
AINLP原创 · 作者 | 叶俊杰、赵京伟
工作单位 | vivo 深圳AI研究院 NLP技术组
研究方向 | 多模态,表示学习
个人介绍 | 叶俊杰,技术专家,毕业于香港中文大学。赵京伟,vivo AI Lab基础研究负责人,毕业于清华大学电子工程系。
合作单位:香港中文大学、中国科学院深圳先进技术研究院
从人脸识别,机器翻译到智能推荐,人工智能已经深入到现代社会的方方面面。现在工业上最常见的人工智能系统,往往依赖于大量有标签的数据。通常,优质的有标签数据需要耗费大量的人力、物力。而且人工打的标签的准确度,往往随着标注任务复杂度的提高而降低。
一般的人工智能算法,都是在干净的数据集上做学习和优化。在现实中的工业应用场景中存在大量弱监督的情况,即标签缺失(无监督、半监督)、标签错误(错监督)的情况。我们在第一个章节,简单介绍一下我们vivo ai lab两篇AAAI2021关于弱监督带噪学习的工作;并在第二章介绍一下我们的工作在内容审核业务下的工业级应用。
一、论文介绍
1)Robustness of Accuracy Metric and its Inspirations in Learning with Noisy Labels
我们称包含错误的标签为噪声标签,而在给定错误标签上学习的过程为带噪学习。传统对噪声标签的研究集中在Class Conditional Noise(CCN)的假设下。CCN假设了,一个样本的噪声标签的分布只和该样本的真实标签有关系,即Pr[Y~ = j|Y = i] = Ti;j,其中i是真实的标签,j是噪声标签。由组成的矩阵,称为转移矩阵;转移矩阵完整表示了CCN下的噪声的分布。
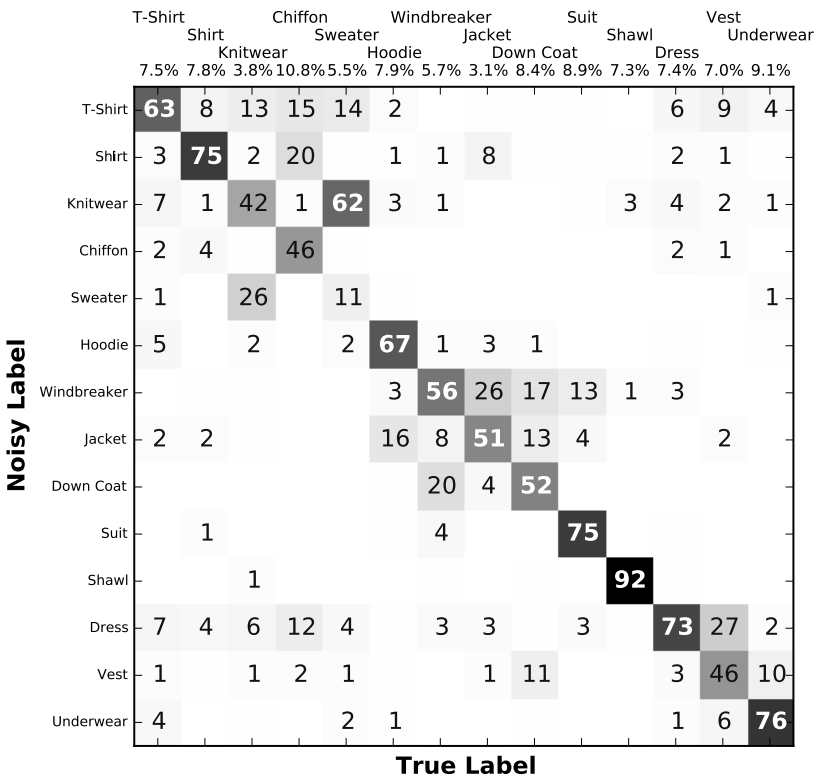
