
5. LDA 文本建模
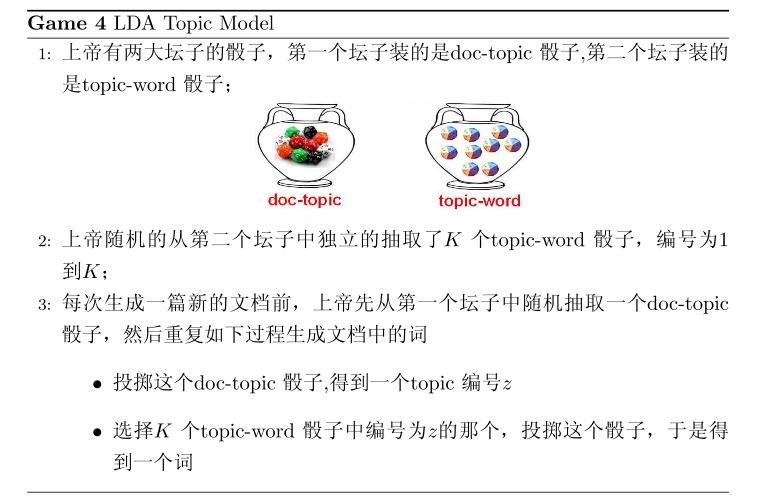
5.1 游戏规则
对于上述的 PLSA 模型,贝叶斯学派显然是有意见的,doc-topic 骰子$\overrightarrow{\theta}_m$和 topic-word 骰子$\overrightarrow{\varphi}_k$都是模型中的参数,参数都是随机变量,怎么能没有先验分布呢?于是,类似于对 Unigram Model 的贝叶斯改造, 我们也可以如下在两个骰子参数前加上先验分布从而把 PLSA 对应的游戏过程改造为一个贝叶斯的游戏过程。由于 $\overrightarrow{\varphi}_k$和$\overrightarrow{\theta}_m$都对应到多项分布,所以先验分布的一个好的选择就是Drichlet 分布,于是我们就得到了 LDA(Latent Dirichlet Allocation)模型。
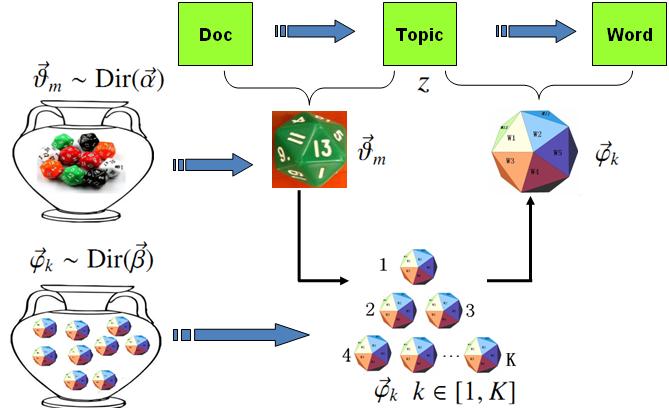 LDA模型
LDA模型
在 LDA 模型中, 上帝是按照如下的规则玩文档生成的游戏的
假设语料库中有 $M$ 篇文档,所有的的word和对应的 topic 如下表示
\begin{align*}
\overrightarrow{\mathbf{w}} & = (\overrightarrow{w}_1, \cdots, \overrightarrow{w}_M) \\
\overrightarrow{\mathbf{z}} & = (\overrightarrow{z}_1, \cdots, \overrightarrow{z}_M)
\end{align*}
其中, $\overrightarrow{w}_m$ 表示第$m$ 篇文档中的词, $\overrightarrow{z}_m$ 表示这些词对应的 topic 编号。
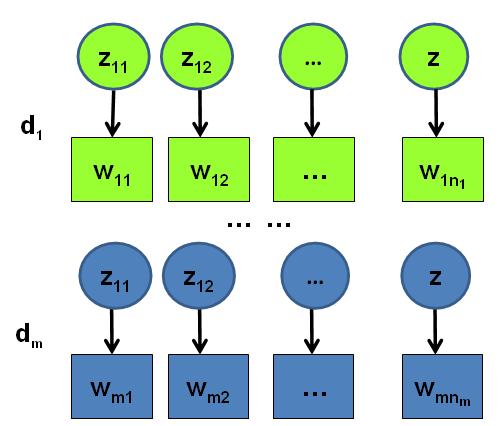 语料生成过程中的 word 和 topic
语料生成过程中的 word 和 topic
5.2 物理过程分解
使用概率图模型表示, LDA 模型的游戏过程如图所示。
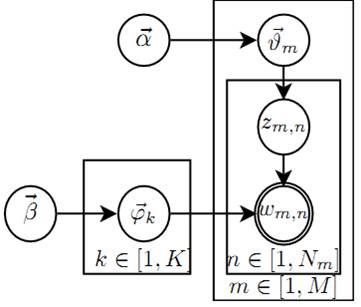 LDA概率图模型表示
LDA概率图模型表示
这个概率图可以分解为两个主要的物理过程:
- $\overrightarrow{\alpha}\rightarrow \overrightarrow{\theta}_m \rightarrow z_{m,n}$, 这个过程表示在生成第$m$ 篇文档的时候,先从第一个坛子中抽了一个doc-topic 骰子 $\overrightarrow{\theta}_m$, 然后投掷这个骰子生成了文档中第 $n$ 个词的topic编号$z_{m,n}$;
- $\overrightarrow{\beta} \rightarrow \overrightarrow{\varphi}_k \rightarrow w_{m,n} | k=z_{m,n}$, 这个过程表示用如下动作生成语料中第$m$篇文档的第 $n$个词:在上帝手头的$K$ 个topic-word 骰子 $\overrightarrow{\varphi}_k$ 中,挑选编号为 $k=z_{m,n}$的那个骰子进行投掷,然后生成 word $w_{m,n}$;
理解 LDA最重要的就是理解这两个物理过程。 LDA 模型在基于 $K$ 个 topic 生成语料中的 $M$ 篇文档的过程中, 由于是 bag-of-words 模型,有一些物理过程是相互独立可交换的。由此, LDA 生成模型中, $M$ 篇文档会对应于 $M$ 个独立的 Dirichlet-Multinomial 共轭结构; $K$ 个 topic 会对应于 $K$ 个独立的 Dirichlet-Multinomial 共轭结构。所以理解 LDA 所需要的所有数学就是理解 Dirichlet-Multiomail 共轭,其它都就是理解物理过程。现在我们进入细节, 来看看 LDA 模型是如何被分解为 $M+K$ 个Dirichlet-Multinomial 共轭结构的。
由第一个物理过程,我们知道 $\overrightarrow{\alpha}\rightarrow \overrightarrow{\theta}_m \rightarrow \overrightarrow{z}_{m}$ 表示生成第 $m$ 篇文档中的所有词对应的topics,显然 $\overrightarrow{\alpha}\rightarrow \overrightarrow{\theta}_m $ 对应于 Dirichlet 分布, $\overrightarrow{\theta}_m \rightarrow \overrightarrow{z}_{m}$ 对应于 Multinomial 分布, 所以整体是一个 Dirichlet-Multinomial 共轭结构;
