
斯坦福大学机器学习斯坦福大学机器学习第十一课“机器学习系统设计(Machine learning system design)””学习笔记,本次课程主要包括5部分:
1) Prioritizing what to work on: Spam classification example(工作的优先级:垃圾邮件分类例子)
2) Error analysis(错误分析)
3) Error metrics for skewed classes(不对称性分类的错误评估)
4) Trading off precision and recall(精确度和召回率的权衡)
5) Data for machine learning(数据对于机器学习的重要性)
以下是每一部分的详细解读。
1) Prioritizing what to work on: Spam classification example(工作的优先级:垃圾邮件分类例子)
首先让我们来看一下垃圾邮件和非垃圾邮件的例子,以下是一个垃圾邮件示例:
我们将其标注为“垃圾(spam)", 用1表示;以下是一个非垃圾邮件的例子:
我们将其标注为“非垃圾(non-spam)",用0表示。
如果我们有一些这样标注好的垃圾和非垃圾邮件样本,如何来训练一个垃圾邮件分类器?很清楚这是一个有监督学习的问题,假设我们选择逻辑回归算法来训练这样的分类器,首先必须选择合适的特征。这里定义:
x = 邮件的特征;
y = 垃圾邮件(1) 或 非垃圾邮件(0)
我们可以选择100个典型的词汇集合来代表垃圾/非垃圾(单词),例如deal, buy, discount, andrew, now等,可以按它们的字母顺序排序。对于已经标注好的邮件训练样本,如果100个词汇中有单词j在样本中出现,就用1代表特征向量x中的xj,否则用0表示,这样训练样本就被特征向量x所替代:
注意在实际使用中,我们不会手动去选择100个典型的词汇,而是从训练集中选择出现频率最高的前n个词,例如10000到50000个。
那么,如何高效的训练一个垃圾邮件分类器使其准确率较高,错误率较小?
- 首先很自然的考虑到收集较多的数据,例如"honeypot" project,一个专门收集垃圾邮件服务器ip和垃圾邮件内容的项目;
- 但是上一章已经告诉我们,数据并不是越多越好,所以可以考虑设计其他复杂的特征,例如利用邮件的发送信息,这通常隐藏在垃圾邮件的顶部;
- 还可以考虑设计基于邮件主体的特征,例如是否将"discount"和"discounts"看作是同一个词?同理如何处理"deal"和"Dealer"? 还有是否将标点作为特征?
- 最后可以考虑使用复杂的算法来侦测错误的拼写(垃圾邮件会故意将单词拼写错误以逃避垃圾邮件过滤器,例如m0rtgage, med1cine, w4tches)
2) Error analysis(错误分析)
在我们需要机器学习算法来解决一些实际问题时,建议:
- - 从一个简单的算法入手这样可以很快的实现这个算法,并且可以在交叉验证集上进行测试;
- - 画学习曲线以决定是否更多的数据,更多的特征或者其他方式会有所帮助;
- - 错误分析:人工检查那些算法预测错误的例子(在交叉验证集上),看看能否找到一些产生错误的原因。
假设交叉验证集上有500个邮件样本,其中算法错分了100个邮件,那么我们就人工来检查这100个bad case, 并且按如下的方式对它们进行分类:
- (i) 邮件是什么类型的?
- (ii) 什么样的线索或特征你认为有可能对算法的正确分类有帮助?
数值评估的重要性:
在对bad case进行分析后,我们可能会考虑如下的方法:
- 对于discount/discounts/discounted/discounting 能否将它们看作是同一个词?
- 能不能使用“词干化”的工具包来取单词的词干,例如“Porter stemmer"?
错误分析不能决定上述方法是否有效,它只是提供了一种解决问题的思路和参考,只有在实际的尝试后才能看出这些方法是否有效。
所以我们需要对算法进行数值评估(例如交叉验证集误差),来看看使用或不使用某种方法时的算法效果,例如:
- 不对单词提前词干:5%错误率 vs 对单词提取词干:3% 错误率
- 对大小写进行区分(Mom / mom): 3.2% 错误率
3) Error metrics for skewed classes(不对称性分类的错误评估)
什么是不对称性分类?
以癌症预测或者分类为例,我们训练了一个逻辑回归模型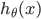 . 如果是癌症,y = 1, 其他则 y = 0。
. 如果是癌症,y = 1, 其他则 y = 0。
在测试集上发现这个模型的错误率仅为1%(99%都分正确了),貌似是一个非常好的结果?
