
光学字符识别OCR技术(Optical Character Recognition)是指从图像中自动提取文字信息的技术。这项技术横跨了人工智能里的两大领域:CV(计算机视觉)和NLP(自然语言处理),综合使用了这两大领域中的很多技术成果。
在过往40余年的技术发展历程中,OCR始终具备很强的产业应用背景,是计算机领域里少数几个一开始就由工业界和学术界双轮驱动的领域。近年来OCR技术已经在工业界成熟落地应用,学术界里对此的研究热度反而弱于其他方向。甚至有人认为OCR技术已经充分成熟,没有更多研究必要了。然而随着近年来智能文本处理IDP(Intelligent Document Processing)在工业界的逐步落地应用,OCR和IDP相结合的应用场景越来越多,用语义理解NLP的角度进一步去延伸OCR的应用,出现了很多更有产业应用价值的场景。本文回顾了OCR技术的发展历程,并结合达观数据在工程实践方面的经验,介绍与语义分析技术结合后,当前OCR技术的一些最新发展和落地经验。
OCR技术的发展历程
OCR技术的诞生其实比计算机的历史还要悠久,早在1930年代,德国发明家Tausheck(陶舍克)和美国工程师Handel(汉德)分别申请了最早的OCR专利,这比计算机的诞生还要早20年时间。因为当年还完全没有计算机以及相关外设(如今天广泛使用的扫描仪或高拍仪),所以最早提出的OCR技术采用的是机械掩模和模板匹配的方法来处理打字机输出的文档。当时的技术雏形离实际应用还比较遥远。
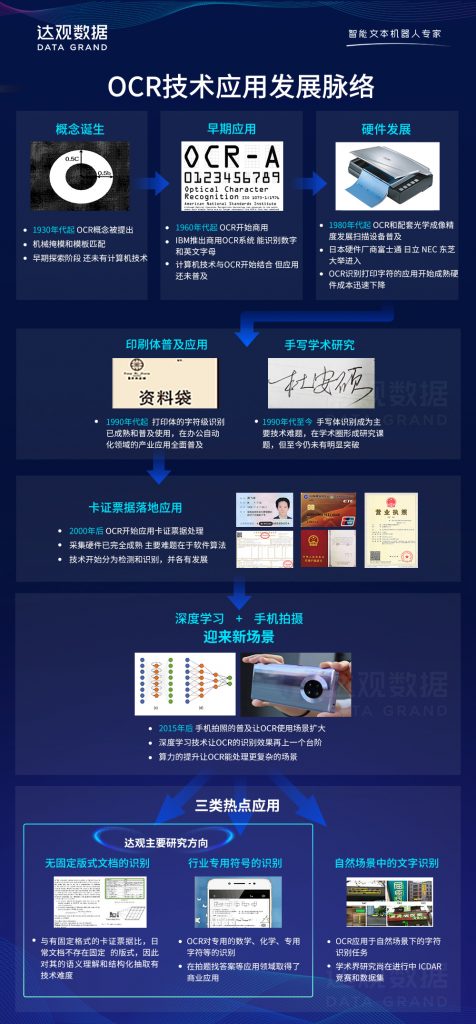
OCR技术真正开始进入办公应用是到了1960年代,引领这项技术的是美国IBM公司。随着二战后美国经济的腾飞,计算机开始进入企业办公领域,在一些日常处理量大且步骤繁琐的场景下OCR开始发挥应用价值。例如1965年纽约世博会展出的IBM1287机器就能自动识别英文字母和数字,且准确率很高。此后逐步被用于一些订单编号的识别派发,和信封邮政编码的识别和邮件分拣等任务中。
1980年代起,随着日本经济尤其是电子技术的飞跃,富士通、日立、东芝、NEC等日本科技公司纷纷入场。这个时期的研究特点是图像采集的电子器件得到快速发展,光栅扫描、成像、电子化图像传输等信号采集技术成长迅速,相应的轮廓提取、结构分析等软件算法也开始出现。
在以精密电器制造见长的日本企业推动下,扫描仪等采集设备的效果、速度、成本有了长足的进步,对标准打印字符的识别效果越来越好,OCR系统开始普及应用。和其他很多高科技领域里“先从大学有了早期理论研究突破,然后逐步在产业界孵化出实用系统”的方式不同,在这个阶段,OCR技术始终是由工业界主导并取得了良好的应用效果。唯一的例外是对手写字符的识别。因为手写字符的变化太大,各种连笔、涂改、变形等让计算机辨认确实太难(甚至过于潦草的情况下让人辨识都很难),所以作为OCR领域的研究分支,成为了学术界的一个研究热点。尤其1990年代模式识别(Pattern Recognition)兴起,激发了学术研究界对手写字符识别的热情。此时出现大名鼎鼎的MNIST数据集,由美国国家标准与技术研究所(NIST,National Institute of Standards and Technology)发起整理了来自250个不同人的手写数字图片。