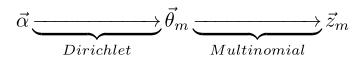
前文介绍 Bayesian Unigram Model 的小节中我们对 Dirichlet-Multinomial 共轭结构做了一些计算。借助于该小节中的结论,我们可以得到
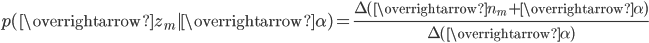
其中 $\overrightarrow{n}_m = (n_{m}^{(1)}, \cdots, n_{m}^{(K)})$, $n_{m}^{(k)}$ 表示第$m$篇文档中第$k$ 个topic 产生的词的个数。进一步,利用 Dirichlet-Multiomial 共轭结构,我们得到参数 $\overrightarrow{\theta}_m$ 的后验分布恰好是
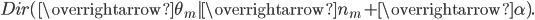
由于语料中 $M$篇文档的 topics 生成过程相互独立,所以我们得到 $M$ 个相互独立的 Dirichlet-Multinomial 共轭结构,从而我们可以得到整个语料中 topics 生成概率
\begin{align}
\label{corpus-topic-prob}
p(\overrightarrow{\mathbf{z}} |\overrightarrow{\alpha}) & = \prod_{m=1}^M p(\overrightarrow{z}_m |\overrightarrow{\alpha}) \notag \\
&= \prod_{m=1}^M \frac{\Delta(\overrightarrow{n}_m+\overrightarrow{\alpha})}{\Delta(\overrightarrow{\alpha})} \quad\quad (*)
\end{align}
目前为止,我们由$M$篇文档得到了 $M$ 个 Dirichlet-Multinomial 共轭结构,还有额外$K$ 个 Dirichlet-Multinomial 共轭结构在哪儿呢?在上帝按照之前的规则玩 LDA 游戏的时候,上帝是先完全处理完成一篇文档,再处理下一篇文档。文档中每个词的生成都要抛两次骰子,第一次抛一个doc-topic骰子得到 topic, 第二次抛一个topic-word骰子得到 word,每次生成每篇文档中的一个词的时候这两次抛骰子的动作是紧邻轮换进行的。如果语料中一共有 $N$ 个词,则上帝一共要抛 $2N$次骰子,轮换的抛doc-topic骰子和 topic-word骰子。但实际上有一些抛骰子的顺序是可以交换的,我们可以等价的调整$2N$次抛骰子的次序:前$N$次只抛doc-topic骰子得到语料中所有词的 topics,然后基于得到的每个词的 topic 编号,后$N$次只抛topic-word骰子生成 $N$ 个word。于是上帝在玩 LDA 游戏的时候,可以等价的按照如下过程进行:

以上游戏是先生成了语料中所有词的 topic, 然后对每个词在给定 topic 的条件下生成 word。在语料中所有词的 topic 已经生成的条件下,任何两个 word 的生成动作都是可交换的。于是我们把语料中的词进行交换,把具有相同 topic 的词放在一起
\begin{align*}
\overrightarrow{\mathbf{w}}' &= (\overrightarrow{w}_{(1)}, \cdots, \overrightarrow{w}_{(K)}) \\
\overrightarrow{\mathbf{z}}' &= (\overrightarrow{z}_{(1)}, \cdots, \overrightarrow{z}_{(K)})
\end{align*}
其中,$\overrightarrow{w}_{(k)}$ 表示这些词都是由第 $k$ 个 topic 生成的, $\overrightarrow{z}_{(k)}$ 对应于这些词的 topic 编号,所以$\overrightarrow{z}_{(k)}$中的分量都是$k$。
