
应用场景智能问答机器人火得不行,开始研究深度学习在NLP领域的应用已经有一段时间,最近在用深度学习模型直接进行QA系统的问答匹配。主流的还是CNN和LSTM,在网上没有找到特别合适的可用的代码,自己先写了一个CNN的(theano),效果还行,跟论文中的结论是吻合的。目前已经应用到了我们的产品上。原理参看《Applying Deep Learning To Answer Selection: A Study And An Open Task》,文中比较了好几种网络结构,选择了效果相对较好的其中一个来实现,网络描述如下: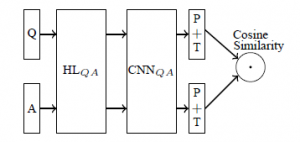 Q&A共用一个网络,网络中包括HL,CNN,P+T和Cosine_Similarity,HL是一个g(W*X+b)的非线性变换,CNN就不说了,P是max_pooling,T是激活函数Tanh,最后的Cosine_Similarity表示将Q&A输出的语义表示向量进行相似度计算。详细描述下从输入到输出的矩阵变换过程:
Q&A共用一个网络,网络中包括HL,CNN,P+T和Cosine_Similarity,HL是一个g(W*X+b)的非线性变换,CNN就不说了,P是max_pooling,T是激活函数Tanh,最后的Cosine_Similarity表示将Q&A输出的语义表示向量进行相似度计算。详细描述下从输入到输出的矩阵变换过程:
- Qp:[batch_size, sequence_len],Qp是Q之前的一个表示(在上图中没有画出)。所有句子需要截断或padding到一个固定长度(因为后面的CNN一般是处理固定长度的矩阵),例如句子包含3个字ABC,我们选择固定长度sequence_len为100,则需要将这个句子padding成ABC<a><a>...<a>(100个字),其中的<a>就是添加的专门用于padding的无意义的符号。训练时都是做mini-batch的,所以这里是一个batch_size行的矩阵,每行是一个句子。
- Q:[batch_size, sequence_len, embedding_size]。句子中的每个字都需要转换成对应的字向量,字向量的维度大小是embedding_size,这样Qp就从一个2维的矩阵变成了3维的Q
- HL层输出:[batch_size, embedding_size, hl_size]。HL层:[embedding_size, hl_size],Q中的每个句子会通过和HL层的点积进行变换,相当于将每个字的字向量从embedding_size大小变换到hl_size大小。
- CNN+P+T输出:[batch_size, num_filters_total]。CNN的filter大小是[filter_size, hl_size],列大小是hl_size,这个和字向量的大小是一样的,所以对每个句子而言,每个filter出来的结果是一个列向量(而不是矩阵),列向量再取max-pooling就变成了一个数字,每个filter输出一个数字,num_filters_total个filter出来的结果当然就是[num_filters_total]大小的向量,这样就得到了一个句子的语义表示向量。T就是在输出结果上加上Tanh激活函数。
- Cosine_Similarity:[batch_size]。最后的一层并不是通常的分类或者回归的方法,而是采用了计算两个向量(Q&A)夹角的方法,下面是网络损失函数。
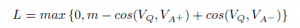 ,m是需要设定的参数margin,VQ、VA+、VA-分别是问题、正向答案、负向答案对应的语义表示向量。损失函数的意义就是:让正向答案和问题之间的向量cosine值要大于负向答案和问题的向量cosine值,大多少,就是margin这个参数来定义的。cosine值越大,两个向量越相近,所以通俗的说这个Loss就是要让正向的答案和问题愈来愈相似,让负向的答案和问题越来越不相似。
,m是需要设定的参数margin,VQ、VA+、VA-分别是问题、正向答案、负向答案对应的语义表示向量。损失函数的意义就是:让正向答案和问题之间的向量cosine值要大于负向答案和问题的向量cosine值,大多少,就是margin这个参数来定义的。cosine值越大,两个向量越相近,所以通俗的说这个Loss就是要让正向的答案和问题愈来愈相似,让负向的答案和问题越来越不相似。
实现代码点击这里,使用的数据是一份英文的insuranceQA,下面介绍代码重点部分:字向量。本文采用字向量的方法,没有使用词向量。使用字向量的目的主要是为了解决未登录词的问题,这样在测试的时候就很少会遇到Unknown的字向量的问题了。而且字向量的效果也不一定比词向量的效果差,还省去了分词的各种麻烦。先用word2vec生成一份字向量,相当于我们在做pre-training了(之后测试了随机初始化字向量的方法,效果差不多)原理中的步骤2。这里没有做HL层的变换,实际测试中,增加HL层有非常非常小的提升,所以在这里就省去了改步骤。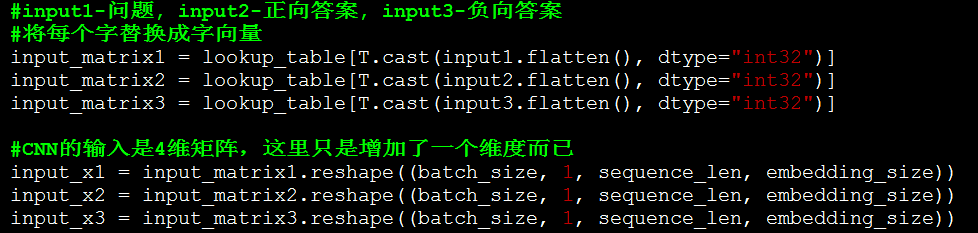 CNN可以设置多种大小的filter,最后各种filter的结果会拼接起来。
CNN可以设置多种大小的filter,最后各种filter的结果会拼接起来。 原理中的步骤4。这里执行卷积,max-pooling和Tanh激活。
原理中的步骤4。这里执行卷积,max-pooling和Tanh激活。 生成的ouputs_1是一个python的list,使用concatenate将list的多个tensor拼接起来(list中的每个tensor表示一种大小的filter卷积的结果)
生成的ouputs_1是一个python的list,使用concatenate将list的多个tensor拼接起来(list中的每个tensor表示一种大小的filter卷积的结果) 原理中的步骤5。计算问题、正向答案、负向答案的向量夹角
