
The pooling operation used in convolutional neural networks is a big mistake and the fact that it works so well is a disaster. ——Hinton
先引用深度学习三巨头之一Geoffrey Hinton(杰弗里·辛顿)对CNN的见解作为开端(老师说这样写作能得高分)
CNN是现在十分火热的模型,首先我们都知道,通过pooling层能够学到部分高阶特征,比如对于人脸而言可以激活识别到鼻子 ,嘴巴 ,眼睛 等。
大神们看到CNN模型的强大开始进行本质的思索,那么它有什么搞不懂的时候咩?
答:确实有。
具体来说,pooling并不能够学到这些特征具体是从哪一层特征学到的,也就意味着会损失高阶特征之间的相互空间关系,空间层级信息无法获取到。也就是混乱的 并不能够表征一张人脸。这就是pooling层存在的缺陷。
好吧,简言之就是脸盲。

我们接着来看,计算机得到图像的过程是一层一层,从图像的内部表示到整体图像表示。但是人对图像的认识恰恰相反!
科普时间到:
人脑对图像的认识关键的点在于图像位置姿态的认识,也就是即便图像进行了旋转,平移人脑依然可以认识图像,而计算机却不行。因此提出胶囊网络CapsNet。
那么我们来正经地看看到底什么是胶囊(总之不是吃的那个小药丸💊)
一:胶囊的定义
胶囊(Capsule)是一个,包含多个神经元的特征载体。每个神经元可以表示图像中出现的特定实体的各种属性,比如姿态(位置,大小,方向),纹理,变形等。
胶囊以向量的形式封装特征的各种属性表示。数值就是这个属性表示存在的概率,会随着特征的空间变化而变化,向量的长度保持不变的话,整个胶囊表征的高层特征就保持一致,这就是Hinton提出的活动等变性,这个不变性的意义高于pooling的不变性。

听懂以上概念后,大神小伙伴们就接着来看它的运算过程吧。
二:胶囊卷积运算过程
- 输入向量的矩阵乘法
- 输入向量的标量加权
- 加权输入向量之和
- 向量到向量的非线性变换
总之就是先这样,再那样就好啦~