图表 1 Clothing1M数据集的混淆矩阵
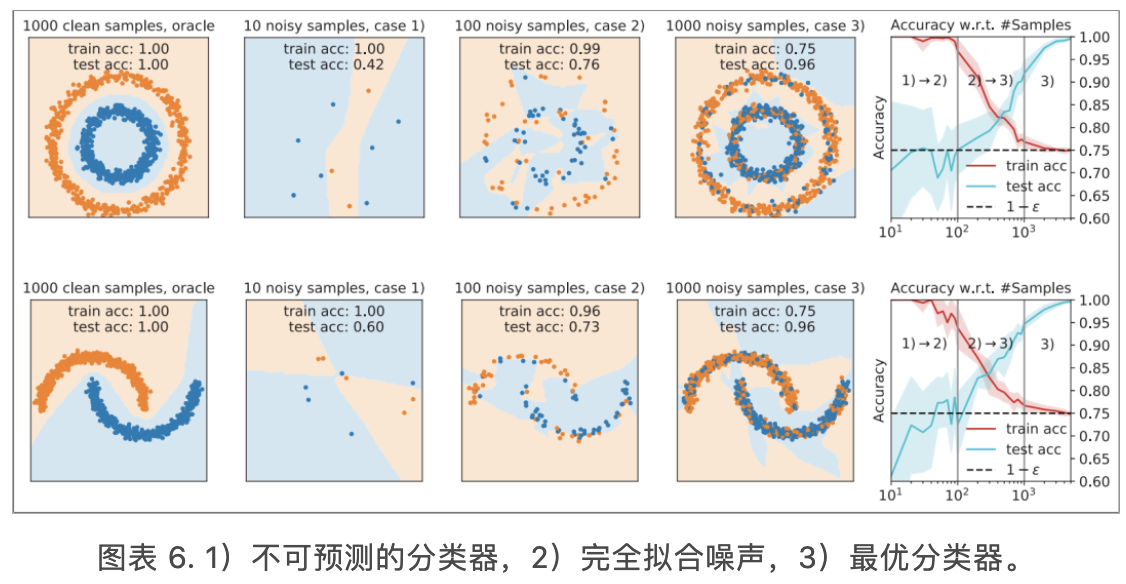
针对一般的人工智能算法,我们可以在一个干净的数据集上训练,目标是在干净的真实分布上表现好。算法的泛化能力只需要考虑准确率在数据集和真实分布之间的差距。但是当我们进行带噪学习时,我们只有一个带噪数据集,和一个隐含并未知的噪声分布,需要在干净的真实分布上表现好。泛化能力的分析需要考虑算法在噪声数据,噪声分布和真实分布三者上准确率的差距(图2)。
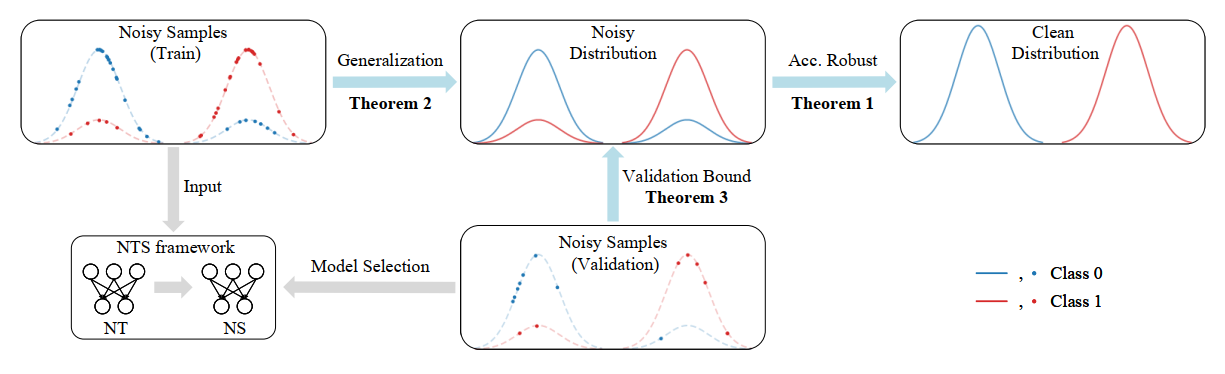
图表 2带噪学习的分析和算法流程
理论分析:
之前很多工作大多把注意力放在研究损失函数的鲁棒性上,并提出了各种不同的鲁棒的损失函数,包括GCE、DMI等等。我们的工作证明了,最基本的0-1 loss(即,准确率)本身就是鲁棒的。所以,对于CCN下的带噪学习,我们并不需要过多得关注损失函数的鲁棒性。在CCN的假设下,当分类器在噪声分布上表现最优时,它在真实分布上的表现也是最优的。我们只需要针对噪声分布的Acc进行优化,就可以在真实分布上达到好的效果。

图表 3最优分类器以及准确率的鲁棒性
基于VC-bound,本工作还进一步分析了从噪声数据到噪声分布的泛化能力(论文中的Theorem 2和3)。定理1和2保证了,噪声数据到真实分布之间的泛化能力;而定理1和3证明了用带噪声的验证集验证算法的有效性是可行的。

图表 4. 带噪训练集到噪声分布的泛化能力。

图表 5. 带噪验证集到噪声分布的泛化能力。
总结:
- 鲁棒性(定理1):当分类器在噪声分布下准确率最优时,其在干净分布下保证是最优的。