对应于概率图中的第二个物理过程 $\overrightarrow{\beta} \rightarrow \overrightarrow{\varphi}_k \rightarrow w_{m,n} | k=z_{m,n}$,在 $k=z_{m,n}$ 的限制下,语料中任何两个由 topic $k$ 生成的词都是可交换的,即便他们不再同一个文档中,所以我们此处不再考虑文档的概念,转而考虑由同一个 topic 生成的词。考虑如下过程 $\overrightarrow{\beta} \rightarrow \overrightarrow{\varphi}_k \rightarrow \overrightarrow{w}_{(k)}$ ,容易看出, 此时 $\overrightarrow{\beta} \rightarrow \overrightarrow{\varphi}_k $ 对应于 Dirichlet 分布, $ \overrightarrow{\varphi}_k \rightarrow \overrightarrow{w}_{(k)}$ 对应于 Multinomial 分布, 所以整体也还是一个 Dirichlet-Multinomial 共轭结构;
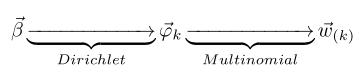
同样的,我们可以得到

其中 $\overrightarrow{n}_k = (n_{k}^{(1)}, \cdots, n_{k}^{(V)})$, $n_{k}^{(t)}$ 表示第$k$ 个topic 产生的词中 word $t$的个数。进一步,利用 Dirichlet-Multiomial 共轭结构,我们得到参数 $ \overrightarrow{\varphi}_k$ 的后验分布恰好是
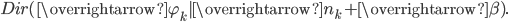
而语料中 $K$个 topics 生成words 的过程相互独立,所以我们得到 $K$ 个相互独立的 Dirichlet-Multinomial 共轭结构,从而我们可以得到整个语料中词生成概率
\begin{align}
\label{corpus-word-prob}
p(\overrightarrow{\mathbf{w}} |\overrightarrow{\mathbf{z}},\overrightarrow{\beta}) &= p(\overrightarrow{\mathbf{w}}' |\overrightarrow{\mathbf{z}}',\overrightarrow{\beta}) \notag \\
&= \prod_{k=1}^K p(\overrightarrow{w}_{(k)} | \overrightarrow{z}_{(k)}, \overrightarrow{\beta}) \notag \\
&= \prod_{k=1}^K \frac{\Delta(\overrightarrow{n}_k+\overrightarrow{\beta})}{\Delta(\overrightarrow{\beta})} \quad\quad (**)
\end{align}
结合 (*) 和 (**) 于是我们得到
\begin{align}
\label{lda-corpus-likelihood}
p(\overrightarrow{\mathbf{w}},\overrightarrow{\mathbf{z}} |\overrightarrow{\alpha}, \overrightarrow{\beta}) &=
p(\overrightarrow{\mathbf{w}} |\overrightarrow{\mathbf{z}}, \overrightarrow{\beta}) p(\overrightarrow{\mathbf{z}} |\overrightarrow{\alpha}) \notag \\
&= \prod_{k=1}^K \frac{\Delta(\overrightarrow{n}_k+\overrightarrow{\beta})}{\Delta(\overrightarrow{\beta})}
\prod_{m=1}^M \frac{\Delta(\overrightarrow{n}_m+\overrightarrow{\alpha})}{\Delta(\overrightarrow{\alpha})} \quad\quad (***)
\end{align}
此处的符号表示稍微不够严谨, 向量 $\overrightarrow{n}_k$, $\overrightarrow{n}_m$ 都用 $n$ 表示, 主要通过下标进行区分, $k$ 下标为 topic 编号, $m$ 下标为文档编号。
5.3 Gibbs Sampling
有了联合分布 $p(\overrightarrow{\mathbf{w}},\overrightarrow{\mathbf{z}})$, 万能的 MCMC 算法就可以发挥作用了!于是我们可以考虑使用 Gibbs Sampling 算法对这个分布进行采样。当然由于 $\overrightarrow{\mathbf{w}}$ 是观测到的已知数据,只有 $\overrightarrow{\mathbf{z}}$是隐含的变量,所以我们真正需要采样的是分布 $p(\overrightarrow{\mathbf{z}}|\overrightarrow{\mathbf{w}})$。在 Gregor Heinrich 那篇很有名的LDA 模型科普文章 Parameter estimation for text analysis 中,是基于 (***) 式推导 Gibbs Sampling 公式的。此小节中我们使用不同的方式,主要是基于 Dirichlet-Multinomial 共轭来推导 Gibbs Sampling 公式,这样对于理解采样中的概率物理过程有帮助。
