
关于中文词法分析(中文分词、词性标注、命名实体识别)相关的工具,我们在之前已经多次提到过百度LAC(https://github.com/baidu/lac),除了在易用性上稍弱外,其他方面,特别是NER在横向对比中还是很亮眼的。最近百度NLP发布了LAC2.0:开源!我知道你不知道,百度开源词法LAC 2.0帮你更懂中文,看完文章的第一感受就是易用性大大加强了,之前需要通过PaddleNLP或者PaddleHub调用lac,现在 "pip install lac" 后即可直接调用,相当方便。所以花了一点时间,把 LAC2.0 单独作为一个接口部署在AINLP公众号的自然语言处理工具测试平台了,感兴趣的同学可以关注AINLP公众号,通过公众号对话测试,输入"LAC 中文文本"直接获取百度LAC的中文文词、词性标注、NER识别结果:

关于百度LAC,首先看一下官方主页的介绍:
LAC全称Lexical Analysis of Chinese,是百度自然语言处理部研发的一款联合的词法分析工具,实现中文分词、词性标注、专名识别等功能。该工具具有以下特点与优势:
效果好:通过深度学习模型联合学习分词、词性标注、专名识别任务,整体效果F1值超过0.91,词性标注F1值超过0.94,专名识别F1值超过0.85,效果业内领先。
效率高:精简模型参数,结合Paddle预测库的性能优化,CPU单线程性能达800QPS,效率业内领先。
可定制:实现简单可控的干预机制,精准匹配用户词典对模型进行干预。词典支持长片段形式,使得干预更为精准。
调用便捷:支持一键安装,同时提供了Python、Java和C++调用接口与调用示例,实现快速调用和集成。
支持移动端: 定制超轻量级模型,体积仅为2M,主流千元手机单线程性能达200QPS,满足大多数移动端应用的需求,同等体积量级效果业内领先。
LAC 2.0 的使用还是很方便的,官方文档很清晰,可以直接参考,以下是在 Ubuntu 16.04, Python 3.6.8 环境下安装测试,这里是在 virtualenv 虚拟环境下通过 pip install lac 安装,安装完成后可以在命令行中直接输入lac进行体验:
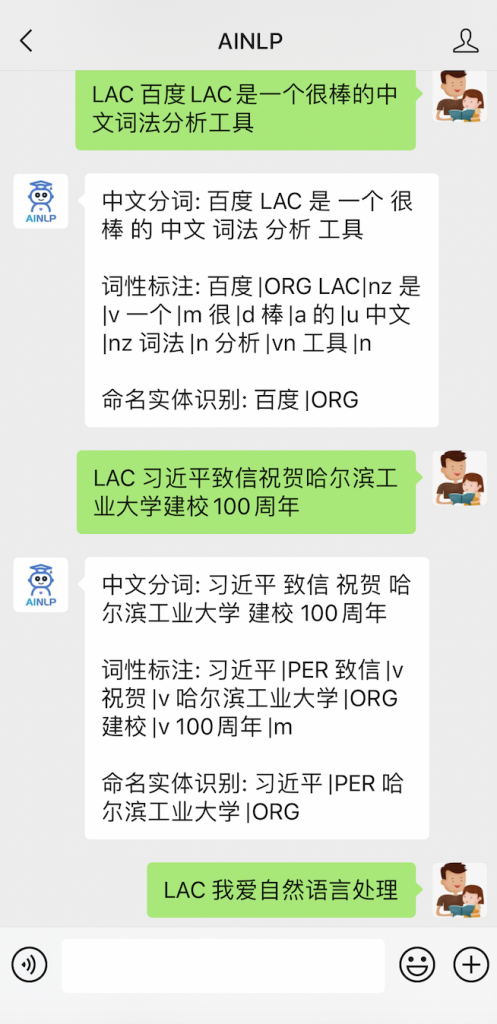
(venv) textminer@textminer:~/nlp_tools/baidu_lac$ lac 我爱自然语言处理 我/r 爱/v 自然语言处理/nz 百度LAC是一个中文词法分析工具 百度/ORG LAC/nz 是/v 一个/m 中文/nz 词法/n 分析/vn 工具/n 习近平致信祝贺哈尔滨工业大学建校100周年 习近平/PER 致信/v 祝贺/v 哈尔滨工业大学/ORG 建校/v 100周年/m 新华社北京6月7日电 中共中央总书记、国家主席、中央军委主席习近平7日致信祝贺哈尔滨工业大学建校100周年,向全校师生员工和校友致以热烈的祝贺和诚挚的问候。 新华社/ORG 北京/LOC 6月7日/TIME 电/n /w /w 中共中央/ORG 总书记/n 、/w 国家主席/n 、/w 中央军委/ORG 主席/n 习近平/PER 7日/TIME 致信/v 祝贺/v 哈尔滨工业大学/ORG 建校/v 100周年/m ,/w 向/p 全校/n 师生/n 员工/n 和/c 校友/n 致以/v 热烈/a 的/u 祝贺/vn 和/c 诚挚/a 的/u 问候/vn 。/w |
如果只需要测试中文分词结果,输入'lac --segonly'即可。LAC的代码调用也很方便:
(venv) textminer@textminer:~/nlp_tools/baidu_lac$ ipython Python 3.6.8 (default, May 7 2019, 14:58:50) Type 'copyright', 'credits' or 'license' for more information IPython 7.15.0 -- An enhanced Interactive Python. Type '?' for help. In [1]: from LAC import LAC # 如果只需要中文分词功能,设置'seg'模式,加载中文分词模型 