- 噪声泛化(定理2):给定足够多的噪声数据,用最简单的CE-loss训练可以获得最优分类器。
- 噪声验证(定理3):用带噪声的验证集验证算法,是可靠的。
实验结果:
我们用实验观察和论证了,当噪声数据逐渐变多,分类器的效果如何接近最优分类器(定理1和定理2)。
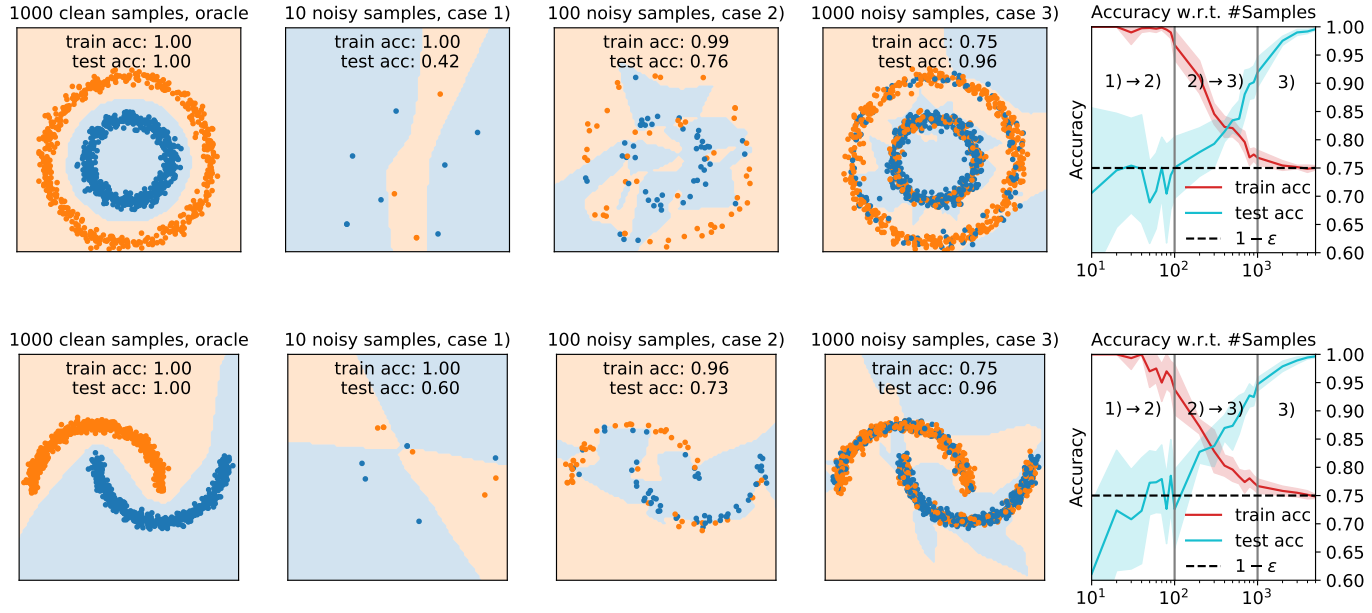
图表 6. 1)不可预测的分类器,2)完全拟合噪声,3)最优分类器。
同时,我们设计了一种简单、有效的带噪学习的框架NTS。NTS包含两个部分,其中Noisy Best Teacher(NT):在带噪的训练集上训练,并选取在带噪的验证集表现最好的模型(教师模型);Noisy Best Student(NS): 用教师模型的预测替换噪声标签,再进行训练,同样地通过带噪的验证集选取最好的模型(学生模型)。通过的大量的实验对比,NTS都能提升GCE、DMI、Co-Teaching等SOTA的算法性能。
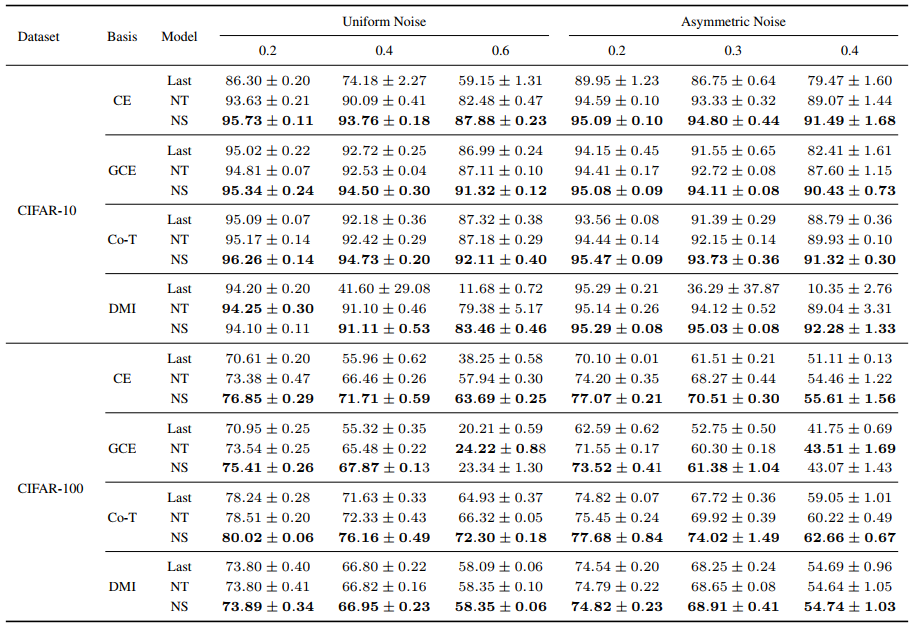
图表 7. SOTA算法结合了NTS之后的实验效果。
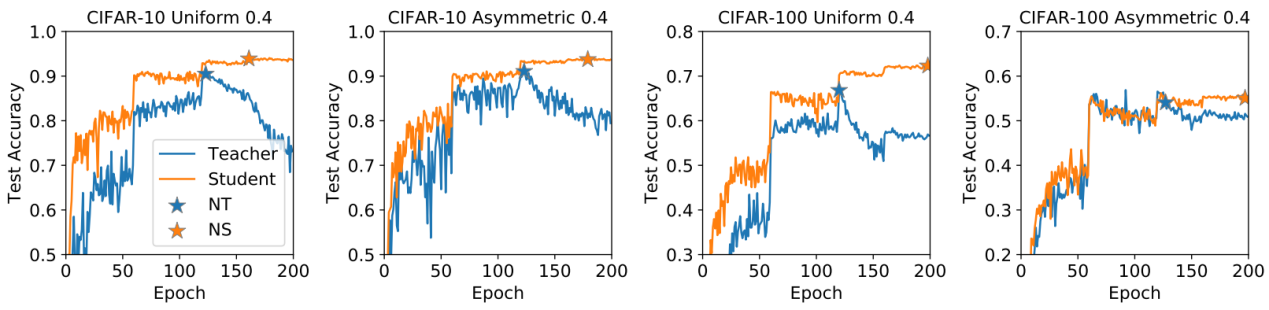
图表 8. 通过带噪验证集选取的模型,确实是表现最优的。
2)An Attempt to Combat Instance-Dependent Label Noise
上一部分,我们分享了在CCN假设下的带噪学习。接下来,我们介绍更一般化的Instance-Dependent Noise(IDN)。
现有的深度学习大厦,建立在数据独立同分布的根基上;而真实数据往往并不独立,同一类别内也可能存在不同分布。这些不是独立同分布的数据点,例如远离分布中心的特殊样本,对于模型的泛化能力至关重要。