好了,回归干货:
$u_1$、$u_2$、$u_3$就是来自下层的3个胶囊💊,向量的长度编码了下层胶囊相应特征的概率。
那么
$w_{1j}$、$w_{2j}$、$w_{3j}$就能够编码高层特征和低层特征之间的空间关系。
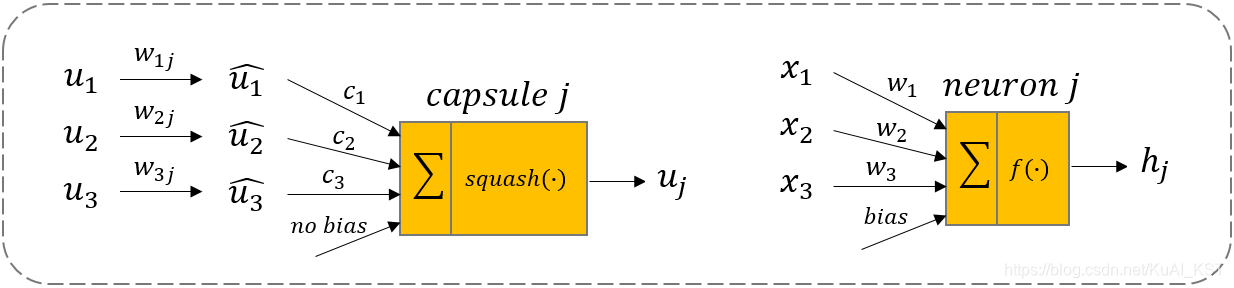
神经网络是通过反向传播来学习参数,而胶囊网络是通过“动态路由”算法来进行更新。
低层胶囊需要决定它的输出是向哪个高层胶囊输出。通过学习$c_i$才能够激活是向哪个方向的胶囊进行映射。
所以对于动态路由算法就是$u_j$服从的某个分布,每层胶囊会相对聚集,那么接下来学习的低层胶囊向哪个高层胶囊映射,就是通过这种预测更接近的胶囊聚集来判断的。
接下来向量到向量的非线性变换就是用了一个新颖的非线性激活函数,接收一个向量,然后在不改变方向的前提下,压缩它的长度到1以下。就是$squash(\bullet)$:
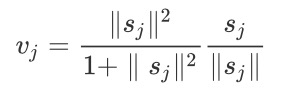
为了清晰地让大家理解,整来了一张图,更形象的描述整个学习过程:⬇️
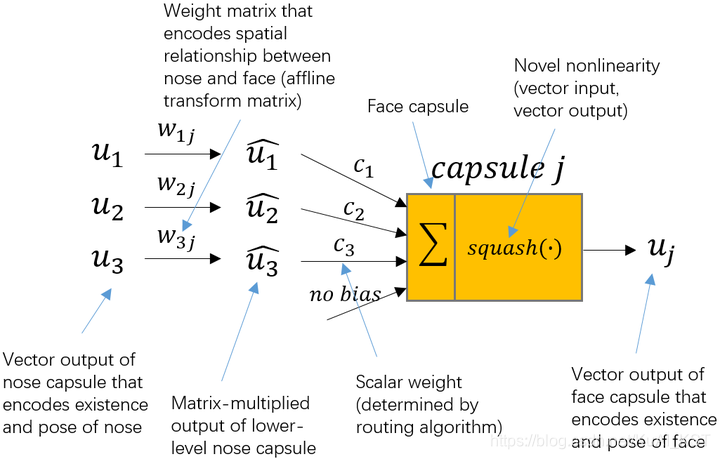
怎么样,是不是看着一下子就通透了起来呀^ ^
三:动态路由算法
好了我们继续往下肝⬇️

从上述算法过程就能够明白,输入为低层所有的胶囊线性变换的输出$\hat{u}{j|i}$以及路由迭代次数$r$和层$l$ 。定义了一个零时变量$b{ij}$初始化为0,在迭代过程中会更新,$c_i \leftarrow softmax(b_i)$就是低层胶囊所有的权重。
举个简单的小例子⬇️
权重分配过程:$b_{ij }$初始化为0,第一次迭代,假设有3个低层胶囊,2个高层胶囊,那么$c_{ij}$都会等于0.5,所有的权重$c_{ij}$都相等。
随着迭代才会使得低层胶囊可以根据这个权重指向对应的高层胶囊。$s_j \leftarrow \sum_i c_{ij} \hat{\mathbf{u}}{j|i}$ 就是对每一个胶囊做一个线性组合,然后通过$squash$函数得到传递方向不变的权重向量。最后更行相应的权重$b{ij}$。
(嗯!大神们是不是觉得很简单(o^^o)
高层胶囊$j$的当前输出和从低层胶囊 $i$出接收的输入做点积,再加上上一轮的权重$b_{ij}$,得到更新的$b_{ij}$。点积可以表征胶囊之间的相似性,其实也就是将低层胶囊的特征学习过来,这就与$CNN$的学习效果一致。
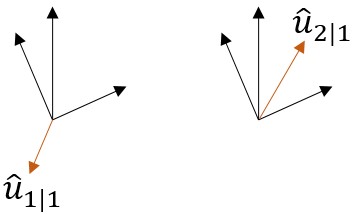
明显从上图就可以看出,$\hat{u}{1|1}$和上面黑色的向量不相似,$\hat{u}{2|1}$就和上面黑色的向量是相似的,那么路由权重$c_{11}$会降低,而$c_{12}$会增大。从而低层胶囊的学习就能有最优的匹配。
综上!一篇简单的科普教学文就结束啦,谁用谁知道!
所以————
听懂掌声!
那下篇我们来简单聊聊「相似三连」:DNN、RNN、CNN里的RNN(递归神经网络)哟~
