
52nlp有一段时间没有收到任何评论或留言了,晚上发现《自然语言处理公司巡礼六:Metaweb》有一条新留言,挺高兴的:
“http://www.cwbbase.com 是一个含 115,000 词的、有点类似 WordNet 的中文语义词库。欢迎访问,欢迎惠赐宝贵意见。”
毕竟WordNet大名鼎鼎,搞自然语言处理的同行大概都知道一些,如果真的做得是中文语义词库,还是很有意义的事。于是我访问了这个网站,本以为这是个中文语义词库的在线网站,但这个网站上提供的是桌面版的演示软件。以下是其简介:
“这是一个略具规模的中文语义词库, 也是稍有特色的汉语语义词典。它含有 10 万以上的词条, 每个词条通过关系比较密切的相关词 (例如同义词、反义词、上位词、下位词等) 与其它词条相连结。整个词库呈现为比较复杂的网络结构, 并带有多种检索手段和显示方式。”
虽然自己对这一块儿不熟,但是还是下载了“CWB中文词库演示版”试用了一下,以下是搜索“自然语言处理”的效果图:
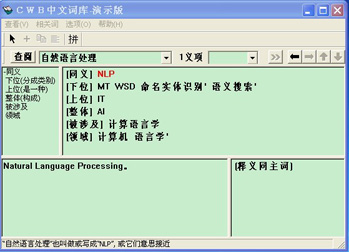
CWB中文词库做得很专业,帮助文档非常详细,而我也很想了解CWB的背景,毕竟研制这样的语义词库比一般的词典难度大的多,没有一定知识积累以及资金的支持,很难做得下去。但是,当我读到帮助文档中《为什么要研制 CWB 词库》的最后一段看到“本系统没有科研经费的支持”时,非常非常震惊:毕竟在中国,甭说没有科研经费的支持,就是有了科研经费的支持,真正用在刀刃上,真正踏踏实实做事的又有几人?我从心底里敬佩CWB中文词库的作者!
而事实上当看到作者隐去自己姓名的简介时,直觉就告诉我,这个作者很不一般:
“作者是语言学、现代哲学、人工智能、软件设计的爱好者。长期从事语义学研究和自然语言处理系统的开发。设计过机器翻译实验系统、中文自动分词系统、中文全文检索系统, 其中有的曾进入市场或在某些机构长期使用。曾在中文信息处理、语言学、哲学等领域的刊物上发表过若干篇语义学论文, 并撰写了较多语义学笔记, 主要探讨了语义关系、命名理论、知识本体等方面的一些问题。1993-1996 年间担任过少数全国性和国际性中文信息处理学术会议的程序委员会委员。原电子部在京机构高级工程师。20 世纪 90 年代中期辞职成为自由人员, 并主要从事 CWB 中文词库的研制工作。”
这里至少告诉我几个事实:作者曾涉足过机器翻译、中文分词及信息检索等领域,尤其在语义学方面的研究卓有成就,并且在90年代初中期的时候在中文信息处理领域具有一定的声望!另外,从帮助文档中还能看到作者在90年代中期以后逐渐将精力完全集中到语义词典“CWB中文词库”的研制上来,这也让我想起了“一生只做一件事”这句至理名言!
那么“CWB中文词库”的作者究竟是谁?帮助文档里的一些文章给了我提示,通过Google搜索还是找到了答案,不过这涉及个人隐私,这里就隐去不说了,但是可以肯定的是:“CWB中文词库”的作者是国内早期研究自然语言处理相关领域的老一辈拓荒者,对中文信息处理相关领域的发展做出了很大的贡献!
