-best-practices-four-hidden-markov-models
期待你把这个系列早日翻译完成。希望博主可以通过我的邮箱加我的MSN。
[回复]
谢谢崔师兄的关注!
[回复]
谢谢博主的无私奉献,今天看到您的网站,我真是如获珍宝。我现在研一,在ustc学习语言识别。我会经常来这里学习的哈。我的msn:xuyong.ustc@hotmail.com,希望能家博主。
[回复]
52nlp 回复:
6 11 月, 2010 at 20:19
谢谢,欢迎常来,你可以直接加我的MSN: 52nlpcn#gmail.com,不过我上的不多。
[回复]
Dashun Wang 回复:
23 11 月, 2014 at 07:05
same ustcer~
[回复]
HHS 回复:
10 12 月, 2014 at 21:04
同USTC
[回复]
lz你好,貌似有个小小的地方写错了,“一旦一个系统可以作为HMM被描述,就可以用来解决三个基本问题。其中前两个是模式识别的问题:给定HMM求一个观察序列的概率(评估);搜索最有可能生成一个观察序列的隐藏状态训练(解码)。第三个问题是给定观察序列生成一个HMM(学习)。”的那个“训练”应该是“序列”吧。呵呵
[回复]
52nlp 回复:
19 3 月, 2011 at 23:38
非常感谢,已修改!
[回复]
最上面求概率的两个式子怎么感觉行列弄颠倒了,是不是应该是aij=p(yjt|xit-1)
bij=p(yi|xi)
[回复]
honghe 回复:
8 1 月, 2013 at 11:24
同感
[回复]
wen73 回复:
15 3 月, 2015 at 16:23
同感啊
[回复]
假设我要对3D的高斯分布的信号进行连续的HMM训练,那么高斯信号是否可以模型化为12维的观察向量呢?也就是3D高斯分布的均值向量和方差矩阵组成一个12维的观察向量。或者有其它更好的方式来模型化高斯信号使其更适合于HMM的训练呢
[回复]
非常感谢博主,博主是一个人在写这个博客吗?里面的文章很好,我今年研一,研究方向是数据挖掘,近期在你这里学到很多,谢谢。
[回复]
之前看HMM和MM的解释一直不清楚如何应用,这里看到博主的说法就醒悟了
[回复]