
自然语言处理:最大熵和对数线性模型
Natural Language Processing: Maximum Entropy and Log-linear Models
作者:Regina Barzilay(MIT,EECS Department, October 1, 2004)
译者:我爱自然语言处理(www.52nlp.cn ,2009年4月29日)
一、 词性标注(POS tagging):
c) 特征向量表示(Feature Vector Representation)
i. 一个特征就是一个函数f(A feature is a function f ):
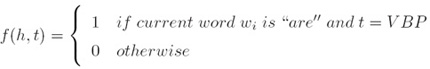
ii. 我们有m个特征fk,k = 1…m(We have m features fk for k =1...m)
d) 词性表示(POS Representation)
i. 对于所有的单纯/标记对的单词/标记特征,(Word/tag features for all word/tag pairs):
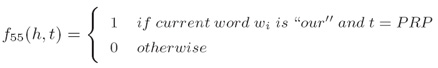
ii. 对于所有特定长度的前缀/后缀的拼写特征(Spelling features for all prefixes/suffixes of certain length):
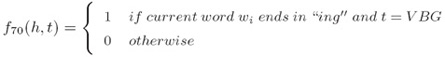
iii. 上下文特征(Contextual features):
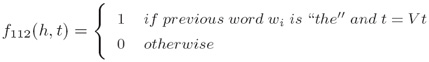
iv. 对于一个给定的“历史”x ∈ X ,每一个γ中的标记都被映射到一个不同的特征向量(For a given history x ∈ X, each label in γ is mapped to a different feature vector):
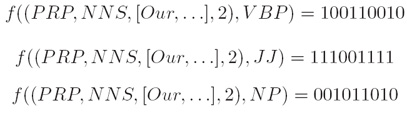
v. 目标(Goal):学习一个条件概率P(tag|history)(learn a conditional probability P(tag|history)
二、 最大熵(Maximum Entropy):
a) 例子(Motivating Example):
i. 给定约束条件:p(x, 0)+p(y, 0)=0.6,a ∈{x, y}且b ∈0, 1,估计概率分布p(a, b)(Estimate probability distribution p(a, b), given the constraint: p(x, 0) + p(y, 0) =0.6, where a ∈{x, y}and b ∈0, 1)):
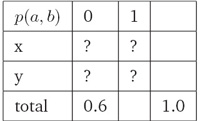
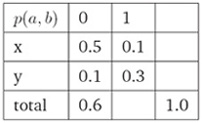
ii. 满足约束条件的一种分布(One Way To Satisfy Constraints):
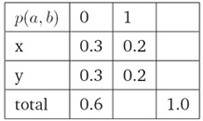
iii. 满足约束条件的另一种分布(Another Way To Satisfy Constraints):
b) 最大熵模型(Maximum Entropy Modeling)
i. 给定一个训练样本集,我们希望寻找一个分布符合如下两个条件(Given a set of training examples, we wish to find a distribution which):
1. 满足已知的约束条件(satisfies the input constraints)
2. 最大化其不确定性(maximizes the uncertainty)
ii. 补充:
最大熵原理是在1957 年由E.T.Jaynes 提出的,其主要思想是,在只掌握关于未知分布的部分知识时,应该选取符合这些知识但熵值最大的概率分布。因为在这种情况下,符合已知知识的概率分布可能不止一个。我们知道,熵定义的实际上是一个随机变量的不确定性,熵最大的时侯,说明随机变量最不确定,换句话说,也就是随机变量最随机,对其行为做准确预测最困难。从这个意义上讲,那么最大熵原理的实质就是,在已知部分知识的前提下,关于未知分布最合理的推断就是符合已知知识最不确定或最随机的推断,这是我们可以作出的唯一不偏不倚的选择,任何其它的选择都意味着我们增加了其它的约束和假设,这些约束和假设根据我们掌握的信息无法做出。(这一段转自北大常宝宝老师的《自然语言处理的最大熵模型》)
未完待续:第三部分
附:课程及课件pdf下载MIT英文网页地址:
http://people.csail.mit.edu/regina/6881/
注:本文遵照麻省理工学院开放式课程创作共享规范翻译发布,转载请注明出处“我爱自然语言处理”:www.52nlp.cn
本文链接地址:https://www.52nlp.cn/mit-nlp-fifth-lesson-maximum-entropy-and-log-linear-models-second-part/
师兄,你好,我刚开始学习最大熵,有两个地方不是很懂,呵呵,在这请教一下师兄啊!
1. 上面的那个特征向量是怎么映射出来呀?
2. 第三部分中的那个-特征的观察样本期望值-代表什么意思啊?
谢谢师兄啦!
[回复]
52nlp 回复:
12 3 月, 2010 at 23:12
对于第一个问题,我有点不太明白你的意思,不知道下面的解释是否正确:
特征向量的映射事实上是一个计数的过程,如果在语料库的上下文中找到了相关的特征,就计数一次,最后累加,得到这个特征的总次数,有了这个总次数,就可以计算每个特征的条件概率了。
第二个问题:
观察样本的期望值代表的是训练语料库中的“事实”,而特征模型期望值代表的是理论上的估计,令其相等也就是我们要“承认已知事实”。
另外关于最大熵模型,这个翻译系列来自于PPT,比较简单,很多问题和背景知识没有解释清楚,建议你读读《最大熵模型文献阅读指南》中的经典文献:
https://www.52nlp.cn/maximum-entropy-model-tutorial-reading
[回复]
sknow 回复:
13 3 月, 2010 at 21:30
哦,谢谢师兄啊,呵呵,关于第二个我还是不太明白,也看过Berger 那篇文献对应的部分,我的问题是,对于计算期望的那个公式,不太清楚它计算的是什么东西,这个东西的物理意义是什么。如果有期望的话,那它应该是一个随机变量,那这个随机变量代表的是什么呢?师兄所说的“事实”是指什么呢?
[回复]
52nlp 回复:
14 3 月, 2010 at 18:42
举个简单的例子:我们有一个训练语料库,包含的全是词性,其中名词(特征f1)出现了40次,动词(特征f2)出现了30次,形容词(特征f3)出现了30次。对于特征f1:其在语料库中的观察次数是40次,而总得训练样本的次数是30+30+40=100次,其观察概率是40/100,这个就是特征的观察样本期望值:
Epf1 = 40/100 * 1 + 60/100 * 0 = 40/100。
而“事实”也指的是其观察概率,通俗的说就是训练语料库告诉我们名词出现的可能性约为2/5,略微大一些。
sknow 回复:
15 3 月, 2010 at 11:26
哦,好的,谢谢师兄啊!
hi 🙂
我觉得@sknow的第一个问题解答应该是这样的:
对于每个x(history),y(tag ),
f(x,y)=0111010其实代表了一个二元序列,代表x,y在第i个特征取得是0还是1
真正计算数目的应该不是特征i的出现的数目,而是(x,y)在语料库中出现的次数,因为目的不是求特定特征i的概率,而是求p(x,y)或者p(y|x),然后利用根据统计数目求出的p(x,y)用来计算Ef1,然后把这个Ef1作为约束
[回复]
52nlp 回复:
26 11 月, 2011 at 10:04
实际上处理时也基本上是统计特征出现的次数的,最终的p(y|x)也是根据每个特征的学习的权重计算出来的。
[回复]