
内容来源:ChatGPT 及大模型专题研讨会
分享嘉宾:复旦大教授 邱锡鹏
分享主题:《对话式大型语言模型》
转载自CSDN稿件
ChapGPT 自问世以来,便展现出了令世人惊艳的对话能力。仅用两个月时间,ChatGPT 月活跃用户就达一亿,是史上用户增速最快的消费应用。对于学术界、工业界、或是其他相关应用来说都是一个非常大的机会和挑战。事实上,ChatGPT 的成功并不是偶然结果,其背后多有创新之处。本文整理于达观数据参与承办的「ChatGPT 及大模型专题研讨会」上,复旦大学邱锡鹏教授带来的《对话式大型语言模型》主题分享,他从大规模预训练语言模型带来的变化、ChatGPT 的关键技术及其局限性等角度深入地介绍了大规模语言模型的相关知识。

邱锡鹏,复旦大学计算机学院教授,MOSS 系统负责人
为什么是大语言模型?
随着算力的不断提升,语言模型已经从最初基于概率预测的模型发展到基于 Transformer 架构的预训练语言模型,并逐步走向大模型的时代。为什么要突出大语言模型或是在前面加个“Large”?更重要的是它的涌现能力。
当模型规模较小时,模型的性能和参数大致符合比例定律,即模型的性能提升和参数增长基本呈线性关系。然而,当 GPT-3/ChatGPT 这种千亿级别的大规模模型被提出后,人们发现其可以打破比例定律,实现模型能力质的飞跃。这些能力也被称为大模型的“涌现能力”(如理解人类指令等)。

上图是多个 NLP 任务随着模型规模扩大的性能变化曲线,可以看到,前期性能和模型规模大致呈线性关系,当模型规模大到一定程度时,任务性能有了明显的突变。
因此,通常以百亿/千亿级参数量作为 LLM 研究的分水岭。除此之外,大规模语言模型基座的可扩展性很强,其能够很容易和外部世界打通,源源不断地接受外部世界的知识更新,进而实现反复自我迭代。因此,大规模语言模型也被看作是实现通用人工智能的希望。
ChatGPT的三个关键技术
目前,很多公司和组织都在跟风 ChatGPT,推出类似的聊天机器人产品。这主要是因为 ChatGPT 的成功,给人们带来了信心,证明了聊天机器人技术的可行性和潜力,让人们看到了聊天机器人在未来的巨大市场和应用前景。
ChatGPT 的三个关键技术为:情景学习、思维链、自然指令学习,接下来将详细介绍一下这三个技术。
- 情景学习(In-context learning)
改变了之前需要把大模型用到下游任务的范式。对于一些 LLM 没有见过的新任务,只需要设计一些任务的语言描述,并给出几个任务实例,作为模型的输入,即可让模型从给定的情景中学习新任务并给出满意的回答结果。这种训练方式能够有效提升模型小样本学习的能力。

情景学习的示例图
可以看到,只需要以自然语言的形式描述两个情感分类任务输入输出的例子,LLM 就能够对新输入数据的情感极性进行判断。例如,做一个电影的评论,给出相应的任务模型,即可输出正面的回答。
- 思维链(Chain-of-Thought,CoT)
对于一些逻辑较为复杂的问题,直接向大规模语言模型提问可能会得到不准确的回答,但是如果以提示的方式在输入中给出有逻辑的解题步骤的示例后再提出问题,大模型就能给出正确题解。也就是说将复杂问题拆解为多个子问题解决再从中抽取答案,就可以得到正确的答案。
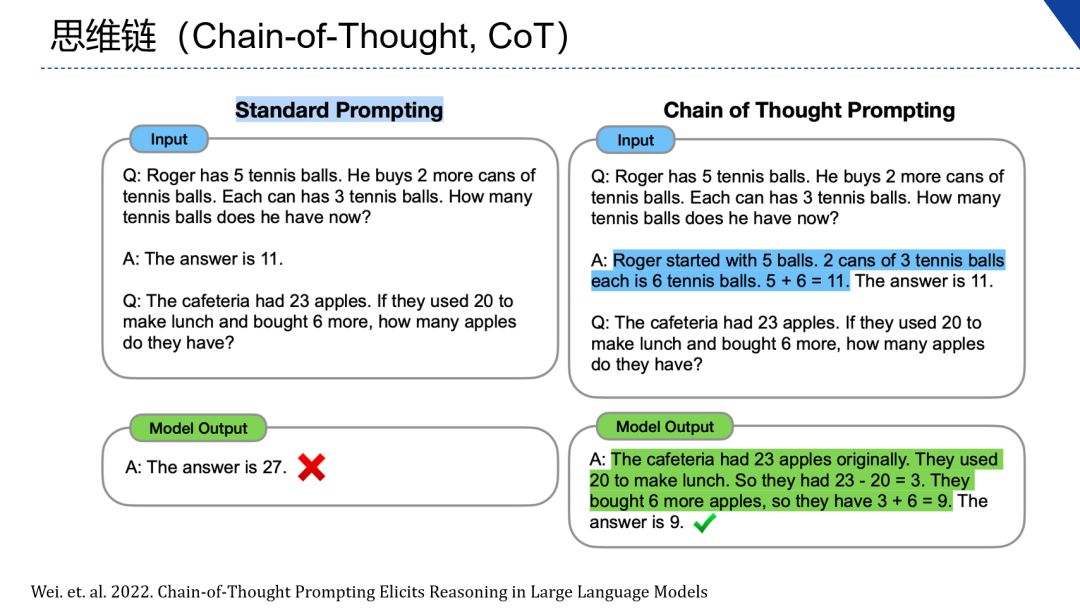
思维链示意图
如思维链示意图所示,左边是直接让模型进行数学题的计算会得到错误的结果,而右侧在解题过程加入了一个示例,引入解题过程则可以激发模型的推理能力,从而得到的正确的结果。

