
这两天在北京参加了 AI Challenger 2018 总决赛,这次又有点小幸运拿到了英中机器翻译决赛第5名,不过整个过程和去年的《AI Challenger 2017 奇遇记》有所不同。去年参加比赛的定位是“学”,学习NMT的相关知识和调研相关工具;今年参加比赛的定位是“用”,用熟悉的NMT工具。
与去年相比,今年的 AI Challenger 机器翻译赛道做了“优化”,首先没有了同传赛道,这个赛道去年因为有了“同传”二字吓走了一批人,其次最高奖金也降了,降到了20万,所以感觉相比于其他两个文本挖掘赛道,英中文本机器翻译赛道要冷清一些,另外一个原因可能是机器翻译的千万中英双语句对语料对机器资源的要求要高一些。
另外今年 AI Challenger 英中文本机器翻译大赛虽然语料还是口语领域的,但是额外增加了Document上下文语料,也是本次比赛新的命题点和关注点:
赛题描述简介英中机器文本翻译作为此次比赛的任务之一,目标是评测各个团队机器翻译的能力。本次机器翻译语言方向为英文到中文。测试文本为口语领域数据。参赛队伍需要根据评测方提供的数据训练机器翻译系统,可以自由的选择机器翻译技术。例如,基于规则的翻译技术、统计机器翻译及神经网络机器翻译等。
本次竞赛将利用机器翻译的客观考核指标(BLEU、NIST score、TER)进行评分,BLEU得分会作为主要的机器评价指标。组委会将通过客观指标,并结合答辩表现,综合评估参赛者的算法模型。
数据说明训练集文件名train.txt,其中每个训练样例包含自左至右4个元素:DocID, SenID, EngSen,ChnSen。DocID表示这个样例出现在哪个文件中,DocID用来提供训练集中句子出现的场景和上下文情景。SenID表示这个样例在DocID中出现的位置,比如,如果SenID为94,那么这个样例就是DocID的第94句话。若无上下文信息,则DocID和SenID均为NA。EngSen和ChnSen分别对应英文句子和中文句子,二者互译。
验证集和测试集为.sgm文件,句子格式和训练集相同。其中测试集没有与英文句子EngSen对应的中文句子ChnSen。
训练集和测试集、验证集的上下文文件包含所有语句的上下文的信息,其中每行包含自左至右三个元素:DocID, SenID, EngSen
训练集样例如下所示(第一列DocID, 第二列SenID, 第三列EngSen,第四列ChnSen):
测试集、验证集样例如下所示(第一列为DocID,第二列SenID,第三列EngSen):
验证集中文样例如下所示:
上下文文件样例如下所示(第一列为DocID,第二列SenID,第三列EngSen):
训练条件本次评测只允许参赛方使用评测方指定的数据训练机器翻译系统,并对其排名。参赛方需遵守以下关于训练方式的说明。参赛方可以使用基本的自然语言处理工具,例如中文分词和命名实体识别。




这次比赛,我没有使用 tensor2tensor,虽然这个工具是去年助我获奖的最终大杀器,也是今年官方推荐的baseline工具:AI Challenger 2018 文本挖掘类竞赛相关解决方案及代码汇总 。而是直接使用开源的神经网络机器翻译工具:Marian,这是一个高效的NMT工具,纯C++编写,特点就是快,很快,无论训练和解码,都非常快。Marian的标签是:Fast Neural Machine Translation in C++,它主要由波兰的波兹南亚当密茨凯维奇大学(AMU)和英国的爱丁堡大学共同开发,后者和Moses的关系紧密,所以Marian的开发者里也包括了Moses的一些开发者。

限于时间和工作关系,我没有用到Document上下文数据。数据预处理阶段和去年的路数差不多:英文数据利用Moses的相关脚本进行了预处理,包括tokenize和true case, 中文数据利用Jieba中文分词工具进行分词;英中数据共同使用bpe subword进行预处理;同时计算了句子长度比例分布,对词长超过100的句子对进行了过滤,对比例严重失调的句子对也进行了过滤。