语料库$\overrightarrow{\mathbf{z}}$ 中的第$i$个词我们记为$z_i$, 其中$i=(m,n)$是一个二维下标,对应于第$m$篇文档的第 $n$个词,我们用 $\neg i$ 表示去除下标为$i$的词。那么按照 Gibbs Sampling 算法的要求,我们要求得任一个坐标轴 $i$ 对应的条件分布 $p(z_i = k|\overrightarrow{\mathbf{z}}_{\neg i}, \overrightarrow{\mathbf{w}})$ 。假设已经观测到的词 $w_i = t$, 则由贝叶斯法则,我们容易得到
\begin{align*}
p(z_i = k|\overrightarrow{\mathbf{z}}_{\neg i}, \overrightarrow{\mathbf{w}}) \propto
p(z_i = k, w_i = t |\overrightarrow{\mathbf{z}}_{\neg i}, \overrightarrow{\mathbf{w}}_{\neg i}) \\
\end{align*}
由于$z_i = k, w_i = t$ 只涉及到第 $m$ 篇文档和第$k$个 topic,所以上式的条件概率计算中, 实际上也只会涉及到如下两个Dirichlet-Multinomial 共轭结构
- $\overrightarrow{\alpha} \rightarrow \overrightarrow{\theta}_m \rightarrow \overrightarrow{z}_{m}$
- $\overrightarrow{\beta} \rightarrow \overrightarrow{\varphi}_k \rightarrow \overrightarrow{w}_{(k)}$
其它的 $M+K-2$ 个 Dirichlet-Multinomial 共轭结构和$z_i = k, w_i = t$是独立的。
由于在语料去掉第$i$ 个词对应的 $(z_i, w_i)$,并不改变我们之前讨论的 $M+K$ 个 Dirichlet-Multinomial 共轭结构,只是某些地方的计数会减少。所以$\overrightarrow{\theta}_m, \overrightarrow{\varphi}_k$ 的后验分布都是 Dirichlet:
\begin{align*}
p(\overrightarrow{\theta}_m|\overrightarrow{\mathbf{z}}_{\neg i}, \overrightarrow{\mathbf{w}}_{\neg i})
&= Dir(\overrightarrow{\theta}_m| \overrightarrow{n}_{m,\neg i} + \overrightarrow{\alpha}) \\
p(\overrightarrow{\varphi}_k|\overrightarrow{\mathbf{z}}_{\neg i}, \overrightarrow{\mathbf{w}}_{\neg i})
&= Dir( \overrightarrow{\varphi}_k| \overrightarrow{n}_{k,\neg i} + \overrightarrow{\beta})
\end{align*}
使用上面两个式子,把以上想法综合一下,我们就得到了如下的 Gibbs Sampling 公式的推导
\begin{align*}
p(z_i = k|\overrightarrow{\mathbf{z}}_{\neg i}, \overrightarrow{\mathbf{w}}) & \propto
p(z_i = k, w_i = t |\overrightarrow{\mathbf{z}}_{\neg i}, \overrightarrow{\mathbf{w}}_{\neg i}) \\
&= \int p(z_i = k, w_i = t, \overrightarrow{\theta}_m,\overrightarrow{\varphi}_k |
\overrightarrow{\mathbf{z}}_{\neg i}, \overrightarrow{\mathbf{w}}_{\neg i}) d \overrightarrow{\theta}_m d \overrightarrow{\varphi}_k \\