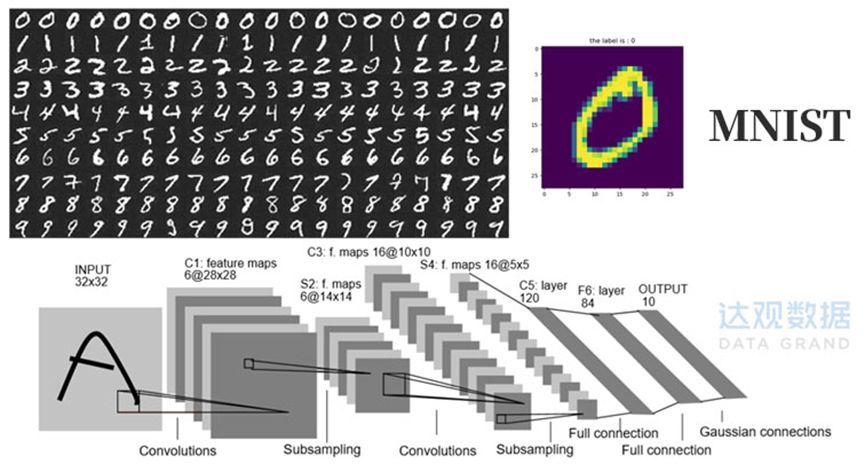 MNIST是OCR乃至模式分类领域最知名的入门数据集
MNIST是OCR乃至模式分类领域最知名的入门数据集
此后大量的模式分类以及图像处理论文都以MNIST作为基础,进行各类特征抽取和模式分类的算法研究。至今一些大学人工智能的入门课程还会用MNIST数据集来跑试验,可谓经久不衰。
为什么只有手写字符集,不搞打印字符测试数据集?因为对打印字符的识别准确率已经极高(99.9%以上),没有科研必要了……
此处顺便一提,百度创始人李彦宏1996年在美国IDD公司工作时也参与了OCR技术研究,其中一篇优秀的研究成果发表在机器学习界知名学术期刊IEEE Transaction PAMI上。
 百度李彦宏的OCR论文,发表于IEEE Trans on PAMI
百度李彦宏的OCR论文,发表于IEEE Trans on PAMI
21世纪后,OCR被进一步应用于各行各业里卡证票据的识别。针对的是日常生活中频繁使用到的发票、身份证、银行卡、营业执照、房产证、驾驶证、汽车牌照等实体证件。在这个阶段,图像扫描技术已经高度成熟了,所以技术研究基本集中在软件算法方面,并细分为信息检测(Detection)和识别(Recognition)两个技术分支分别发展,本文后面有更详细的技术介绍。
因为大部分常见的卡证票据都有相对固定的格式布局,所以通常只需要有足够多的训练样本,通过样本标注生成元素的模板定位,就能解决绝大部分问题,不用大费周折使用“智能化”的检测算法。通俗地说,这类应用场景是”数据为王”。
自2015年之后OCR技术和应用又迎来了巨大的变化,这次主要来自两个因素的推动。第一个因素是移动手机拍照的普及。在此之前,OCR的图像通常来自于扫描仪、高拍仪等企业级专用采集设备,图像的质量非常高,但因为固定在办公桌面使用,不够方便灵活,限制了应用场景,所以此前的OCR集中于企业级商用。而智能手机的迅速普及,让我们每个人都有了一个“拍摄+上传”的一体化终端,为OCR的应用普及带来了新的历史机遇,随之而来产生了很多新的应用场景。例如各种个人证照、文件等的自助式拍摄和上传,用于远程申报和审批等事项,或者拍摄并识别文件进行内容自动处理等创新场景(例如教育领域的拍题搜答案等)。
这个因素也随之带来了一些新的技术问题,例如手机因为拍摄相对随意,个人拍摄的水平参差不齐,会导致图像存在阴影遮挡、角度畸变、失焦模糊等等一堆新的问题。也相应产生了一批解决这些问题的工程手段。(达观数据陈运文)
另一个重要因素来自深度学习技术的巨大理论突破。在深度神经网络的旋风刮到OCR领域之前,用于检测和识别的技术可谓是百花齐放,例如各种各样的信号处理(例如Fourier、Radon、Hough、Zernike)特征提炼方法、图像结构的方法(交叉线、圆圈、横竖线条)、各种算子(如SIFT、SURF、各类卷积算子等)等、以及各种映射技术等。针对一些专用的字符类型和特殊应用场景,还有专门构造的人工特征提取技术。
但深度学习时代里通过多层网络结构来自动进行特征学习,颠覆了这些传统的人工特征提取过程,效果也有明显的改善。近年来学术界的论文已经是神经网络一统江湖了。加上之前限制深度学习的算力成本大幅度降低,新的更复杂的网络结构层出不穷,将OCR技术的效果不断推上新的台阶。
