
上文中始终未提到前向算法与Viterbi算法,主要是因为想特意强调一下数学解不等同于算法解。算法解考虑进了计算的性能问题,算法是为计算机设计的。
首先看一下“评估”问题中的时间开销。回顾一下公式:
P(O) = sigmaO P(O|C)P(C)= sigmaO P(C1)P(O1|C1)P(C2|C1)P(O2|C2)…P(Ci|Ci-1)P(Oi|Ci)
如果我们使用枚举的方法来求解,那么对于C来说,设有N种状态,序列长度为T,那么所有可能的隐藏序列组合为N`T(N的T次方)个,对于每一个序列需要的乘法次数为2T次,而加法需要T次,那么总共需要的计算次数为2T*N`T的级数(精确的,需要(2T-1)N`T次乘法,N`T-1词加法)。例如N=5,T=100,那么需要约2*100*5`100约10`72次计算,显然我们需要一个更好的算法。
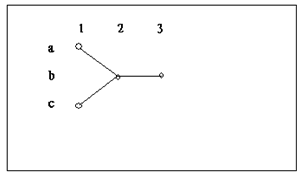
考虑上图这个简单的例子,图中描述了两个隐藏序列:abb,cbb。为了求得P(O),使用枚举算法有:
Pia * P(O1|a)*Pab*P(O2|b)*Pbb*P(O3|b) + Pic * P(O1|c)*Pcb*P(O2|b)*Pbb*P(O3|b)
Pi代表初始概率,使用前向算法有:
(Pia* P(O1|a) *Pab + Pic * P(O1|c)*Pcb) *P(O2|b)*Pbb* P(O3|b)
其中前向算法中的第一个大括号中的式子为局部概率a2(b),可以清楚的看到枚举算法用了10次乘法和1次加法,而前向算法把乘法次数减少到了7次,原因就是前向算法使用了大家熟知的“乘法分配律”提取了公因式。看起来好像提升不多,不过当计算量大的话这种提升就很可观了。事实上,前向算法将计算次数减低到了N`2*T的级数,那么对于N=5,T=100只需要约3000次计算即可。
现在使用上面的例子考虑一下Viterbi算法,使用枚举算法我们需要计算:
Pia * P(O1|a)*Pab*P(O2|b)*Pbb*P(O3|b) 和 Pic * P(O1|c)*Pcb*P(O2|b)*Pbb* P(O3|b)
并比较求得其中较大的一个,而使用Viterbi算法,我们首先比较:
Pia *P(O1|a)*Pab 与 Pic * P(O1|c)*Pcb 的大小,选出较大的一个再乘以 Pbb* P(O3|b)
10次乘法一次比较,减少到5词乘法一次比较。
总结一下,前向算法和Viterbi算法分别从两种角度向我们展现了降低计算复杂度的方法,一种是提取公因式减少计算次数,例如计算(1+2+3)* 5 和 1*5+2*5+3*5,从数学角度来看只是表达的不同,但对于计算者(无论是人还是计算机)来说,少的计算次数意味着更小的计算时间开销;另一种是,去掉不必要的计算,要找到最大的隐藏序列,如果在子序列上都不能取得最大还有必要去计算全序列吗?
非常感谢,期待后续!
[回复]
使用前向算法:
(Pia* P(O1|a) *Pab + Pic * P(O1|c)*Pcb) *Pbb* P(O3|b)
缺少了枚举算法中的一项:P(O2|b)
按照你所说的提取公因式,前向算法公式应该是这样的:
Pia * P(O1|a)*Pab*P(O2|b)*Pbb*P(O3|b) + Pic * P(O1|c)*Pcb*P(O2|b)*Pbb*P(O3|b) ——>(Pia * P(O1|a)*Pab+ Pic * P(O1|c)*Pcb)*P(O2|b)*Pbb*P(O3|b) ;
另外我怎么感觉在利用hmm进行分词时,前向后向算法没有使用到呢?
[回复]
itenyh 回复:
6 4 月, 2012 at 09:32
谢谢!已修改。
前向-后向算法(Baum-Welch算法)是一种无监督的训练方法。在我的下一集的分词器的介绍中,我是用的是统计的方法在训练集上得到HMM的模型参数,训练集已事先标好了隐藏状态标记(B,M,E,S)。前向-后向算法可以在只给定观察序列的情况下求得HMM模型,也即不需要进行隐藏状态标记(所以称为“无监督”)。
一个具体的例子:《HMM在自然语言处理中的应用一:词性标注3》
原理:《HMM学习最佳范例七:前向-后向算法1》
如果有不明白的地方,希望相互交流,我的qq:405243093
[回复]
非常感谢博主带给我们这么专业的NLP知识,本人Screen一直想做NLP这个领域,对这方面的知识更是求知若渴。
再一次感谢!
[回复]