下图很好得体现了这一点:上排是MINST数据集中标签为8的数据,可以看到它们的形态很不一样,有些更容易被错标成6,有些更容易被错标成0;下排是CIFAR10中标签为飞机的数据,同样它们的噪声标签可能很不一样。由此,我们可以知道,噪声标签不仅仅依赖于真实标签(CCN假设了噪声标签仅仅依赖于真实的标签),还和样本本身的feature息息相关,而IDN就是基于这样的考虑下研究的噪声标签。

图表 9. MINST中标签为8,和CIFAR10中标签为Airplane的数据。
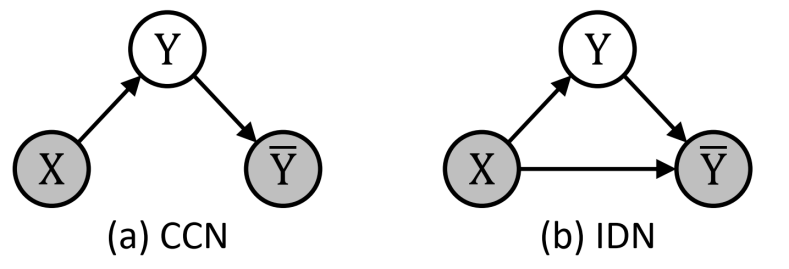
图表 10. CCN和IDN的不同。
在这一工作中,我们首先证明了CCN的噪声标签下,分类器在噪声分布上的准确率不可能太好(定理1)。证明内容详见论文。

图表 11. CCN假设下,分类器在噪声分布上表现不会很好。
其中M是混淆矩阵,er[f]是分类器f的错误率。
在Clothing1M数据集上,我们用随机选取的50万数据,训练了一个ResNet-50的模型,并在剩下的数据上验证,得到验证集上的错误率为0.1605。然而,我们利用定理1和Clothing1M的混淆矩阵,可以计算出在CCN的假设下0.1605这个错误率发生的概率低于。所以,明显得Clothing1M这一真实数据集的标签,并不满足CCN假设,而是属于IDN。
IDN的挑战和实验现象:
- 在CCN噪声的数据集上,我们可以挑选标签是正确的样本,来训练神经网络。很多优秀的算法,就是通过挑选出尽量多的正确样本来提升算法性能。这样挑选并不会破坏数据的真实分布,但是在IDN噪声的数据集上,这样挑选样本,很有可能挑选出来的样本集和原本数据的真实分布就不一样。