在“智能手机+深度学习”这两个因素共同助推下,近年来OCR技术的研发迎来了三个新的热点方向,分别是:
- OCR与智能文本处理(IDP)相结合,进行无固定格式文档的语义理解和结构化解析,不仅识别文字本身,而且理解文字的版面、结构、表格元素、段落内容等,从而完成对文本要素信息的还原和结构化抽取工作,并用于智能文档审阅处理等场景
- OCR与专业领域的符号识别相结合,如数学公式符号、物理公式、化学分子结构图、建筑图纸等等,实现专业领域的应用,如拍图搜题,图纸审核等场景
- OCR与开放场景的文字识别相结合(常称为STR,Scene Text Recognition),例如路牌、店面招牌、商标文字、户外广告识别等,用于交通、户外消费、自动驾驶等场景
这三类当前的热点应用,都有各自的技术难点,也分别衍生出了相应的产品技术解决方案。其中OCR与IDP的结合是目前达观数据的主要研究和应用方向,接下来会进行一些技术分享。
OCR技术的发展情况
当前学术界普遍将OCR处理分为 图像预处理、文本检测(Detection)、文本识别(Recognition)这三大步骤,或者也有将检测和识别合并,直接用端到端学习(End-to-End)进行处理工作。
图像预处理用于对待处理的原始图像进行一些矫正操作,以助于降低后续的检测和识别难度。例如使用一些工程化技术来调整图像对比度、旋转对齐、进行局部裁剪、折痕和墨点等干扰信息的淡化等都属于相对基础的预处理操作。因为在使用高拍仪或扫描仪等专业采集设备时,图像品质普遍较好,所以在2010年以前对图像预处理方面的系统性的研究并不多,更多集中于对局部的畸变进行校正(Image Rectifier)或图像去噪。
经典的图像预处理经常用到各类滤波器(如高斯滤波、BM3D等)进行去噪,另外一些信号处理手段也常用于对图像进行旋转对齐,横平竖直的文档会让后续的检测和识别变得容易得多。
智能手机拍摄普及后,光照不均匀、阴影遮挡、局部扭曲、甚至对焦模糊等复杂情况层出不穷,所以在实际工程应用中,图像预处理的好坏对后续识别精度价值很大,尽管这个环节作为OCR的一个非核心环节,受到学术圈的重视较少,各大学术会议上也几乎罕见这方面的研究论文(近年有几篇不错的Text deblurring论文)。但学术和工程的目标是不一样的,工程应用要在琐碎中见真章,会配置很多业务规则和处理步骤。
顺便一提,为了增加标注样本的数量,提升算法在不同场景下的鲁棒性,生成对抗网络(GAN)的思想在OCR的样本生成方面也很常用。尤其在标注样本不充足的情况下,用GAN网络结合人工标注和积累的真实样本,日拱一卒不断扩大训练样本库,也是常用的做法。
文本检测是OCR的最重要环节之一(另一个是文本识别),传统的文本检测使用了各种人工构造的特征,例如常见的二值投影、旋转仿射变换、各类图像算子如HoG算子、SURF算子,DPM模型(Deformable Parts Model)等来定位文本行列位置。在2010年前最常见的技术手段为滑动窗口检测、或基于连通区域检测的方法,由下而上逐步拟合出文本块。
因为构造特征的过程偏定制,很难针对不同的文档类型形成大而全的普适方案。在具有特定结构规律的OCR领域,尤其是卡证票据这类常见检测应用场景,传统的模板+滑动窗口定位检测的方法是管用的。
