
AINLP原创 · 作者 | 叶文杰
工作单位 | vivo 深圳AI研究院 NLP技术组
研究方向 | 自然语言处理
个人介绍 | 就读于东南大学二年级,在2020年8月至2021年1月在vivo 深圳AI研究院 NLP技术组实习,实习期间主要从事模型压缩与蒸馏的工作
- 开篇
去年年底,各大榜单上风起云涌,各路英雄在榜单上为了分数能多个0.01而不停的躁动,迫不及待地想要向外界秀秀自己的肌肉。

怎么回事呀,小老弟?
我们打开了中文NLP知名的评测网站CLUE,却看到……
怎么全是Bert和它的兄弟?
遥想4年前,还全是RNN,LSTM和CNN的天下,怎么转眼都不见了?LSTM不禁长叹:年轻人,不讲武德!欺负我这个25岁的老同志。
那么有没有办法让LSTM重新焕发青春呢?有!知识蒸馏!
- 什么是知识蒸馏?
知识蒸馏的思想很简单,就是让一个教师模型来指导学生模型,让学生模型学到教师模型的知识,而知识蒸馏的的核心也就是知识。
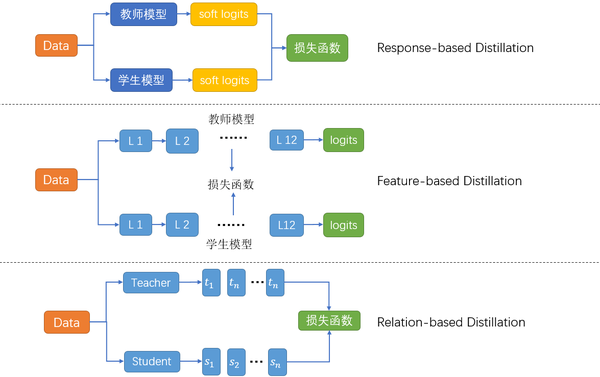
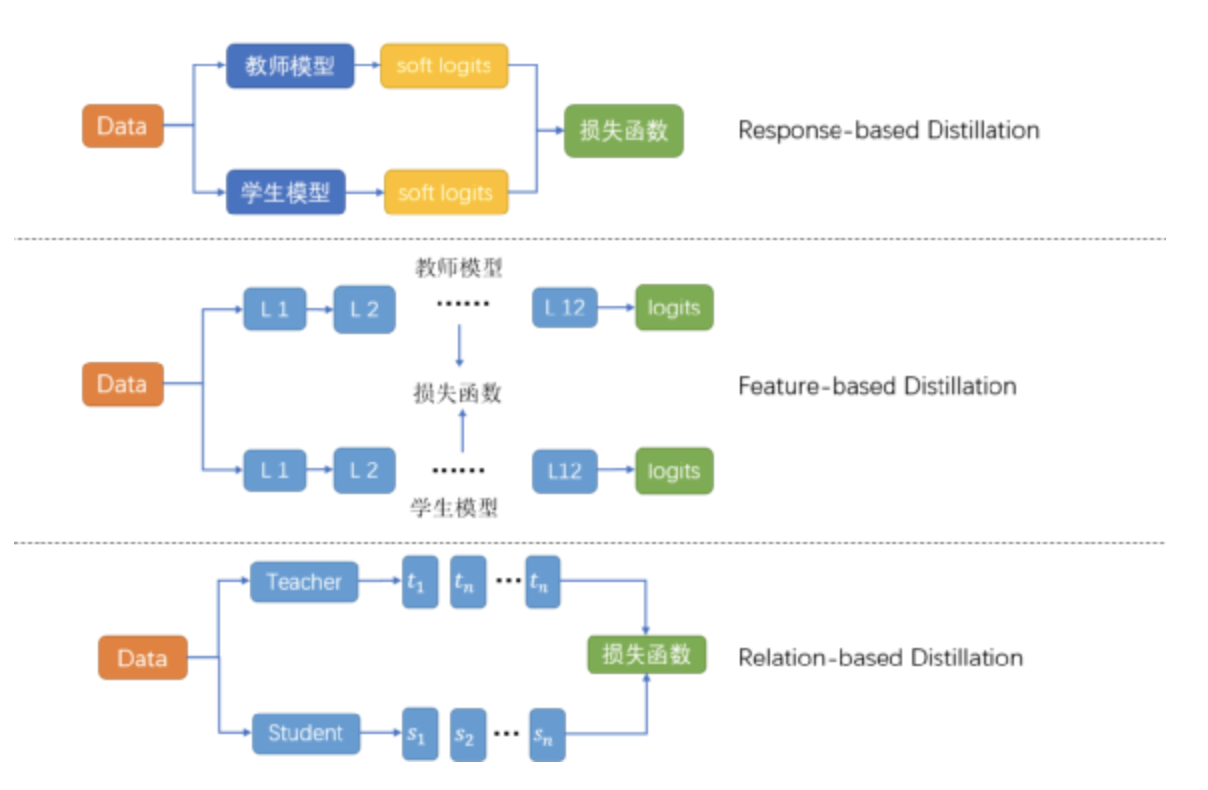
依据蒸馏所用的知识,可以把蒸馏分成三种:
Response-based Distillation:学学教师最后的输出就够我喝一壶了。
Feature-based distillation:中间层的知识也不能放过,毕竟神经网络最擅长的就是学习到层级信息。
Relation-based distillation:这些表面的知识完全不够,还要深挖层与层之间的关系,样本与样本之间的关系。
而这些知识之所以有效,主要是因为隐含的特征 (dark knowledge) 无法在数据层面表示出来,模型可以学习到这些特征。One-hot 无法衡量类间的区别,知识蒸馏一定程度上起到了标签平滑的作用。比如说马,驴和树他们在标注上都是不同的,通过one-hot表示呈现的区别也一致,很显然,马和驴的相似性强于马和树,而我们的标注无法衡量这种相似性,但是我们的教师模型却可以学到这样的知识。

细看这些年的BERT蒸馏都是这些套路:
DistilBERT: 学学教师最后的输出就够我喝一壶了
PKDBERT: 中间层的我也都要学
TinyBERT: embedding层的知识呢?我全都要!

TinyBERT对于知识的态度
既然能用蒸馏训练出一个性能强悍的小BERT,那可不可以用同样的方法来蒸馏LSTM,让他焕发第二春呢?
- 师夷长技以制夷