但事实上,仅有0.5%的病人得了癌症,如果我们不用任何学习算法,对于测试集中的所有人都预测y = 0,既没有癌症:
那么这个预测方法的错误率仅为0.5%,比我们废好大力训练的逻辑回归模型的还要好。这就是一个不对称分类的例子,对于这样的例子,仅仅考虑错误率是有风险的。
现在我们就来考虑一种标准的衡量方法:Precision/Recall(精确度和召回率)
首先对正例和负例做如下的定义:
其中:
True Positive (真正例, TP)被模型预测为正的正样本;可以称作判断为真的正确率
True Negative(真负例 , TN)被模型预测为负的负样本 ;可以称作判断为假的正确率
False Positive (假正例, FP)被模型预测为正的负样本;可以称作误报率
False Negative(假负例 , FN)被模型预测为负的正样本;可以称作漏报率
那么对于癌症预测这个例子我们可以定义:
Precision-预测中实际得癌症的病人数量(真正例)除以我们预测的得癌症的病人数量:
Recall-预测中实际得癌症的病人数量(真正例)除以实际得癌症的病人数量:
4) Trading off precision and recall(精确度和召回率的权衡)
假设我们的分类器使用了逻辑回归模型,预测值在0到1之间: , 一种通常的判断正负例的方法是设置一个阈值,例如0.5:
, 一种通常的判断正负例的方法是设置一个阈值,例如0.5:
- 如果
 ,则预测为1, 正例;
,则预测为1, 正例; - 如果
 , 则预测为0, 负例;
, 则预测为0, 负例;
这个时候,我们就可以计算这个分类器的precision and recall(精确度和召回率):
这个时候,不同的阈值回导致不同的精确度和召回率,那么如何来权衡这二值?对于癌症预测这个例子:
假设我们非常有把握时才预测病人得癌症(y=1), 这个时候,我们常常将阈值设置的很高,这会导致高精确度,低召回率(Higher precision, lower recall);
假设我们不希望将太多的癌症例子错分(避免假负例,本身得了癌症,确被分类为没有得癌症), 这个时候,阈值就可以设置的低一些,这又会导致高召回率,低精确度(Higher recall, lower precision);
这些问题,可以归结到一张Precision Recall曲线,简称PR-Curve:
那么如何来比较不同的Precison/Recall值呢?例如,对于下表:
通常我们会考虑用它们的均值来做比较,但是这会引入一个问题,例如上面三组Precision/Recall的均值分别是:0.45, 0.4, 0.51,最后一组最好,但是最后一组真的好吗?如果我们将阈值定的很低,甚至为0, 那么对于所有的测试集,我们的预测都是y = 1, 那么recall 就是1.0,我们根本就不需要什么复杂的机器学习算法,直接预测y = 1就得了,所以,用Precison/Recall的均值不是一个好办法。
现在我们引入标准的F值或者F1-score:
F值是对精确度和召回率的一个很好的权衡,两种极端的情况也能很好的平衡:
5) Data for machine learning(数据对于机器学习的重要性)
在设计一个高准确率的机器学习系统时,数据具有多大的意义? 2001年的时候,Banko and Brill曾做了一个实验,对易混淆的单词进行分类,也就是在一个句子的上下文环境中选择一个合适的单词,例如:
For breakfast I ate ___ eggs
给定{to, two, too},选择一个合适的单词。
他们用了如下几种机器学习算法:
- -Perceptron(Logistic regression)
- -Winnow
- -Memory-based
- -Naïve Bayes
根据训练集的不同规模记录这几种算法的准确率,并且做了如下的图:
最终得到的结论是:
“It's not who has the best algorithm that wins. It's who has the most data."
选择大数据的理由?
假设我们的特征 有很多的信息来准确的预测y, 例如,上面的易混淆词分类的例子,它有整个句子的上下文可以利用;
有很多的信息来准确的预测y, 例如,上面的易混淆词分类的例子,它有整个句子的上下文可以利用;
反过来,例如预测房价的时候,如果仅有房屋大小这个特征,没有其他的特征,能预测准确吗?
对于这样的问题,一种简单的测试方法是给定这样的特征,一个人类专家能否准确的预测出y?
如果一个学习算法有很多的参数,例如逻辑回归/线性回归有很多的特征,神经网络有很多隐藏的单元,那么它的训练集误差将会很小,但容易陷入过拟合;如果再使用很大的训练数据,那么它将很难过拟合,它的训练集误差和测试集误差将会近似相等,并且很小。所以大数据对于机器学习还是非常重要的。
参考资料:
机器学习视频可以在Coursera机器学习课程上观看或下载: https://class.coursera.org/ml
http://en.wikipedia.org/wiki/Precision_and_recall
http://en.wikipedia.org/wiki/Accuracy_and_precision
召回率 Recall、精确度Precision、准确率Accuracy、虚警、漏警等分类判定指标
True(False) Positives (Negatives)
http://en.wikipedia.org/wiki/F1_score
本系列文章来自我在52opencourse上发布的笔记,这里做个备份,转载请注明出处:
http://52opencourse.com/275/coursera%E5%85%AC%E5%BC%80%E8%AF%BE%E7%AC%94%E8%AE%B0-%E6%96%AF%E5%9D%A6%E7%A6%8F%E5%A4%A7%E5%AD%A6%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E7%AC%AC%E5%8D%81%E4%B8%80%E8%AF%BE-%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E7%B3%BB%E7%BB%9F%E8%AE%BE%E8%AE%A1-machine-learning-system-design
请问这个系列是定期退出的吗?我刚刚完成了这一章,不知道有没有下一章的笔记?谢谢!
[回复]
52nlp 回复:
30 11 月, 2015 at 22:13
很遗憾,当时的笔记就做到了这里,可以google一下,之后也有其他同学做了完整的笔记。
[回复]