近10年来随着深度学习技术的飞速发展,多种多样的神经网络结构(如称为XXNET或XXNN)的检测效果明显优于传统人工构造的特征,当前主流的检测技术由深度学习来主导。
文本检测中常见的思想有两大类,一类是基于回归的方法,另一类是基于分割的方法。
基于回归的检测方法,基本思路是先利用若干个默认锚点(Anchor),然后想办法进行合并形成文字框box。2016年ECCV发表的CTPN是基于回归思想的经典技术(Detecting Text in Natural Image with Connectionist Text Proposal Network,论文出自中科院,为我们中国研究者点赞)。
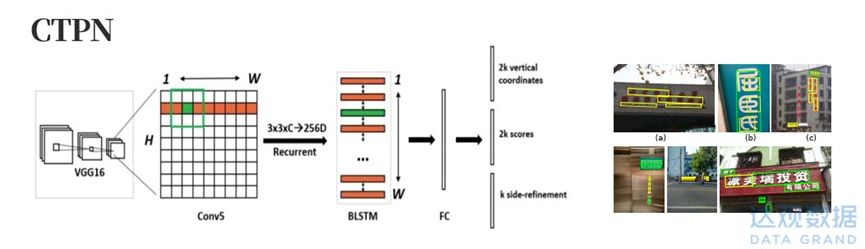 CTPN是基于回归的文本检测中的经典方法
CTPN是基于回归的文本检测中的经典方法
CTPN综合了CNN和LSTM的网络特性,在假设文本已经是水平横向分布的前提条件下,做了以下步骤的操作:
- VGG16位backbone提取空间特征,取conv5层输出特征
- 在垂直vertical方向进行feature map,并进行reshape
- 引入Bi-LSTM,从而更好地利用文字连贯性的特征来提升检测效果
- 使用类似Faster R-CNN的RPN网络获得text proposals
- 对获得的大量text proposals,使用NMS(Non-Maximum Suppression,非极大值抑制),或改进后的Soft NMS,Weighted NMS等,过滤和合并文本框。(这个阶段的工作和通用的目标检测任务相似)
- 对得到的水平方向的文本小框合成一个完整的横向文本行,并针对少量倾斜情况做一些矫正
CTPN综合了上述若干种网络结构的优点,有优秀的检测效果,尤其对边框矩形的四个顶点的识别很准确,对OCR检测技术的后续发展有承前启后的意义。例如此后的SegLink算法沿用了CTPN的思想,并引入了SSD和旋转角度学习的方法,来解决CTPN遗留的多角度文本检测的问题。
基于回归的方法对相对工整(横平竖直)的书面文档文本的检测效果很好,但对各类自然场景下的文本的检测效果难以保障(例如各类弯曲形变的店铺招牌)。所以有另一类思想是源于图像分割(image segmentation)的方法来进行文本检测,即:
先从像素层面做分类,判别每一个像素点是否属于一个文本目标,得到文本区域的概率图,然后利用polygon等来绘制出这些候选区域的最小包围曲线,相当于把一堆散落的像素块像串联珍珠那样,链接到一起来形成边界框。
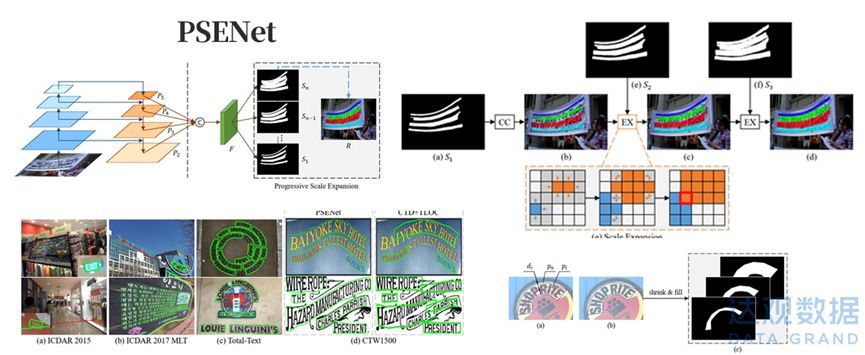 PSENet网络是基于分割的文本检测技术,对明显弯曲的文本有良好效果
PSENet网络是基于分割的文本检测技术,对明显弯曲的文本有良好效果
基于分割的方面近年优秀的成果包括2019年南京大学等组成的研究团队发表于CVPR的PSENet网络,通过渐进式的尺度扩张网络(Progressive Scale Expansion)来学习文本分割区域,其主干网络本质是ResNet,通过使用不同尺度的Kernel,预测不同收缩比例的文本区域,并逐个扩大检测到的文本区域。
PSENet的实质是边界学习方法的变体,可以有效解决任意形状相邻文本的检测问题。具体如网络结构和检测效果如上图所示。