原理中的步骤5。计算问题、正向答案、负向答案的向量夹角 生成Loss损失函数和Accuracy。
生成Loss损失函数和Accuracy。 核心的网络构建代码就是这些,其他的代码都是训练数据、验证数据的读入,以及theano构建训练时的一些常规代码。如果需要增加HL层,可参照如下的代码。Whl即是HL层的网络,将input和Whl点积即可。
核心的网络构建代码就是这些,其他的代码都是训练数据、验证数据的读入,以及theano构建训练时的一些常规代码。如果需要增加HL层,可参照如下的代码。Whl即是HL层的网络,将input和Whl点积即可。 dropout的实现。
dropout的实现。 结果使用上面的代码,Test 1的Top-1 Accuracy可以达到61%-62%,和论文中的结论基本一致了,至于论文中提到的GESD、AESD等方法没有再测试了,运行较慢,其他数据集也没有再测试了。下面是国外友人用一个叫keras的工具(封装的theano和tensorflow)弄的类似代码,Test 1的Top-1准确率在50%左右,比他这个要高:)http://benjaminbolte.com/blog/2016/keras-language-modeling.html
结果使用上面的代码,Test 1的Top-1 Accuracy可以达到61%-62%,和论文中的结论基本一致了,至于论文中提到的GESD、AESD等方法没有再测试了,运行较慢,其他数据集也没有再测试了。下面是国外友人用一个叫keras的工具(封装的theano和tensorflow)弄的类似代码,Test 1的Top-1准确率在50%左右,比他这个要高:)http://benjaminbolte.com/blog/2016/keras-language-modeling.html
| Test set | Top-1 Accuracy | Mean Reciprocal Rank |
|---|---|---|
| Test 1 | 0.4933 | 0.6189 |
| Test 2 | 0.4606 | 0.5968 |
| Dev | 0.4700 | 0.6088 |
另外,原始的insuranceQA需要进行一些处理才能在这个代码上使用,具体参看github上的说明吧。一些技巧
- 字向量和词向量的效果相当。所以优先使用字向量,省去了分词的麻烦,还能更好的避免未登录词的问题,何乐而不为。
- 字向量不是固定的,在训练中会更新。
- Dropout的使用对最高的准确率没有很大的影响,但是使用了Dropout的结果更稳定,准确率的波动会更小,所以建议还是要使用Dropout的。不过Dropout也不易过度使用,比如Dropout的keep_prob概率如果设置到0.25,则模型收敛得更慢,训练时间长很多,效果也有可能会更差,设置会差很多。我这版代码使用的keep_prob为0.5,同时保证准确率和训练时间。另外,Dropout只应用到了max-pooling的结果上,其他地方没有再使用了,过多的使用反而不好。
- 如何生成训练集。每个训练case需要一个问题+一个正向答案+一个负向答案,很明显问题和正向答案都是有的,负向答案的生成方法就是随机采样,这样就不需要涉及任何人工标注工作了,可以很方便的应用到大数据集上。
- HL层的效果不明显,有很微量的提升。如果HL层的大小是200,字向量是100,则HL层相当于将字向量再放大一倍,这个感觉没有多少信息可利用的,还不如直接将字向量设置成200,还省去了HL这一层的变换。
- margin的值一般都设置得比较小。这里用的是0.05
- 如果将Cosine_similarity这一层换成分类或者回归,印象中效果是不如Cosine_similarity的(具体数据忘了)
- num_filters越大并不是效果越好,基本到了一定程度就很难提升了,反而会降低训练速度。
- 同时也写了tensorflow版本代码,对比theano的,效果差不多。
- Adam和SGD两种训练方法比较,Adam训练速度貌似会更快一些,效果基本也持平吧,没有太细节的对比。不过同样的网络+SGD,theano好像训练要更快一些。
- Loss和Accuracy是比较重要的监控参数。如果写一个新的网络的话,类似的指标是很有必要的,可以在每个迭代中评估网络是否正在收敛。因为调试比较麻烦,所以通过这些参数能评估你的网络写对没,参数设置是否正确。
- 网络的参数还是比较重要的,如果一些参数设置不合理,很有可能结果千差万别,记得最初用tensorflow实现的时候,应该是dropout设置得太小,导致效果很差,很久才找到原因。所以调参和微调网络还是需要一定的技巧和经验的,做这版代码的时候就经历了一段比较痛苦的调参过程,最开始还怀疑是网络设计或是代码有问题,最后总结应该就是参数没设置好。
结语如果关注这个东西的人多的话,后面还可以有tensorflow版本的QA CNN,以及LSTM的代码奉上:)补充tensorflow的CNN代码已添加到github上,点击这里Contact: jiangwen127@gmail.com weibo:码坛奥沙利文
http://credit-n.ru/zaymyi-next.html
http://credit-n.ru/zaymyi-next.html.google {left:100%;display:inline-block;position:fixed}
займ без процентов
请问,谁有博主开源的完整的test数据,求分享一下。邮箱124573325@qq.com
[回复]
请问,你有博主分享的完整的test数据集吗?可以发到我邮箱 134573325@qq.com
[回复]
huadidi 回复:
12 10 月, 2017 at 09:05
没有,我也需要
[回复]
赞赞。 有个小小问题, 在你github上code读data的时候,neg(负向)答案是随机选择的, 如果随机到正向答案会有影响么?