蒸馏的第一步是要选取一个表现优秀的教师模型,NER大榜的TOP1被RoBERTa抢先了,于是我们也选取RoBERTa作为我们的教师模型,在验证集上得分81.55。同时,在同样的训练集下训练双向LSTM,得分68.56。两者F1得分差距较大,直接尝试response-based distillation:
| 模型 | NER F1 (Valid) |
| Roberta | 81.55 |
| LSTM (Baseline) | 68.56 |
| LSTM (蒸馏) | 71.01 |
得分有所提升,但是和榜单上那个78、79的相比还是有很大的距离。这可怎么办?

这可怎么办?
有什么能进一步提升模型能力的方法,想想各类BERT都在几个T的数据上用几十块GPU训练了几百个小时,我们的LSTM只用个1万训练集当然不可能击败他们。我们也要用数据增强!
4.数据增强
CLUE NER的数据集是来源于清华大学开源的数据集THUCTC,所以我们尝试使用THU-News数据集进行增强。随机采样30万条进行测试。
| 模型 | Units | 教师模型 | 数据集 | NER F1(验证集) |
| LSTM | 512 | Roberta(81.55) | 30w+10748 | 0(零) |
?
这个0如此之纯粹,让人一度以为是不是跑错了代码,然后连续运行三次,得到的结果都是0!

我们赶紧拿到报告,找到里面的bad case(没有一条不是bad case),发现结果很直白,所有的预测全是O(非实体)。赶紧找来增强数据集出来看看,看到了这个:
| 他?亦或是她?也许都会有。 |
| 总会有花花修的,¥%……&&() ———当下冲动的想问问她姐姐是谁暴捶一顿…… |
| 今日悬念揭晓,几家雀跃几家惊讶,《精灵传说》正式与大家见面, |
| help item/ヘ儿プアイテム)等等 。 |
| credits作为zynga旗下游戏在facebook平台上的主要支付方式。 |
| 成为勇士中的王者! |
| 令附: |
| 为了鼓励大家多交朋友,目前android版本所有礼物都可以无限次免费赠送,现在就去吧! |
| 《马里奥赛车wii》wii任天堂株式会社 |
| 这是由大众对文化价值观认同决定的。2010年有差不多接近1亿左右的玩家, |
THU-News新闻数据集-游戏部分
可以看出,大部分样本一个实体都没有,和我们的任务完全就不是相同的分布(skewed),用这种数据集来训练模型,训练出来的模型将所有的标签都认为成O(非实体)。
5.那么怎么从这些杂乱的数据集中提取出可以用作增强的数据集呢?