2021年华南理工大学在CVPR提出的FCENet,提出了用傅里叶变换来对文本外围的包络线进行参数表示的方法,通过设计合适的模型预测来拟合任意形状文本包围框,从而实现自然场景文本检测中对于高度弯曲文本实例的检测精度的提升。
在图像处理和模式识别界最近几年知名国际学术会议,如CVPR、ICCV,AAAI或ICDAR上,每年都有一些最新的网络改进模型被提出(且大量优秀成果都来自中国本土的科研团队,可喜可贺),以下是几篇值得延伸阅读的论文。
- CTPN(Detecting Text in Natural Image with Connectionist Text Proposal Network,ECCV2016)
- SegLink(Detecting Oriented Text in Natural Images by Linking Segments,CVPR2017)
- EAST(EAST: An Efficient and Accurate Scene Text Detector,CVPR2017)
- PSENet(Shape Robust Text Detection with Progressive Scale Expansion Network,CVPR2019)
- DBNet(Real-time Scene Text Detection with Differentiable Binarization,AAAI2019)
- FCENet(Fourier Contour Embedding for Arbitrary-Shaped Text Detection,CVPR2021)
文本识别技术
CRNN网络(循环卷积神经网络)是识别领域里最为经典的方法,直至今日仍然被广泛使用。CRNN网络的技术思想是用深度卷积Convolutional来生成图像基础特征,再使用Bi-LSTM循环网络(双向长短时记忆网络,能吸收上下文语义信息)进行时序特征训练(这一步利用文本序列的前后特征能有效提升效果),最后引入CTC损失函数来实现端对端的不定长序列识别,解决训练时字符无法对齐的问题。
论文原文见:An End-to-End Trainable Neural Network for Image-based
Sequence Recognition and Its Application to Scene Text Recognition,值得一提的是CRNN由华中科技大学白翔老师团队提出,在OCR领域是极为优秀的研究成果。
近年来随着Attention机制在NLP领域取得了很好的效果,将CRNN和Attention结合也成为OCR识别的新思路,在CRNN网络输出层之后加上attention机制,把GRU网络的输出作为encoder的输入,对其做attention,并通过softmax输出,也有非常优异的效果。
此处特别值得推荐的是来自NAVER的OCR团队hwalsuklee同学Github上汇总的OCR知识库:https://github.com/hwalsuklee/awesome-deep-text-detection-recognition