In [2]: lac = LAC(mode='seg') # 单个样本调用 In [3]: text = '我爱自然语言处理' In [4]: result = lac.run(text) In [5]: print(result) ['我', '爱', '自然语言处理'] # 批量样本调用 In [6]: texts = ['我爱自然语言处理', '百度LAC是一个不错的中文词法分析工具', 'AINLP@我爱自然语言处理'] In [7]: result = lac.run(texts) In [8]: print(result) [['我', '爱', '自然语言处理'], ['百度', 'LAC', '是', '一个', '不错', '的', '中文', '词', '法', '分析', '工具'], ['AINLP', '@', '我', '爱', '自然语言处理']] |
如果需要使用LAC的词性标注与命名实体识别功能,可以调用的时候设置为'lac'模式,加载LAC模型:
In [11]: lac = LAC(mode='lac') In [12]: text = '我爱自然语言处理' In [13]: result = lac.run(text) In [14]: print(result) [['我', '爱', '自然语言处理'], ['r', 'v', 'nz']] In [15]: texts = ['我爱哈尔滨工业大学', '2020年6月7日哈工大迎来百年校庆'] In [16]: result = lac.run(texts) In [17]: print(result) [[['我', '爱', '哈尔滨工业大学'], ['r', 'v', 'ORG']], [['2020年6月7日', '哈工大', '迎来', '百年', '校庆'], ['TIME', 'ORG', 'v', 'm', 'n']]] |
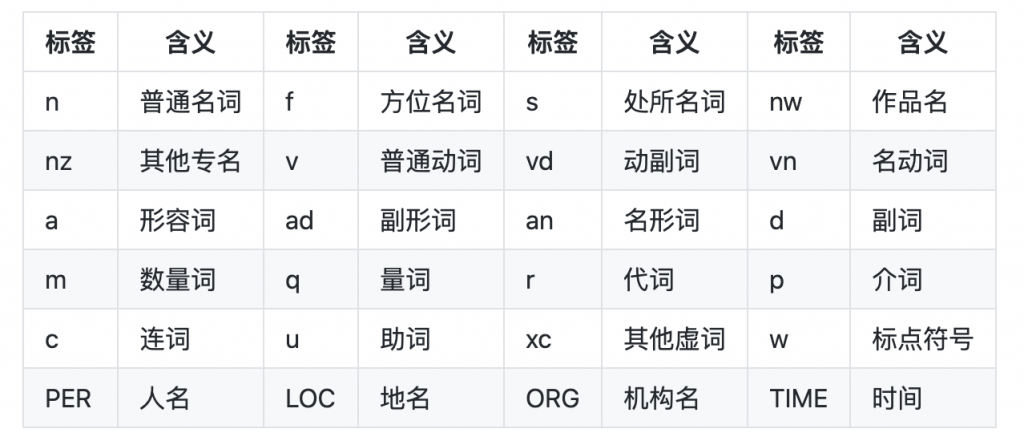
这里的输出格式为(word_list, tags_list),对应每个句子的切词结果word_list和每个词的对应词性标注的tags_list,其所用的词性标记集如下,包括4个常用的专名类别(PER, LOC, ORG, TIME):
此外,LAC的词典定制化和模型增量训练功能也相当友好,这对于有在实际业务需求的团队就非常有帮助,可以基于自己的业务需求和领域词典数据定制一个面向自身业务的中文词法分析模型,以下以词典定制化为例,我们添加了一个自定义词典 mydict.txt, 内容如下:
锦江石材/ORG 正式成立
以下是加载自定义词典前后的结果对比:
In [24]: text = "锦江石材正式成立了" In [25]: result = lac.run(text) # 没有干预的结果 In [26]: print(result) [['锦江', '石材', '正式', '成立', '了'], ['LOC', 'n', 'ad', 'v', 'xc']] In [27]: lac.load_customization('mydict.txt') In [28]: result = lac.run(text) # 干预后的结果 In [29]: print(result) [['锦江石材', '正式成立', '了'], ['ORG', 'v', 'xc']] |
至于模型增量训练,留给感兴趣的同学自己尝试了,这个功能很有用,可以参考LAC官方文档说明,很清晰。
最后需要说明一下本文主要参考了百度LAC的官方文档:
https://github.com/baidu/lac
关于LAC2.0的更详细介绍,可以参考:
开源!我知道你不知道,百度开源词法LAC 2.0帮你更懂中文
我们之前写得三篇关于百度NLP工具的相关文章,也可以对比参考和测试LAC1.x版本:
百度深度学习中文词法分析工具LAC试用之旅
来,试试百度的深度学习情感分析工具
中文命名实体识别工具(NER)哪家强?
百度 ERNIE-Health 和 百度 LAC 有啥区别?
[回复]
52nlp 回复:
8 12 月, 2021 at 11:58
不清楚
[回复]