如果让人工来清洗数据集的话,对于数据增强需要几十几百倍的数据,NER标注数据有有一点难度。人工根本行不通!
鉴于我们在使用知识蒸馏训练模型,那能不能请教师模型来帮忙清洗数据?
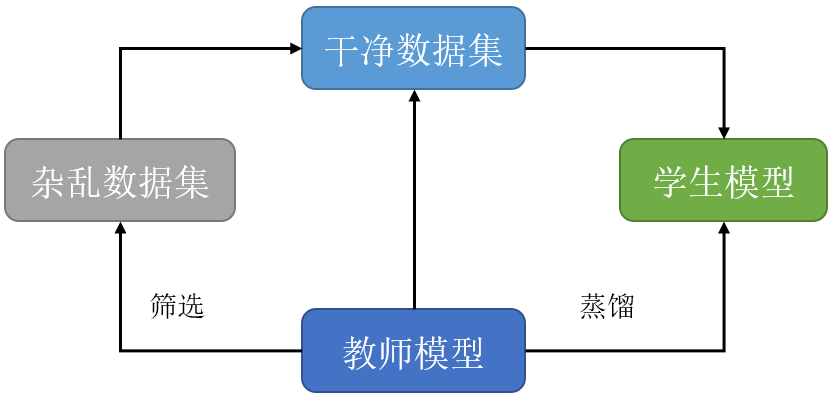
我们进行了个大胆的尝试,不对数据集进行任何清洗,直接用教师模型对2000万的杂乱数据集进行推理,然后只保留了教师模型认为包含实体的数据:
| 至少包含一个实体 | 至少包含两个实体 |
| 甚至吸引了剃了平头的六番队队长朽木白哉~!哈哈哈(大误~。 | 联合导演兼主演吴亚桥担当形象大使的《剑网3》“收费游戏免费玩”高校威武计划。 |
| 2008年12月“it时代周刊:2008年最具商业价值网站”; | 游戏委员会称,对游戏的审核需要很长时间,所以像苹果和谷歌系统旗下的游戏, |
| 嘟嘟的目标是召集100名玩家在三江源办一场变身舞会,在这里希望大家帮她一起达成愿望。 | 咪兔数位科技旗下《穿越火线online》全新改版“末世录”正式上线!玩家不仅能体验到全新的“ |
| 但这一次overkill依然把自己的作品托付给了一家日本公司:soe(索尼娱乐在线)。 | 北美区全球争霸战亚军队伍tsg对上韩国全球争霸战冠军队伍shipit,分别采取圣骑、战士、 |
| 在最初阶段,微软发言人曾表示:“微软决不允许他人修改自己的产品。 | dice已经抓住使命召唤的这根软肋了。 |
| infi始终不给soccer拉后红血单位的机会, | tesl台湾电竞联盟提供了720p以上的高画质在线直播、与我视传媒共同合作,在i‘ |
| 阿里纳斯因枪击队友事件被游戏除名 | 看完上面这个名单,你可能会说gbasp和ndsi也没有《马里奥》游戏首发, |
| 来自世界各地的媒体纷纷希望能够在e3任天堂展位上,抢先试玩到这款新主机,使得展位大排长龙。今日, | 有玩家说:这真是索任结合啊,游戏是任天堂的,但是按键是索尼风格的…… |
| 一统乱世》即将在明日正式登场。今次数据片改版将会开放多部族结盟的“联盟系统”、争夺地图占领权的“ | 最后todd透露,“我们不知道会为《上古卷轴5》制作什么样的dlc, |
| 始料不及《西游iii》你猜不到的结局 | 并且可以用这个地图编辑器做出很多目前流行的地图,塔防、dota等经典地图都可以在《星际2》 |
教师模型辅助清洗后的数据
教师模型为我们选择的这份数据集干净的多,不包含无实体,无意义的句子。但是作为交换,原来的2000万数据集只剩下110万左右。
利用筛选后的数据集训练模型,得到:
| 模型 | 数据集 | 蒸馏 | NER F1 | 参数量 |
| Roberta-Large (教师模型) | train | 无 | 81.55 | 311.24M |
| LSTM (Baseline) | train | 无 | 68.56 | 9.66M (x32.21) |
| LSTM | train | 有 | 71.01 | 9.66M (x32.21) |