- 在学术界并没有很规范的IDN数据集,供大家在上面分析和研究。
- 由于IDN的错误是和样本本身的feature相关,所以相对于CCN,神经网络更容易拟合IDN的错误。这也进一步导致,与CCN相比,在IDN上的memorization effect现象并不明显。
- 实验表明,在最终记住样本的错误标签之前,神经网络的预测会在正确标签和错误标签之间震荡,如图12所示。
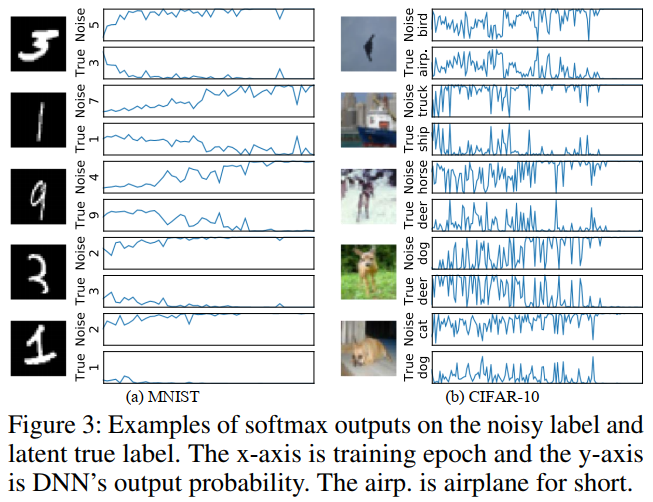
图表 12. 神经网络的预测在错误标签和真实值之间震荡,并最终记住了错误的标签。
受神经网络的震荡效果的启发,我们提出了一种简单、实效的IDN算法SEAL(self-evolution average label)。我们将神经网络多个epochs的预测值求平均作为下一个iteration中的目标值,迭代几次iteration,得到最终的输出。

图表 13. SEAL算法的一次iteration。
实验结果:
我们在MNIST,CIFAR10和Clothing1M上都验证了SEAL的有效性。特别地,在CIFAR10数据集30%和40%的噪声比例下,简单的Cross Entropy训练配合SEAL算法可以比Co-teaching、DMI等SOTA算法提高3-4个点的准确率。同样地,在Clothing1M数据集上,运用SEAL算法,也能提升1-2个点的准确率。具体实验数值见下图。

图表 14. 通过SEAL修正的标签。其中上排为噪声标签,括号内是SEAL预测值。
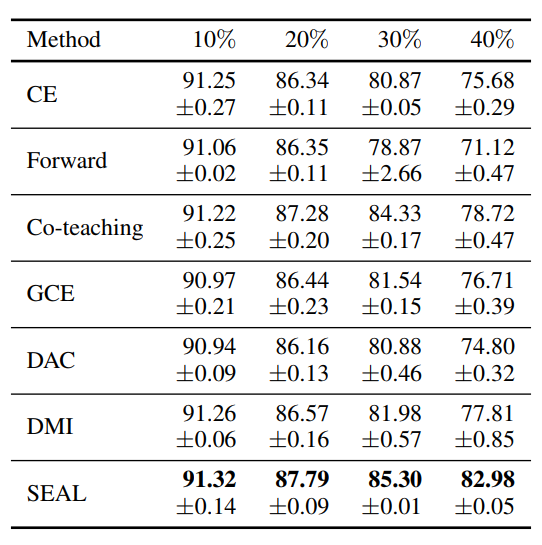
图表 15. CIFAR10上SEAL的效果,其中10%-40%值得是IDN的噪声比例。