其中包括了近几年学术界在OCR检测和识别领域的一些知名论文、ICDAR的数据测试集评分和部分开源代码,对系统性了解学术界在OCR领域的成果很有帮助,推荐感兴趣的朋友们阅读,是一个非常好的资料学习库。
OCR的工程应用开发:从OCR到OCR Pro
在当前学术圈,OCR研究的热点集中在室外自然场景下的应用。因为这些工作的难度高,效果还不太好,商业化应用还在早期,所以学术研究很热(技术成熟并大量工程应用的领域反而理论研究就会变少),每年都有很多论文发表。这些自然场景STR工作其实和自然语言理解的关系不大,而和计算机视觉(CV)更接近,尤其是通用目标检测(Object Detection)。甚至很多自然场景下的OCR算法干脆就借用了end-to-end的通用框架,例如Yolo这类大名鼎鼎的通用检测系统。
而在实际OCR的落地应用界,“卡证票据”的识别已经非常成熟,所以当前的应用热点集中在无固定格式文档的识别和理解上。
下图解释了有固定格式的“卡证票据”的处理,和无固定格式的文档资料处理的差异。
 无固定格式的文档资料OCR是当前应用的热点和难点
无固定格式的文档资料OCR是当前应用的热点和难点
“卡证票据”的特点是格式相对明确和固定(例如身份证,姓名、性别、身份证号等各个信息的位置是明确的),所以检测(Detection)和识别(Recognition)要容易的多,通过设定模板来检测定位,进而进行文字识别来输出各类Key:Value型的结构化抽取结果是相对容易的。
而我们日常办公所经常面对的无固定格式的文档资料,因为版式变化多样,需要进行提取的内容可能分布在不同的位置,因而很难简单用模板匹配的方式来进行检测、识别、抽取三个动作,需要更复杂的操作步骤,我们称为OCR Pro系统。
针对无固定格式的OCR Pro系统,一个待处理的文档图片(扫描件或手机翻拍件)要依次进行版面分析(Layout Analysis),文字识别(Recognition)、信息提取(Intelligent Document Processing)、行业知识校验(Domain Knowledge Recheck)等步骤。
使用版面分析的原因是日常办公文档的构成元素非常复杂,不仅有常见的文字块,还会出现标题、目录、印章、签名、表格、图例、页眉页脚等各类元素,版面分析技术的目的就是要通过页面各类元素信息的视觉特征、结合文本语义特征和各类embedding信号,将文档“庖丁解牛”分解为若干元素,为后续的识别和结构化抽取打好基础。
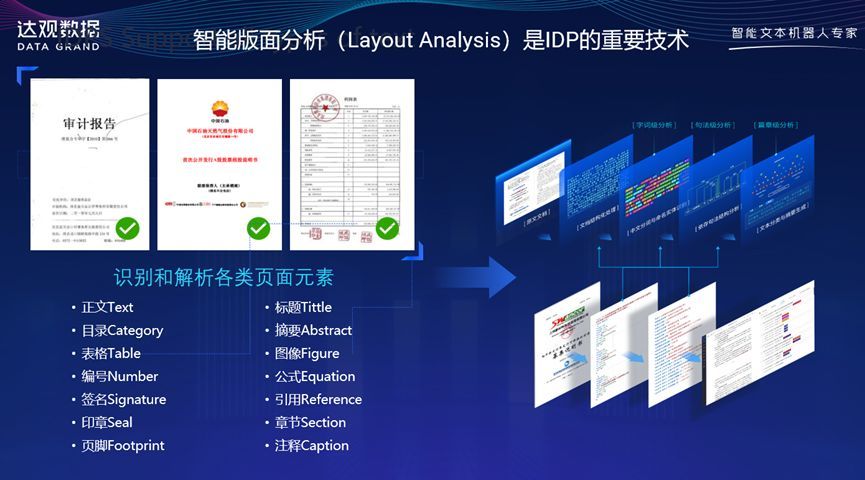 版面分析技术在OCR和IDP中有重大意义
版面分析技术在OCR和IDP中有重大意义
在版面分析中,有一类常见且重要的特殊元素——表格。因为OCR的最终目的是将文档里最关键的内容自动化提取出来,表格中往往包含非常密集的重要信息,因此对表格的解析和语义理解技术相对更为特殊,在后面的章节中将进一步对该技术进行详细介绍。
和自然场景下(in the wild)的OCR检测不同,针对办公文档的OCR因为文字的横竖布局以及背景图片质量明显比自然场景的图片要高得多,也用不着太多来自于通用目标检测(Object Detection)的技巧。在办公文档OCR的实际产业应用里,版面分析技术事实上代替了文本检测技术发挥实际作用。