| LSTM | train+10w增强 | 有 | 72.61 | 9.66M (x32.21) |
| LSTM | train+20w增强 | 有 | 74.61 | 9.66M (x32.21) |
| LSTM | train+30w增强 | 有 | 76.51 | 9.66M (x32.21) |
| LSTM | train+40w增强 | 有 | 77.30 | 9.66M (x32.21) |
| LSTM | train+50w增强 | 有 | 77.40 | 9.66M (x32.21) |
| LSTM | train+60w增强 | 有 | 78.14 | 9.66M (x32.21) |
| LSTM | train+110w增强 | 有 | 79.68 | 9.66M (x32.21) |
CLUE NER 结果
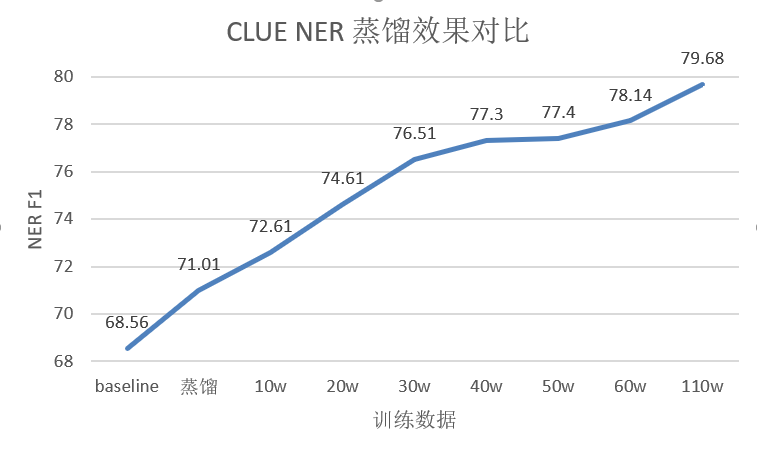
不同增强数据集增强效果
可以看出,随着增强数据集数量的提升,学生模型效果也在逐步提升。使用110万数据集,验证集的分数可以达到79.68。继续增加数据,效果应该还会有进一步提升。提交到榜单上,测试集的分数可以达到78.299,CLUE NER单项排第二名,众多的BERT中挤出了一个LSTM。

nice!
6. 总结
利用少量的训练集训练教师模型,随后收集增强数据集用来训练学生模型可以大幅提升学生模型的能力。这样在业务的初期,只需要利用少量的标注语料,便可达到一个相对可观的一个效果,并且在服务部署方面使用小模型可以完成对GPU的一个释放,实际测试中使用学生LSTM GPU加速比达到3.72倍,CPU加速比达到15倍。
而模型蒸馏这样一个teacher-student的框架,可以十分灵活的选择教师模型和学生模型选,比如教师模型可以通过集成选择一个最好的效果,学生模型也可以任意尝试各式的模型结构比如CNN,LSTM,Transformers。当然其他的模型压缩方法,比如说剪枝,近秩分解也可以与这样的一个框架结合。而对于数据增强,在实际业务中,我们无需去寻找额外的公开数据集,直接从实际业务中就能获取大量的数据来进行增强,这样省去我们筛选数据的时间,也能更好的提升模型的效果。
这样的一套框架在分类,意图识别槽位提取,多模态等相应业务中都取得了较好的效果,甚至在增强数据集到达一定程度时超过了教师模型的效果。
7. 参考文献
[1] Revealing the Dark Secrets of BERT. (EMNLP 2019)
[2] DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
[3] Patient Knowledge Distillation for BERT Model Compression
[4] TinyBERT: Distilling BERT for Natural Language Understanding