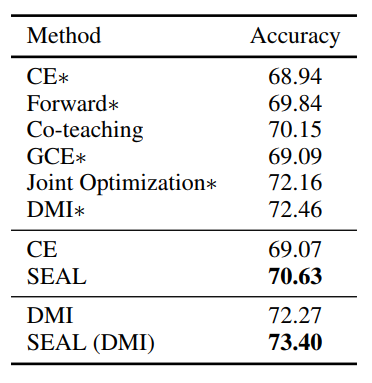
图表 16. Clothing1M上SEAL的效果。
二、带噪学习在内容审核中的应用
1)任务介绍
在vivo ai lab内容理解平台上,每天有大量的信息流(资讯,新闻,图文视频等)内容,其中有很多高质量的优秀内容,但由于其内容量过大(图文类内容就有数百万条),其中难免会混杂一些低质内容。显然直接通过人力审核是不现实的,所以一般是先通过人工智能筛查,再通过人工审核的方式去保证用户的阅读体验。
我们就以正常内容和低质内容的二分类问题,来说明我们是如何优化业务目标的。由于线上实际的低质内容比例很低,但是一旦错漏,会造成很大的不良影响;所以我们通过大量的人工标注,获得了一份离线数据集用于算法验证。在离线数据集中,训练样本10万条,验证集2万,测试集2万;正常样本和低质样本按1:1分布。每一条样本是一条图文混合资讯。如下图所示:
图例
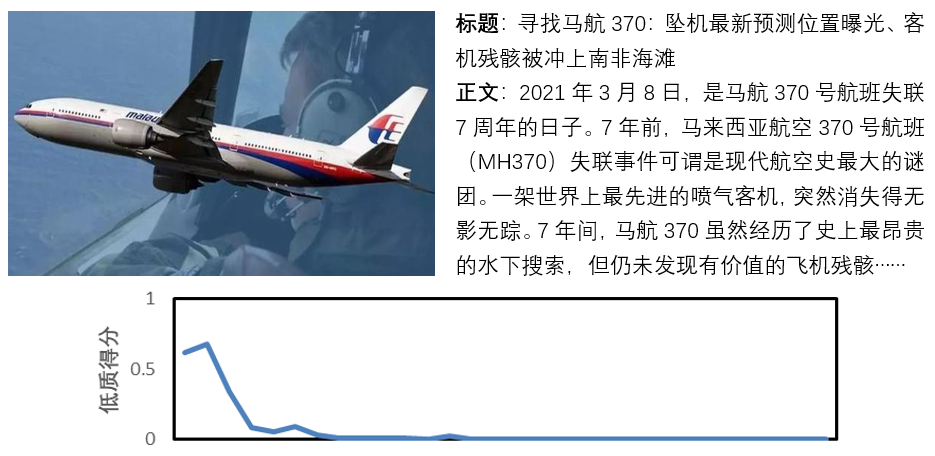
1
我们对离线数据集中的数据进行了2次标注,发现里面错标,误标,标签不确定的比例在15%左右。在这些有问题的标注数据里,主要是存在很多边界问题很难定义,例如在低质类资讯中的标题党,这种资讯大部分是靠标题吸引用户点击,但是内容与标题不符合。对于标题与内容完全无关的资讯是基本不会错标的。但是标题和内容关联度的具体界限是很难定义的,所以就有很多样本,标注难度很大,很难用硬标签刻画其真实的类别。
2)实践结果:
在实际的业务分类数据中,我们同时采用了NTS+SEAL的方法去优化这样的带噪数据。在文章An Attempt to Combat Instance-Dependent Label Noise中,我们展示了网络对于含有IDN噪声的数据,会在类别间震荡的现象。同样的,在低质内容中,对于一些错误标签,或者打标签难度很大的样本,也存在同样的现象。如下图所示:

图例2
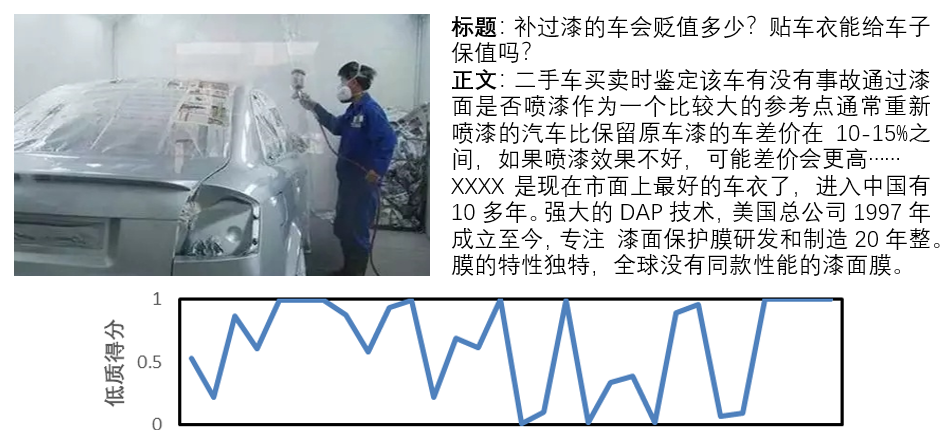
图例3
对于图例2来说,标签是正常,实际也是正常文章,但是由于在数据集中,艾滋病,暴力,咬,经常出现在低俗类别的文章中,所以网络在学习的过程中,会在正常和低俗(低俗是低质内容中的一个子类别)中震荡,最终收敛。
图例3是一个比较难学的软文,标题,配图,和前面大部分文字都是正常的科普向文章。但是最后一句开始介绍某个固定品牌的技术和历史。标签为软文,但在网络学习的过程中,同样经过了预测结果在正常和软文类别间的震荡。
SEAL中对教师模型学习过程中的预测标签取滑动平均的方法,对于在类别间震荡的困难样本,会输出更平滑和更‘soft’的标签,防止网络出现对少样本数据over confident的现象。而对图例1这种网络比较容易学习的样本,即使通过SEAL之后,教师模型的输出依然很‘hard’,不会影响收敛速度。
3)模型指标
| 内容审核 | 二分类F1(%) | 有标签数据 | 无标签数据 | |
| Supervised | Teacher | 90.86 | 100% | 无 |
| Student | 91.26 | |||
| Semi-supervised | Teacher | 89.36 | 25% | 75% |
| Student | 90.97 |
教师网络和学生网络选择一样的结构,测试结果如下表:
其中Supervised Teacher代表用全量10万条数据训练的模型。而Semi-supervised Teacher则只用了训练数据中随机抽取的2万5千条有标签的数据训练教师网络,学生网络则是学习教师网络在训练集(10万条数据)打的软标签。通过表格我们可以得知:
- 用NTS+SEAL的训练方式要比直接训练模型好,这一点其实其他知识蒸馏的相关的文章也有类似的结论。
- 越好的教师训练出的学生就越好。
- 随着标签数据的减少,有监督任务退化成了半监督任务,用NTS+SEAL的方法训练,依然好于直接的监督训练。减少75%的数据标注量,却获得了2+%的指标提升。
- 减少75%的数据标注量,用半监督的学习方法,教师网络的能力下降了1.5%,而学生网络只下降了0.29%
综上,NTS+SEAL的技术,可以对同时含有CCN和IDN的噪声数据,进行半监督优化。尤其是业务数据中存在大量无标签数据时,可以极大的提高对无标签数据的利用效率,降低企业对标注数据的需求,提高对难以避免的标注错误的鲁棒性。同时,如果标注噪声是CCN,那么NTS的技术以及文章中提到的定理,可以降低业务算法评估中对val,test数据集的质量要求。最后,学生模型可以使用异构的轻量级框架,进一步兼顾模型指标与运算性能。
论文链接:
- Robustness of Accuracy Metric and its Inspirations in Learning with Noisy Labels, https://arxiv.org/abs/2012.04193
- Beyond Class-Conditional Assumption: A Primary Attempt to Combat Instance-Dependent Label Noise, https://arxiv.org/abs/2012.0545