模型训练阶段直接follow了爱丁堡大学的 wmt2017 英德系统的训练流程,并且用了加强版transformer模型,最终提交时得分是这样的:

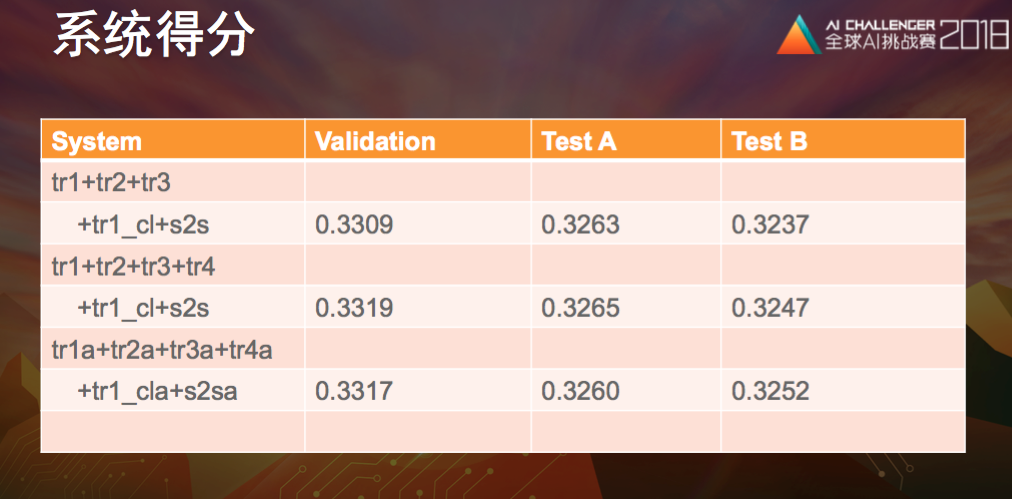
最终在TestB上提交的3个结果如上,都是多个模型的ensemble融合解码,做了一些参数和权重调整。
B榜结果出来之时,排在第7位,这个结果比之前的预想要好;之后在代码核验阶段,被拉进了一个top7群,和搜狗的工程师一起核验整个流程;最终被拉进了决赛答辩群,才发现前面又有两个队伍因种种原因放弃了,和去年又有一些相似。
参加决赛答辩的好处是可以学习一下前几名的方案,还是很好奇他们怎么做到的,另外一个好处是全程不用自己操心,官方从机票到酒店都弄得好好的,只要安心来参加活动就可以了。最终答辩的队伍除了我之外,有2个金山、1个浙大、1个京东团队,去年分获英中文本机器翻译第一和英中同传翻译第一的猎豹移动和自动化所紫冬认知没有参赛。金山和京东的同学,他们使用的机器都巨好,印象是V100还有P100,在好机器的加持下,加上细心的策略,是可以出好成绩的。
注:原创文章,转载请注明出处及保留链接“我爱自然语言处理”:https://www.52nlp.cn
本文链接地址:AI Challenger 2018 简记 https://www.52nlp.cn/?p=11082
膜拜大佬!!
[回复]
楼主说的 爱丁堡大学的 wmt2017 英德系统的训练流程,是啥。。
[回复]
52nlp 回复:
19 12 月, 2018 at 21:51
https://github.com/marian-nmt/marian-examples/tree/336740065d9c23e53e912a1befff18981d9d27ab/wmt2017-uedin
[回复]
你好,我是学习语言学的学生,对机器翻译测评感兴趣,请问有哪些是开放的机器翻译测评软件或是平台呢,目前只搜索到一些算法之类的
[回复]
52nlp 回复:
22 12 月, 2018 at 21:32
权威的机器翻译评测请关注 wmt : http://www.statmt.org/wmt18/ 或者 cwmt: http://nlp.nju.edu.cn/cwmt2018/ , 客观评测通过BLEU等值评估,一般都有脚本提供
[回复]
博主您好,请问一下:对每次训练产生的最终模型进行average,然后用average模型进行ensemble解码
这个average指的是什么呢?有没有具体的介绍或者脚本呢
[回复]
52nlp 回复:
27 12 月, 2018 at 15:54
https://github.com/marian-nmt/marian-examples/blob/master/training-basics/scripts/average.py
[回复]
“同时计算了句子长度比例分布,对词长超过100的句子对进行了过滤,对比例严重失调的句子对也进行了过滤“”
请问大佬,数据清洗这一块有没有开源的工具可以用呢
[回复]
52nlp 回复:
7 1 月, 2019 at 18:00
这一块儿有没有开源工具我不太清楚,对词长超过100的句子进行过滤直接用了Moses的脚本;计算句子比例分布自己写了简单的脚本
[回复]
阿水 回复:
8 2 月, 2019 at 23:34
博主,请问一下您写的这个统计比例分布的脚本可以分享一下吗。。代码能力有点弱。。写不出来。。
[回复]
52nlp 回复:
9 2 月, 2019 at 17:37
抱歉,因为我司内部使用,暂时无法分享;其实不难,可以试试。
博主您好,
“同时计算了句子长度比例分布,对词长超过100的句子对进行了过滤,对比例严重失调的句子对也进行了过滤”
在文章里面您谈到了数据预处理,也就是数据清洗,请问有没有开源的工具可以用呢?