文档处理环节里的文字识别则技术相对成熟,因为大部分文字都以打印字符的形式存在,通常情况下这个环节下的文字识别技术已经非常成熟和准确了。当前达观的一些研究主要分布在以下一些相对特殊的场合:
01 去除文档的底纹或水印干扰
工作文档采用带有底纹的特殊纸张,或者有的人为打上水印(例如一些重大项目的投标书)。
02 提取和理解关键性元素
书面文本处理中存在一些特殊种类的元素,例如印章、手写签名等元素就是国内(包括东亚地区各国家)合同里极为重要的组成部分,需要专门的模型进行处理。而且还需要对印章的文字内容进行提取和识别(通常为圆形),并用于后续和合同里签署主体进行对比审核。手写签名提取后也会用于进行比对。
03 识别和处理特殊符号
书面文档中经常有一些表达语义的专用符号,如√(对勾)、编号①、角标(常见于注释提示)、下标(常见于数理化公式)等。
达观OCR的工程化实践
要开发出真正可以落地使用的OCR产品,需要面对真实使用情况里多种多样的问题。这些问题往往显得非常的琐碎,但是只有实实在在把这些琐碎的问题解决好,才能让产品落地好用。
就以最为常见的表格的OCR解析为例,其实我们日常文档中遇到的表格情况非常多,以下图为例,这些表格存在各类分栏,水印、跨页、揉搓、阴影、印章遮挡等各种各样的问题,需要逐一有技术来应对。(达观数据陈运文)
另外表格中还存在无边框表格(常见于一些上市公司财报),或单元格嵌套的复杂表格(常见于一些复杂行政审批事项填报表),都需要进行处理。如下图所示。
 达观数据对表格的OCR处理和语义理解
达观数据对表格的OCR处理和语义理解
近年来基于深度学习的表格检测和识别算法在ICDAR(International Conference on Document Analysis and Recognition)会议上有很多原创性的成果,如A Genetic-based Search for Adaptive Table Recognition in Spreadsheets论文所提出的方法,将表格中的单元格分为Header、Data和Metadata等类型,然后相邻单元格根据标签异同组成不同的区域,这些区域根据相邻关系则构成了一个标签区域图,巧妙的将表格结构识别任务变成了子图分割任务,方法接着定义了将10个衡量因素加权求和来评判分割质量,用于确定优化目标。然后使用序列二次规划的方法来自动调节权重,并综合运用了遗传算法和一些启发式方法、或穷举搜索等来进行最优化。
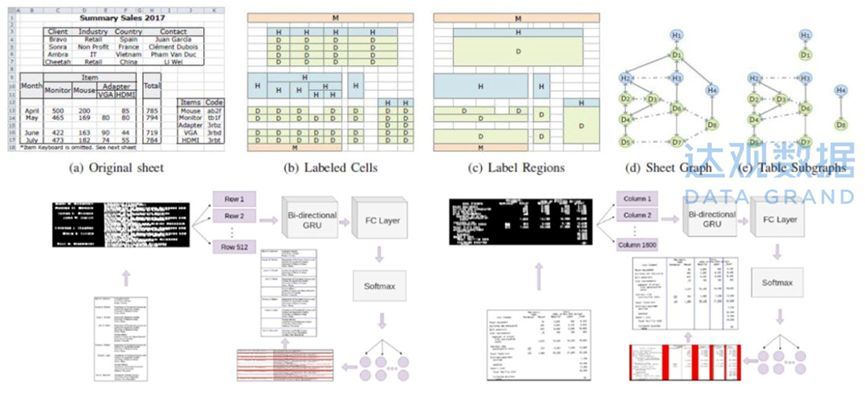 ICDAR中基于深度学习的表格检测和识别算法
ICDAR中基于深度学习的表格检测和识别算法
近年来通过ICDAR的技术竞赛,有一些优秀的方法涌现出来,在这个领域里国内也出现了很多研究团队,如北京大学的高良才老师提出了很多优秀的研究成果。
和一些直接套用计算机视觉检测的方法不同,表格因为有横列纵列的重复分布特征,所以利用这个特征来进行识别往往能取得更有针对性的效果,ICDAR2019论文Table structure extraction with Bi-directional Gated Recurrent Unit Networks提出了使用循环神经网络来进行表格结构识别任务。在一系列基础性的二值化和膨胀预处理后,将图像按像素行或列放入独立的两个两层双向循环神经网络,同时将某个像素行或列的相邻两个邻居考虑进去。接着将循环神经网络的输出行列特征分类为是否属于行列分隔符区域,最终把预测分隔区域的中点作为最终的行列分割结果。GRU网络的效果相比LSTM整体略好。