这就是一个简单的可以通过计算能力从思维链中分离,有助于大模型完成任务,从而减轻神经网络的负担。
由于 CoT 技术能够激发大规模语言模型对复杂问题的求解能力,该技术也被认为是打破比例定律的关键。
- 自然指令学习(Learning from Natural Instructions)
早期研究人员希望把所有的自然语言处理任务都能够指令化,对每个任务标注数据。这种训练方式就是会在前面添加一个“指令”,该指令能够以自然语言的形式描述任务内容,从而使得大模型根据输入来输出任务期望的答案。该方式将下游任务进一步和自然语言形式对齐,能显著提升模型对未知任务的泛化能力。

自然指令学习示意图
如自然指令学习示意图所示,左边是自然指令的测试场景,人们把 NLP 任务做到 1000 多种,目前最新模型可以做到 2000 多种 NLP 任务,接下来再对 NLP 任务进行分类,比如能力 A、能力 B,大模型指令能力、泛化能力非常强,学到四五十个任务时就可以泛化到上百种任务。但距离真正的 ChatGPT 还有一步,那就是和真实的人类意图对齐,这就是 OpenAI 做的 GPT。
核心逻辑非常简单,一开始时让人写答案,但是成本太高,改成让人来选答案,这样对标注员的能力要求稍微低一点,可以迅速提升迭代和规模。基于打分再训练一个打分器,通过打分器自动评价模型的好坏,然后用强化学习开始迭代,这种方法可以大规模地把数据模型迭代给转起来,这是 OpenAI 做的 Instruct GPT 逻辑,强化学习的人类反馈。
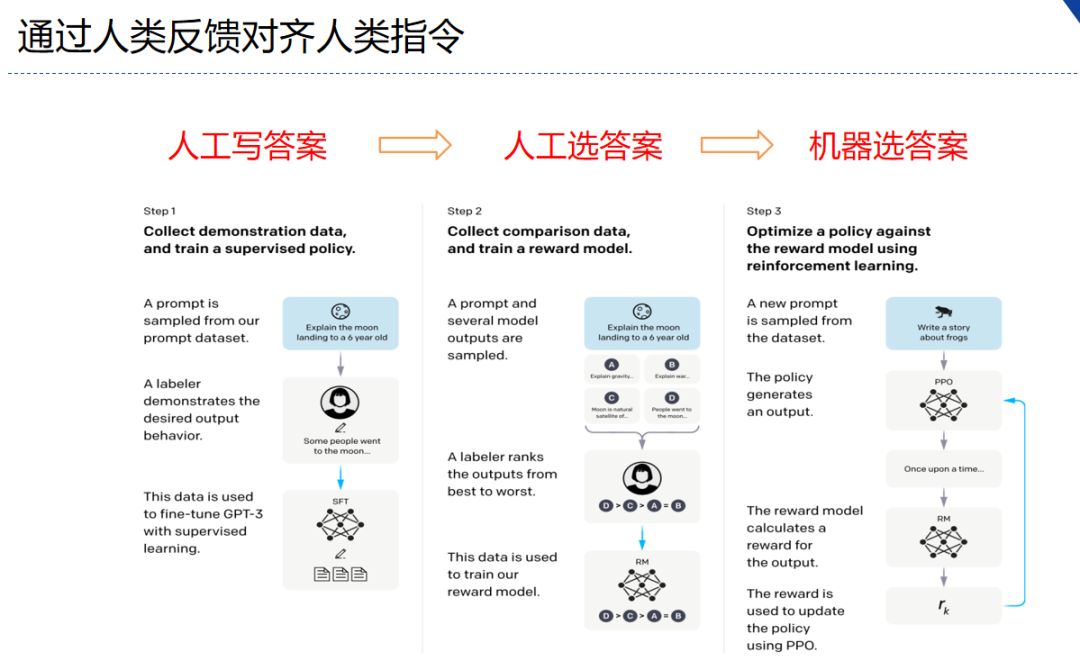
Instruct GPT 逻辑示意图
基于 Instruct GPT 技术路线,ChatGPT 从技术上并没有特别好的创新,但它最伟大之处是赋予了大型语言模型对话的能力,这是个产品化创新,这个创新非常棒!
如何构建一个大语言模型?
目前,主要可以从下面四个维度来衡量大语言模型的能力。
- Know Knowns:LLM 知道它知道的东西。
- Know Unknowns:LLM 知道它不知道哪些东西。
- Unknow Knowns:LLM 不知道它知道的东西。
- Unknow Unknowns:LLM 不知道它不知道的东西。
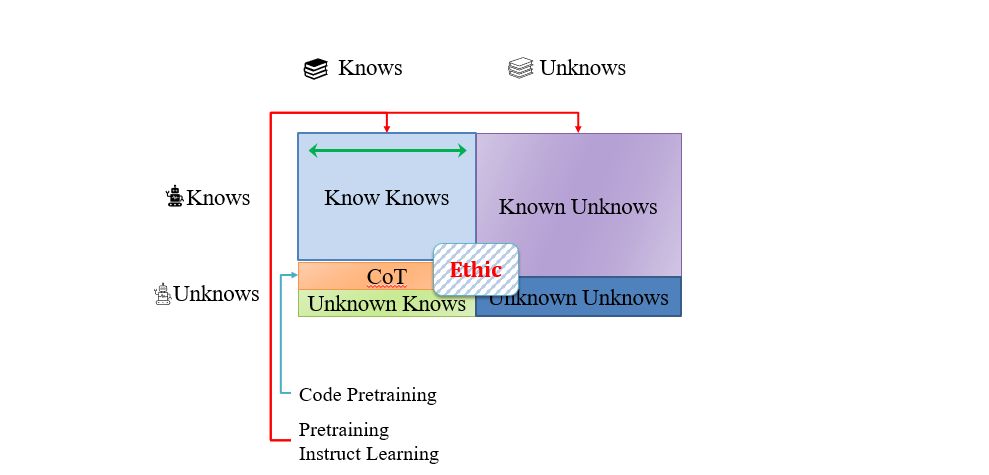
构建对话式大型语言模型
ChatGPT 通过更大规模的预训练,得到了更多的知识,即 Knowns 范围扩大。
另外,ChatGPT 还关注了伦理问题,通过类似解决 Know Unknowns 的方式,利用人工标注和反馈,拒绝回答一些包含伦理问题的请求。