&= \int p(z_i = k, \overrightarrow{\theta}_m|\overrightarrow{\mathbf{z}}_{\neg i}, \overrightarrow{\mathbf{w}}_{\neg i})
\cdot p(w_i = t, \overrightarrow{\varphi}_k | \overrightarrow{\mathbf{z}}_{\neg i}, \overrightarrow{\mathbf{w}}_{\neg i})
d \overrightarrow{\theta}_m d \overrightarrow{\varphi}_k \\
&= \int p(z_i = k |\overrightarrow{\theta}_m) p(\overrightarrow{\theta}_m|\overrightarrow{\mathbf{z}}_{\neg i}, \overrightarrow{\mathbf{w}}_{\neg i})
\cdot p(w_i = t |\overrightarrow{\varphi}_k) p(\overrightarrow{\varphi}_k|\overrightarrow{\mathbf{z}}_{\neg i}, \overrightarrow{\mathbf{w}}_{\neg i})
d \overrightarrow{\theta}_m d \overrightarrow{\varphi}_k \\
&= \int p(z_i = k |\overrightarrow{\theta}_m) Dir(\overrightarrow{\theta}_m| \overrightarrow{n}_{m,\neg i} + \overrightarrow{\alpha}) d \overrightarrow{\theta}_m \\
& \hspace{0.2cm} \cdot \int p(w_i = t |\overrightarrow{\varphi}_k) Dir( \overrightarrow{\varphi}_k| \overrightarrow{n}_{k,\neg i} + \overrightarrow{\beta}) d \overrightarrow{\varphi}_k \\
&= \int \theta_{mk} Dir(\overrightarrow{\theta}_m| \overrightarrow{n}_{m,\neg i} + \overrightarrow{\alpha}) d \overrightarrow{\theta}_m
\cdot \int \varphi_{kt} Dir( \overrightarrow{\varphi}_k| \overrightarrow{n}_{k,\neg i} + \overrightarrow{\beta}) d \overrightarrow{\varphi}_k \\
&= E(\theta_{mk}) \cdot E(\varphi_{kt}) \\
&= \hat{\theta}_{mk} \cdot \hat{\varphi}_{kt} \\
\label{gibbs-sampling-deduction}
\end{align*}
以上推导估计是整篇文章中最复杂的数学了,表面上看上去复杂,但是推导过程中的概率物理意义是简单明了的:$z_i = k, w_i = t $的概率只和两个 Dirichlet-Multinomail 共轭结构关联。而最终得到的 $\hat{\theta}_{mk}, \hat{\varphi}_{kt}$ 就是对应的两个 Dirichlet 后验分布在贝叶斯框架下的参数估计。借助于前面介绍的Dirichlet 参数估计的公式 ,我们有
\begin{align*}
\hat{\theta}_{mk} &= \frac{n_{m,\neg i}^{(k)} + \alpha_k}{\sum_{k=1}^K (n_{m,\neg i}^{(k)} + \alpha_k)} \\
\hat{\varphi}_{kt} &= \frac{n_{k,\neg i}^{(t)} + \beta_t}{\sum_{t=1}^V (n_{k,\neg i}^{(t)} + \beta_t)}
\end{align*}
于是,我们最终得到了 LDA 模型的 Gibbs Sampling 公式
\begin{equation}
\label{gibbs-sampling}
p(z_i = k|\overrightarrow{\mathbf{z}}_{\neg i}, \overrightarrow{\mathbf{w}}) \propto