达观的实践总结与展望
在达观实践OCR产品过程中,我们发现一旦版面分析工作做扎实后,文本检测就变得很容易了。而完成文本识别后,利用语义上下文技术,对内容进行结构化提取就是IDP系统来完成的工作了,Attention以及NLP的一些模型可以很好发挥长处。
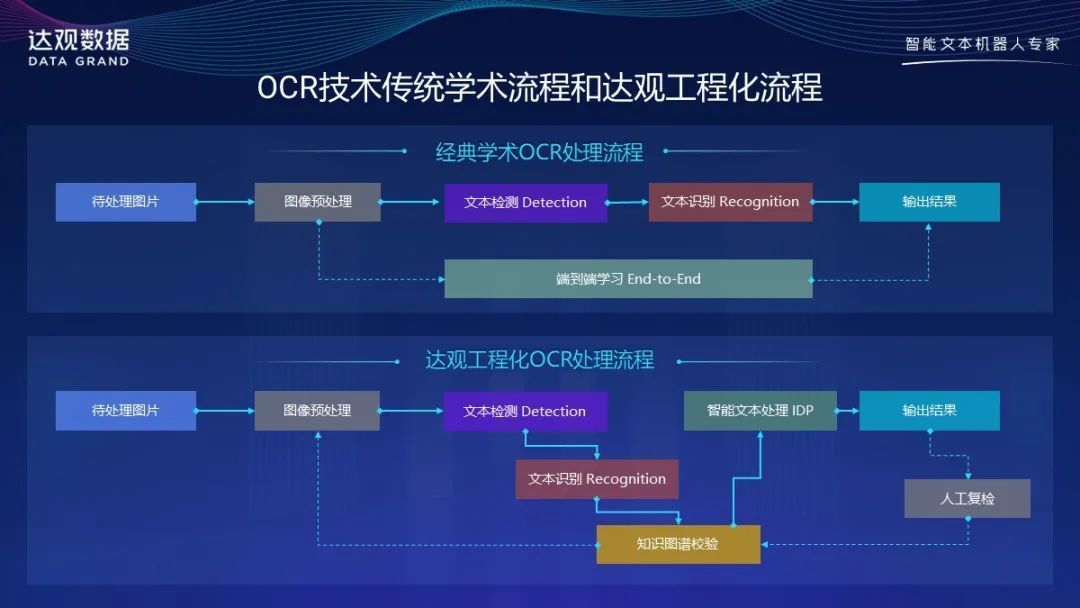 达观工程化OCR处理流程
达观工程化OCR处理流程
如上图所示,为了更好地提升效果,充分运用行业知识校验对提升OCR效果也起到了重要作用。学术研究里通常不会涉及外部领域知识,但在实际落地应用中构造专业领域的知识图谱对每一个垂直细分领域的文本OCR任务都有巨大的收益。
例如财务报表OCR中,各类数字之间隐含的勾稽关系(如利润表中的“主营业务成本”与资产负债表中的“应付账款”以及现金流浪表中的“购买商务和劳务支出”可以进行交叉校验)可以用于对OCR提取的数字进行校验和纠正,大幅提升准确率。再比如IPO招股书中的企业经营数据,会在相应的审计报告中再次出现,如果引入投行的专业经验,那么对OCR的处理效果会有很大帮助。最后,人工复检工作以及相应的结果自动反馈机制也非常重要,人工复检不仅能让系统最终实现100%的准确率,并且人工纠正后的结果能不断作为训练样本用于矫正原有系统的问题,从而能让系统越来越“聪明”,逐步逼近更高的识别准确率。
在达观近年来将IDP、知识图谱和OCR进行融合来进行工程实践的过程中,我们深刻领会到一个优秀的产品一定要实事求是的吸收各种思想的优点,既要有传统方法的长处,也要借鉴最新网络模型的优点。对数据的积累和标注是一个持之以恒的事情,产品的使用细节体验,人机交互的过程也需要不断地完善和提升。好的产品从来都不是一蹴而就的,而是需要反复打磨和持续改进的。随着OCR技术近年来不断向前发展,和各类下游的应用场景,如文档审核、语义理解、RPA等的结合日益增多,OCR的应用还将发挥越来越大的价值。(达观数据陈运文)
作者简介
陈运文,达观数据董事长兼CEO。复旦大学计算机博士,优秀博士论文奖获得者,国家“万人计划”专家,2021年中国青年创业奖,中国五四青年奖章,上海市十大青年科技杰出贡献奖获得者,上海市优秀技术带头人,第九届上海青年科技英才;国际计算机学会(ACM)、电子电器工程师学会(IEEE)、中国计算机学会(CCF)、中国人工智能学会(CAAI)高级会员,上海市计算机学会多媒体分会副会长;上海市首批人工智能正高级职称获得者。在人工智能领域拥有近百项国家技术发明专利,是复旦大学、上海财经大学、上海外国语学院聘任的校外研究生导师,在IEEE Transactions、SIGKDD等国际顶级学术期刊和会议上发表数十篇高水平科研成果论文,出版《智能RPA实战》、人工智能经典著作《智能Web 算法》(第2 版),参与撰写《数据实践之美》等论著;曾多次摘取ACM KDD CUP、CIKM、EMI Hackathon等世界最顶尖的大数据竞赛的冠亚军荣誉。曾担任盛大文学首席数据官、腾讯文学高级总监、百度核心技术研发工程师。在机器学习、自然语言处理、搜索推荐等领域有丰富的研究和工程经验。