这里,我们也不得不提国内首个对话式大型语言模型 MOSS,从 2 月 21 日发布至公开平台,便引起高度关注。“对话式大型语言模型 MOSS 大概有 200 亿参数。和传统的语言模型不一样,它也是通过与人类的交互能力进行迭代。”邱锡鹏教授在分享中谈到,MOSS 为何会选择 200 亿参数,原因非常简单,它恰好具备涌现能力,与人对话的成本低。
MOSS 是基于公开的中英文数据训练,通过与人类交互能力进行迭代优化。目前 MOSS 收集了几百万真实人类对话数据,也在进一步迭代优化,也具有多轮交互的能力,所以对于指令的理解能力上,通用的语义理解能力上,和ChatGPT 非常类似,任何话它都能接得住,但它的质量没有 ChatGPT 那么好,原因在于模型比较小,知识量不够。
ChatGPT 的局限性
为什么说 ChatGPT 对于学术上来说有一定的重要性,因为它不仅展示了通用人工智能的大框架,更是因为它可以接入多模态信息,增强思考能力、增加输出能力,从而变成更好的通用人工智能底座,可以在学术上带来更多的应用。
相较于 ChatGPT 本身的能力而言,它的局限性相对较少且都比较容易解决。图灵奖得主、人工智能三巨头之一 Yann LeCun 认为 ChatGPT 的缺点有以下几点:
- 目前形式有限。当前的 ChatGPT 仅局限于文本方向,但如前面所说,可以在上游使用一些多模态模型初步解决这个问题。
- 并不可控。目前已有不少报道通过各种方式解锁了模型的 Ethic 和部分 Know Unknowns 限制,但这部分可以通过更多的人工标注和对齐解决。
- 推理能力较差。通过思维链的方式,一定程度上可以增强模型推理能力。
- 无法与现实世界相接触。这也是目前 ChatGPT 最大的问题之一,作为大型语言模型,它无法实时与外部世界互动,也无法利用如计算器,数据库,搜索引擎等外部工具,导致它的知识也相对落后。

而未来它更应该做到提高适时性、即时性、无害等等。
总的来说,如果将 LLM 作为智能体本身,能够与外部交互之后,这些模型的能力一定会有更大的提升。
但我们要始终保证这些 AI 模型的模型可信:有助、无害、诚实。
本文整理自3月11日,由中国人工智能学会主办,国内AI领军企业达观数据携手中国人工智能学会自然语言理解专委会、真格基金共同承办,中国信通院云计算与大数据研究所支持的ChatGPT及大模型专题研讨会。大会围绕ChatGPT和大规模语言模型的发展应用,聚集众多人工智能产研大咖,共同探讨前沿技术及产业未来,呈现了一场精彩的思想交流盛宴。研讨会通过五大平台实时线上转播,共吸引线下线上十余万听众共襄盛举。
搜索关注“达观数据视频号”即刻查看全程直播回放!