\frac{n_{m,\neg i}^{(k)} + \alpha_k}{\sum_{k=1}^K (n_{m,\neg i}^{(k)} + \alpha_k)}
\cdot \frac{n_{k,\neg i}^{(t)} + \beta_t}{\sum_{t=1}^V (n_{k,\neg i}^{(t)} + \beta_t)}
\end{equation}
这个公式是很漂亮的, 右边其实就是 $p(topic|doc) \cdot p(word|topic)$,这个概率其实是 $doc \rightarrow topic \rightarrow word$ 的路径概率,由于topic 有$K$ 个,所以 Gibbs Sampling 公式的物理意义其实就是在这$K$ 条路径中进行采样。
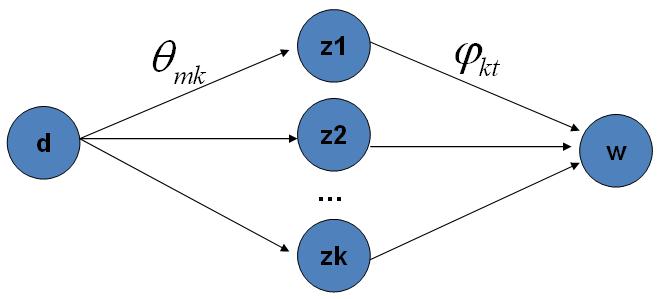 doc-topic-word 路径概率
doc-topic-word 路径概率
5.4 Training and Inference
有了 LDA 模型,当然我们的目标有两个
- 估计模型中的参数 $\overrightarrow{\varphi}_1, \cdots, \overrightarrow{\varphi}_K$ 和 $\overrightarrow{\theta}_1, \cdots, \overrightarrow{\theta}_M$;
- 对于新来的一篇文档$doc_{new}$,我们能够计算这篇文档的 topic 分布$\overrightarrow{\theta}_{new}$。
有了 Gibbs Sampling 公式, 我们就可以基于语料训练 LDA 模型,并应用训练得到的模型对新的文档进行 topic 语义分析。训练的过程就是获取语料中的 $(z,w)$ 的样本,而模型中的所有的参数都可以基于最终采样得到的样本进行估计。训练的流程很简单:

对于 Gibbs Sampling 算法实现的细节,请参考 Gregor Heinrich 的 Parameter estimation for text analysis 中对算法的描述,以及 PLDA(http://code.google.com/p/plda) 的代码实现,此处不再赘述。
由这个topic-word 频率矩阵我们可以计算每一个$p(word|topic)$概率,从而算出模型参数$\overrightarrow{\varphi}_1, \cdots, \overrightarrow{\varphi}_K$, 这就是上帝用的 $K$ 个 topic-word 骰子。当然,语料中的文档对应的骰子参数 $\overrightarrow{\theta}_1, \cdots, \overrightarrow{\theta}_M$ 在以上训练过程中也是可以计算出来的,只要在 Gibbs Sampling 收敛之后,统计每篇文档中的 topic 的频率分布,我们就可以计算每一个 $p(topic|doc)$ 概率,于是就可以计算出每一个$\overrightarrow{\theta}_m$。由于参数$\overrightarrow{\theta}_m$ 是和训练语料中的每篇文档相关的,对于我们理解新的文档并无用处,所以工程上最终存储 LDA 模型时候一般没有必要保留。通常,在 LDA 模型训练的过程中,我们是取 Gibbs Sampling 收敛之后的 $n$ 个迭代的结果进行平均来做参数估计,这样模型质量更高。
有了 LDA 的模型,对于新来的文档 $doc_{new}$, 我们如何做该文档的 topic 语义分布的计算呢?基本上 inference 的过程和 training 的过程完全类似。对于新的文档, 我们只要认为 Gibbs Sampling 公式中的 $\hat{\varphi}_{kt}$ 部分是稳定不变的,是由训练语料得到的模型提供的,所以采样过程中我们只要估计该文档的 topic 分布$\overrightarrow{\theta}_{new}$就好了。

6. 后记
LDA 对于专业做机器学习的兄弟而言,只能算是一个简单的Topic Model。但是对于互联网中做数据挖掘、语义分析的工程师,LDA 的门槛并不低。 LDA 典型的属于这样一种机器学习模型:要想理解它,需要比较多的数学背景,要在工程上进行实现,却相对简单。 Gregor Heinrich 的LDA 模型科普文章 Parameter estimation for text analysis 写得非常的出色,这是学习 LDA 的必看文章。不过即便是这篇文章,对于工程师也是有门槛的。我写的这个科普最好对照 Gregor Heinrich 的这篇文章来看, 我用的数学符号也是尽可能和这篇文章保持一致。