[回复]
52nlp 回复:
7 1 月, 2019 at 17:58
这个自己写个简单的脚本就可以统计了
[回复]
博主,可否讲解or指导一下ensemble怎样操作吗,查不到具体实现方法
[回复]
52nlp 回复:
17 1 月, 2019 at 09:49
看marian的官方文档,写得很清楚
[回复]
阿水 回复:
24 1 月, 2019 at 18:28
好的 看到了 谢谢
[回复]
博主您好,请问一下:
“同时计算了句子长度比例分布,对词长超过100的句子对进行了过滤,对比例严重失调的句子对也进行了过滤。”
“对词长超过100的句子进行过滤直接用了Moses的脚本;”
这里面首先计算句子长度比例分布,是计算中文还是英文呢?还是都计算了,然后不管是中文还是英文,只要有超过100的,就删除掉对应的平行语料,还是说只计算中文长度。
对比例严重失调的句子进行过滤,这个比例是指的每一句语料的中文:英文的比例,还是说向前面一样,计算的每一行的长度,对所有语料进行一个比例分布的计算,对于占比非常低的某些长度直接进行删除。
另外请问一下过滤的MOSES脚本是哪个呢 ,翻看了一下您之前关于moses的文章,没有找到相关脚本。
[回复]
52nlp 回复:
25 1 月, 2019 at 10:10
句子长度比例分布是一起的,都计算,都统计,然后设定值进行过滤;
Moses的请参考Mosese官方baseline:
http://www.statmt.org/moses/?n=Moses.Baseline
Corpus Preparation部分有很标准的英文法文处理流程示例,里面有长度过滤脚本。
[回复]
博主你好,请问您有没有对Marian和Tensor2Tensor的训练速度进行对比啊,Marian在速度上提升,相同Epoch(or Step)的BLEU值相对Tensor2Tensor有没有做过对比呢?
[回复]
52nlp 回复:
28 3 月, 2019 at 12:00
这次没有对比,但是如果用2018的marian对比2017的tensor2tensor,前者秒杀后者,训练速度上。
[回复]
博主您好,我在训练Marian的时候遇到了Error: Curand error 203 - /container_data/marian-dev/src/tensors/rand.cpp:75: curandCreateGenerator(&generator_, CURAND_RNG_PSEUDO_DEFAULT)
[2019-06-04 03:16:36] Error: Aborted from marian::CurandRandomGenerator::CurandRandomGenerator(size_t, marian::DeviceId) in /container_data/marian-dev/src/tensors/rand.cpp:75这个问题,请问您知道怎么处理么
[回复]
博主您好,我在训练Marian的时候遇到这么错误Error: Curand error 203 - /container_data/marian-dev/src/tensors/rand.cpp:75: curandCreateGenerator(&generator_, CURAND_RNG_PSEUDO_DEFAULT)
[2019-06-04 03:16:36] Error: Aborted from marian::CurandRandomGenerator::CurandRandomGenerator(size_t, marian::DeviceId) in /container_data/marian-dev/src/tensors/rand.cpp:75 请问您之前遇到过么
[回复]
52nlp 回复:
4 6 月, 2019 at 11:44
之前没有遇到过
[回复]
王伟璇 回复:
4 6 月, 2019 at 13:42
那请问您知道这是哪里出的问题么
[回复]
王伟璇 回复:
4 6 月, 2019 at 14:20
感谢您的回复,我是nlp的研究生想训练Marian,我的环境是cuda8.0。在训练Marian的时候,读取词典后会报这个错误,请问您知道这是cuda版本的问题还是我的操作哪里出问题了呢?如果方便的话,可以私聊一下么~
[回复]
52nlp 回复:
4 6 月, 2019 at 15:18
我用的是cuda9;没有背景描述很难界定问题;抱歉,比较忙,没有时间私聊做问题解答,可以留言,如果可以解答,会回复。
ilove learn 回复:
20 9 月, 2019 at 13:59
请问这个问题您后来解决了么?我也遇到了这个 问题,但更换了cuda仍然没有解决
[回复]
博主你好,我现在也在用Marian,我在机器上是可以做正常训练和翻译预测的。但是我发现在模型是transformer时,我的min-batch-size最大只能设到400(在四张2080Ti上,每张卡是11GB),并且喂给模型训练的最大长度句子只能设到50,要不然会OOM。我想请教下,你当时的模型可以设到多少呢?我看官网上这两个参数分别可以设到1000,和100。谢谢你
[回复]
52nlp 回复:
14 6 月, 2019 at 17:28
查了一下当时的记录,是1000
[回复]
Jiaqi Wu 回复:
14 6 月, 2019 at 18:00
你当时用了几个GPU呢?谢谢
[回复]
52nlp 回复:
15 6 月, 2019 at 16:04
1080TI,主要是1台双卡机器,用到过4卡机器。