最后摘录《为什么要研制 CWB 词库》的一段话:
“由于理论问题的困扰, 尚未渐入佳境。作者还在不断修改该词库, 深感才疏学浅, 勉为其难, 决不敢掉以轻心或自鸣得意。岂能尽如人意, 但求无愧我心。在这个理论空白点尚多、数据庞杂多变、且还要做出比较精密的软件的领域, 努力追求、逼近完善是长期的任务, 无法一蹴而就。这一点是这种事情的性质所决定的, 不是一般谦虚的话。夸大的宣传只会误导用户和读者。语义学和知识库的一些问题也许还需要若干代人或更长时间的努力才可能解决。计算机获取和表示人类知识还任重而道远。语义词库所涵盖的知识还相当有限。对这些应有清醒的认识。目前自然语言处理中的各种方法和资源都有其局限性, 本系统当然也是如此。”
这段话让我深切感受到了前辈老师的谦虚和务实!而这段话似乎又可以拿来与所有搞自然语言处理的研究者分享和共勉!这里由衷的向前辈老师致上深深的敬意!
注:原创文章,转载请注明出处“我爱自然语言处理”:www.52nlp.cn
本文链接地址:https://www.52nlp.cn/cwb-trial-and-others
呵呵,都很关注你的帖子,只是没有留言,以后会随时关注的
[回复]
admin 回复:
22 5 月, 2009 at 14:52
呵呵,欢迎常来!
[回复]
佩服,这个领域确实非常难,需要极大的毅力
[回复]
同佩服;同欢迎!
[回复]
一直在关注52nlp,学习到了不少,很是感谢。最近在作基于crf的中文分词,发觉crf可配置性比较差,正在寻找方法中。
[回复]
52nlp 回复:
4 3 月, 2010 at 19:10
不客气,crf分词我也只是搞了个皮毛,不过建议你可以参考一下日文分词系统mecab:
mecab (http://mecab.sourceforge.net/) 是日本奈良先端科学技术大学院的工藤拓开发的日文分词系统, 该作者写过多个 machine learning 方面的软件包,最有名的就是CRF++, 目前该作者在 google@Japan 工作。
mecab 是基于CRF 的一个日文分词系统,代码使用 c++ 实现, 基本上内嵌了 CRF++ 的代码,同时提供了多种脚本语言调用的接口(python, perl, ruby 等).整个系统的架构采用通用泛化的设计,用户可以通过配置文件定制CRF训练中需要使用的特征模板。 甚至,如果你有中文的分词语料作为训练语料,可以在该架构下按照其配置文件的规范定制一个中文的分词系统。
日文NLP 界有几个有名的开源分词系统, Juman, Chasen, Mecab. Juman 和 Chasen 都是比较老的系统了, Mecab 系统比较新, 在很多方面都优于 Juman 和 Chasen, mecab目前开发也比较活跃。 Mecab 虽然使用 CRF 实现, 但是解析效率上却相当高效, 据作者的介绍, Mecab 比基于 HMM 的 Chasen 的解析速度要快。笔者在一台 Linux 机器上粗略测试过其速度,将近达到 2MB/s, 完全达到了工程应用的需求, 该系统目前在日文NLP 界被广泛使用。
水木社区自然语言处理版有人将其日文文档翻译为中文文档,可以在这里找到:
http://www.newsmth.net/bbscon.php?bid=1018&id=6417
[回复]
恩,不错,可以下载来看个究竟。谢谢52nlp。加油,支持你!
[回复]
52nlp 回复:
5 3 月, 2010 at 19:17
谢谢支持,欢迎常来看看!
[回复]
其实一直关注,只是没有留言罢了!
[回复]
52nlp 回复:
11 10 月, 2010 at 21:27
谢谢!
[回复]
http://www.cwbbase.com/ 可惜已经不是这个网站了
[回复]
木子二月鸟 回复:
25 4 月, 2018 at 10:44
是啊,cwbbase的网站内容已经变了。。。早知道的话应该早支持一下
[回复]
不知道CWB怎么集成到代码里?python 使用了下CWB很不错但是图形界面的,不知道怎么集成
[回复]
52nlp 回复:
3 7 月, 2017 at 13:59
这个不清楚
[回复]
之前从来没有留言过,但是经常来看看,感谢你这么坚持!
[回复]
52nlp 回复:
16 1 月, 2019 at 15:39
谢谢
[回复]