这份LDA 科普是基于给组内兄弟做报告的 ppt 整理而成的,说是科普其实也不简单,涉及到的数学还是太多。在工业界也混了几年,经常感觉到工程师对于学术界的玩的模型有很强的学习和尝试的欲望,只是学习成本往往太高。所以我写 LDA 的初衷就是写给工业界的工程师们看的,希望把学术界玩的一些模型用相对通俗的方式介绍给工程师;如果这个科普对于读研究生的一些兄弟姐妹也有所启发,只能说那是一个 side effect :-)。
我个人很喜欢LDA ,它是在文本建模中一个非常优雅的模型,相比于很多其它的贝叶斯模型, LDA 在数学推导上简洁优美。学术界自 2003 年以来也输出了很多基于LDA 的 Topic Model 的变体,要想理解这些更加高级的 Topic Model, 首先需要很好的理解标准的 LDA 模型。在工业界, Topic Model 在 Google、Baidu 等大公司的产品的语义分析中都有着重要的应用;所以Topic Model 对于工程师而言,这是一个很有应用价值、值得学习的模型。我接触 Topic Model 的时间不长,主要是由于2年前和 PLDA 的作者 Wangyi 一起合作的过程中,从他身上学到了很多 Topic Model 方面的知识。关于 LDA 的相关知识,其实可以写的还有很多:如何提高 LDA Gibbs Sampling 的速度、如何优化超参数、如何做大规模并行化、LDA 的应用、LDA 的各种变体...... 不过我的主要目标还是科普如何理解标准的LDA 模型。
学习一个模型的时候我喜欢追根溯源,常常希望把模型中的每一个数学推导的细节搞明白,把公式的物理意义想清楚,不过数学推导本身并不是我想要的,把数学推导还原为物理过程才是我乐意做的事。最后引用一下物理学家费曼的名言结束 LDA 的数学科普:
What I cannot create, I do not understand.
--- Richard Feynman
开头是不是应该:doc-topic 骰子 θ 和 topic-word 骰子φ
[回复]
rickjin 回复:
3 2 月, 2013 at 17:14
嗯,笔误,修复了 🙂
谢谢一路捧场!
[回复]
看完了,写的太好了这一系列。也看过WangYi之前写的一个推导的文档。大赞。What I cannot create, I do not understand.
[回复]
cttet 回复:
5 2 月, 2013 at 12:23
从你的博客跟过来的,真实一系列的好文啊。。
[回复]
你好,看了你的文章。收益颇深。这一阵我在研究topic model和LDA,对于LDA,模型评价perplexity是怎么计算的?大致物理意义你能简要解释下吗?
[回复]
rickjin 回复:
18 2 月, 2013 at 13:26
有了模型, 每个词的概率如下计算 $P(w) = \sum_z P(z, w) = \sum_z P(z) P(w|z)$ ,由于是 bag-of-words 模型, 语料的Likelihood就是所有词相乘, 这样就可以计算 perplexity 了。
[回复]
eacl 回复:
27 3 月, 2013 at 10:11
p(z)?? p(z|d) over d ??
[回复]
rickjin 回复:
29 3 月, 2013 at 12:40
你说得对, 应该用 p(z|d), 我写得有问题
youthon 回复:
17 9 月, 2013 at 14:17
您说的“每个词的概率如下”有点不理解,意思是说把一篇文档中的n个词,分别计算p(w)么?为什么不是算p(d)?而是算一篇文档中多个p(w)的乘积
[回复]
嫄 回复:
20 11 月, 2013 at 11:56
而且在传统的lda中,计算p(wd)需要遍历整个p(z|d)空间,也就是所有的p(z|d)分布的可能性。但通过估计的话,p(z|d)分布是一定的。这两个地方矛盾呢。请指教啊~
[回复]
谢谢rickjin的一路讲解。对于最后一句话,不是很理解其中的含义,What I cannot create, I do not understand.。望能给以点拨。
[回复]
rickjin 回复:
18 2 月, 2013 at 23:21
这句话的字面意思是:我无法创造的东西,我就没有理解它的本质。这句话我用在这里想表达的意思是:如果我们无法从细节上把LDA 模型从无到有的推导出来,那我们并没有真正的理解 LDA。当然学习其它理论也一样 🙂
[回复]
先謝謝rickjin精闢的解釋LDA的理論與處理步驟, 實在是惠我良多
但就是對於Daichi Mochihashi在matlab版本中處理好的alpha與beta部分仍然不太清楚
他將最後近似θ與φ的alpha與beta輸出後, 以我的認知為此語料庫中之doc→topic與topic→word向量矩陣
若將用於與PLSA、LSA等輸出矩陣評比時, 該怎麼操作才是對的?
因為LDA的輸出不同於PLSA為PWD矩陣, 深感困惑..