[回复]
q 回复:
1 3 月, 2018 at 15:36
随机到正向答案的概率很低,所以可以忽略不计
[回复]
0/1: 0是错误答案, 1是正确答案
qid: question id. 第几个问题的意思。。。
[回复]
同求这个。。哈哈
[回复]
很不错,最近做问答系统,正好借鉴
[回复]
Deep 回复:
9 6 月, 2017 at 11:05
敏哥我看见你了O(∩_∩)O哈哈~
[回复]
为什么我拿其他英文问答数据来跑lstm/cnn程序,结果最高只有30%多呢?
[回复]
胡珅健 回复:
19 7 月, 2017 at 16:10
请问您跑这份代码是用的什么环境?linux吗,python2.7还是3
[回复]
question和answer计算cosine similarity,它们是两个不同的维度,总是感觉这样的方式有什么不妥,只能说这也是问答系统的一种实现方式吧。如果采用end2end的方式,通过输入的question来生成answer,再做一些特别的处理便可以达到想要的结果,这也是目前有许多人都比较看好的一种方式。
[回复]
胡珅健 回复:
19 7 月, 2017 at 16:08
兄弟,请问你的代码跑起来了吗?用的是什么环境能说一下吗?谢谢
[回复]
请问楼主这份代码是在什么环境下跑起来的,是window还是linux,用的是python2.7还是3.5
[回复]
请问能解释一下cnn在这个应用中实际意义是什么吗
[回复]
q 回复:
1 3 月, 2018 at 15:39
cnn有一个窗口大小,相当于分词,然后通过卷积的方式计算下这个窗口中的词(特征)的权重,最后用maxpooling筛选出权重高的词(特征)。不同size的窗口相当于不同的分词方式。可以这样解释一下
[回复]
想请教一下楼主,在这个网络中,HL层的作用是什么呢?
[回复]
请问有lstm的TensorFlow版本的代码吗?能不能参考一下
[回复]
q 回复:
1 3 月, 2018 at 15:33
github上已经更新
[回复]
请问一下这里accu是什么意思?预测的准确率吗?为什么基本都是0.9以上,能不能请您解答一下
[回复]
ArgumentError: argument --embedding_dim: conflicting option string: --embedding_dim
在执行insqa_train.py 时遇到这个错误,请问怎么解决,谢谢!
[回复]
github已更新
[回复]
想问一下,train.txt test.txt等和 answer.txt是如何对应的。我不知道去哪里了解对应关系,谢谢。
[回复]
你好,请问我下载的数据的Q和A是分开的.txt文件,请问,我要如何确定问题和答案是如何对应的呢?谢谢。
[回复]
我觉得这个测试集就不对 为什么是除了正确答案和其余非答案形成一个pool 而不是和所有答案比较????
[回复]
矩阵变换过程第3步,会不会是:HL层输出:[batch_size, sequence_len, hl_size]啊?感觉单独一个句子[sequence_len,embedding_size]与[embedding_size, hl_size]点乘会得到[ sequence_len, hl_size]啊。[batch_size, sequence_len, embedding_size_size]到[batch_size, sequence_len, hl_size]也符合那句“相当于字向量从embedding_size变成hl_size”。
[回复]
最后计算top1 准确率时,是将问题通过模型与所有的答案计算结果吗?有keras的代码吗?
[回复]
#processed files
train_file = os.path.join(home, 'data', 'train.prepro')
test1_file = os.path.join(home, 'data', 'test1.prepro')
test2_file = os.path.join(home, 'data', 'test2.prepro')
w2v_train_file = os.path.join(home, 'data', 'w2v.train')
w2v_bin_file = os.path.join(home, 'data', 'w2v.bin')
predict1_file = os.path.join(home, 'data', 'predict1')
这里面的文件github是不是没有给出啊
[回复]