[回复]
麥子 回复:
27 2 月, 2013 at 04:32
先谢谢rickjin精辟的解释LDA的理论与处理步骤, 实在是惠我良多
但就是对于Daichi Mochihashi在matlab版本中处理好的alpha与beta部分仍然不太清楚
他将最后近似θ与φ的alpha与beta输出后, 以我的认知为此语料库中之doc→topic与topic→word向量矩阵
若将用于与PLSA、LSA等输出矩阵评比时, 该怎么操作才是对的?
因为LDA的输出不同于PLSA为PWD矩阵, 深感困惑..
ps. 抱歉, 忘记将语言转为简体字了
[回复]
rickjin 回复:
27 2 月, 2013 at 12:32
一般的 LDA model 训练过程中, 往往使用人工指定 $\alpah, \beta$ 超参数, 但是这些超参数其实是一个用最大似然估计去估计一个好的参数的, 这个可以参阅 Hanna Wallach 的 rethinking LDA 这篇 paper, 和 他的 PhD paper, 尤其是他的 PhD thesis, 给出了优化超参数的很多数学细节
[回复]
这几天一直对Training的部分有些疑惑,现在有些想明白了。这个Gibbs Sampling的Training其实用的应该是一种不动点收敛?请问各位大大,这个东西哪里有比较系统的介绍么?
[回复]
真是受益良多啊,但有些地方还是不太懂,比如=∫p(zi=k,wi=t,θ→m,φ→k|z→¬i,w→¬i)dθ→mdφ→k
=∫p(zi=k,θ→m|z→¬i,w→¬i)⋅p(wi=t,φ→k|z→¬i,w→¬i)dθ→mdφ→k
=∫p(zi=k|θ→m)p(θ→m|z→¬i,w→¬i)⋅p(wi=t|φ→k)p(φ→k|z→¬i,w→¬i)dθ→mdφ→k
感觉中间有点突然,是假设给定z→¬i,w→¬i的情况下,zi=k,wi=t条件独立么?
[回复]
你好!看了你的文章感觉十分有用。现在想问问在输入新文章测试时的具体步骤,我现在在测试时遇到一些问题,求指教!
[回复]
perplexity 具体怎么计算还是不太明白啊
“你说得对, 应该用 p(z|d), 我写得有问题”
[回复]
你好,请问perplexity计算公式中的p(z|d)中的d应该是测试文本,那它的 p(z|d)应该是未知的啊,怎么计算?
[回复]
牛牛110 回复:
7 11 月, 2013 at 11:05
p(z|d)不就是主题在文本上的分布吗?不都已经求出来了?
[回复]
lovewr 回复:
11 11 月, 2013 at 09:39
根据一些文献上说:模型估计在训练集上做,计算困惑度在测试集上进行,评价模型的泛化能力。
[回复]
Joe Fok 回复:
18 11 月, 2014 at 10:58
对啊,那个p(z|d)对于测试集来说是未知的啊,应该怎么求?
请问楼主有无中文的训练语料作LDA训练使用
[回复]
文章在推导(2)式的时候有一个小错误,K个topic总共的概率应该是先相乘再积分,作者分别对每个topic的概率先积分再将所有topic的概率相乘。
[回复]
你好!看了你的文章感觉十分有用。以前只是比较懵懂地使用了LDA模型,现在终于对内部的数学概率知识有了深入的了解!非常感谢!
[回复]
你好,我是LDA的初学者,有几个疑问想请教一下:主题模型得到的最终结果不应该是主题吗?由两个参数最后怎么求文章主题?
[回复]
靳老师你好,看了好多遍《Lda数学八卦》,一直有个疑惑的点,在Game5下面,也就是讲解K个Dirichlet-Multinomial 共轭结构那段,一直很疑惑那对改变了的向量组w',z'的长成什么样的。
"其中,w→(k) 表示这些词都是由第 k 个 topic 生成的, z→(k) 对应于这些词的 topic 编号,所以z→(k)中的分量都是k。"
这里把语料中的词进行交换,把具有相同 topic 的词放在一起,z→(k)中的分量不是m??是长成z→(k)=(z(k)_m1,z(k)_m2,...)这样的吗?
希望能得到老师的解答,谢谢!
[回复]
吉布斯采样那部分没看懂,吉布斯采样是用来对已知概率密度进行采样,但是这个地方 隐含主题的后验概率 虽然形式已知(两个Dirichlet 参数估计的乘积),但是因为没有准确的隐含主题的准确标注所以 隐含主题的后验概率函数 还是未知的。怎么证明在概率密度函数未知的情况下,吉布斯采样最终收敛的一定就是正确的?而且只有在采样的变量同时也是概率密度函数的参数的时候才可以进行这样的吉布斯采样来预估参数吧?这个操作在什么情况时是通用的?
[回复]