
作者:刘绍孔(NLP算法工程师一枚)
Encoder部分相对简单,进行self-attention时只需要考虑一个batch内和长度相关的mask。这里重点讨论training和inference两种模式下decoder attention在每一层的工作机制。
在training模式下,decoder部分采用teacher_forcing的机制来产生decoder的输入,具体的实现方式是将原始的input_target_sequence右移动一位,或者可以理解为在原始的input_target_sequence最左侧添加一个decode_start_token。
我们首先来考察decoder的self_attention, mask为两部分tgt_mask和self_attention_mask。其中,tgt_mask和tgt的长度相关, self_attention_mask为三角矩阵的形式(对角线及下三角为0, 上三角为很大的负数,如-1e9),可以保证在计算某一个位置的token时,这一位置之后的token对该位置的输出结果不产生影响,原理为
softmax(K*q + (-1e9)) * V
这里的K, V是当前q位置之后的任意位置对应的k,v的集合。
在training阶段,每一层的self_attention通过teacher_forcing和mask (tgt_mask + self_attention_mask)来并行计算出每一个位置对应的输出。(并行计算就是计算方式和encoder部分的self_attention计算方式一样,一次全部输入,而不是每次只输入一个token)。
接下来是cross_attention部分,cross_attention部分的Q是由self_attention的输出通过一个q_proj转换矩阵得到的,K和V是由encoder的输出分别经过两个转换矩阵k_proj和v_proj得到的,接着用(Q, K, V)来计算每个位置的输出。
Decoder的每一层叠加起来,到最后一层输出时,通过一个softmax_embedding矩阵转换得到每个位置的输出向量,其大小等于tgt语言的词表大小,这时可以计算一个batch内的loss,此时loss还需要考虑到一个batch内各句的长度,即需要乘上一个tgt_mask.
我们看到,在training阶段由于用到了teacher_forcing和mask机制,所以可将一个batch内decoder端的input_tokens一次输入,并最终得通过损失函数得到这个batch的loss。Decoder中间各层的self_attention和cross_attention的计算结果在后面不需要用到,所以也不需要保存。
接下来,我们来看transformer的inference状态下各部分的attention计算。
Encoder端由于全部信息已知,所以输入和计算模式与在training阶段一样,也只涉及到一般形式下的self-attention计算。
在decoder端,每次只输入一个token(batch内每个句子输入一个token,实际输入batch_size个tokens),在一个decoder_layer内,依次进行self_attention和cross_attention的计算。假设在输入这个token时,已经解码出n个token,这时self_attention计算时只需要知道当前解码位置的token对应的q和前面n个tokens对应的(K, V)。这里可以看出,前面n的token的 (K, V) 可以保存下来,这时只需要计算当前token在这一层的 (q, k, v), 其中q用于和前面n个token的(K,V)进行attenton计算,计算完成后再将当前位置的(k, v)分别添加到(K, V)上面,作为下一步解码时的 (K, V).
self attention并不对之前位置已经生成的信息产生影响,self_attention也只输出当前解码位置的hidden_state向量给接下来的corss_attention。cross attention的 (K, V)在第一次解码时生成,并且在后面的解码过程中重复用到,因此可以保存下来。这里cross_attention的 (K, V) 是通过encoder的输出(encoder_hidden_states)经过该层cross_attention的k_proj和v_proj矩阵变换得到,因此在后续的解码中,不会随着解码长度的逐渐增加而改变。
综上所述,transformer模型的decoder在training时,不需要保存各层的计算结果,只需要最终输出各个位置上对应的token classification label(词表大小),来和true_label计算损失(cross_entropy)。在inference模式下,由于每次只输入一个token,因此可以将已经解码出来的tokens对应的(K, V)保存下来,在self_attention和cross_attention计算时直接使用,self_attention各层的(K, V)随着解码长度的增加而增加,cross_attention各层的(K, V)在第一次解码时计算出来(由encoder-outputs转换得到),后面不随解码长度的增加而变化。
正是基于以上的思想,
1. 我们在实践中为开源框架THUMT增加了inference cross_attention cache机制。
2. 开源项目fastt5中,将transformer(t5)模型拆分为3个onnx模型,(encoder.onnx, decoder_init.onnx, decoder.onnx), 其中decoder_init.onnx只涉及第一步的解码,即生成cross_attention的K和V,以及self_attention的K和V。
因此如果将上述3个onnx模型简并为2个,可以在encoder输出时,将decoder部分的self_attn_kv和cross_attn_kv创造或计算出来,
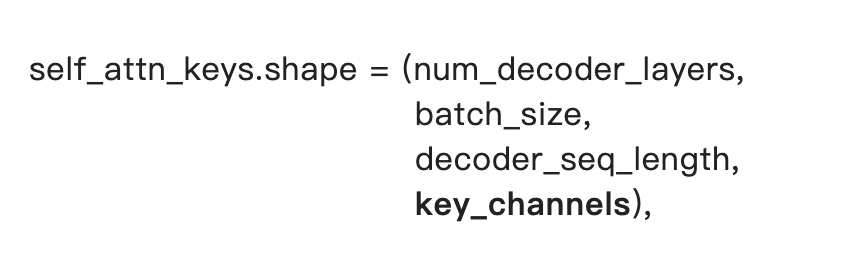
其中decoder_seq_length设置为0, 在后续的decoder解码中进行相应变化。
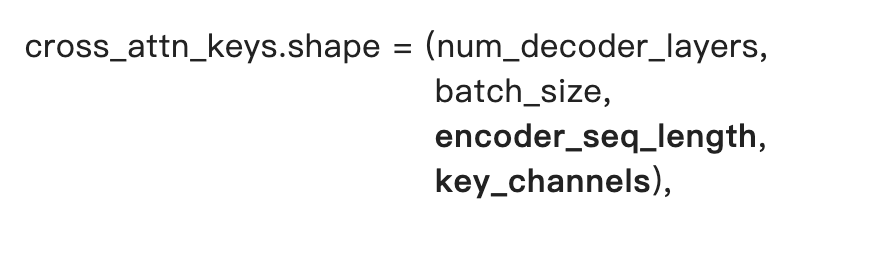
self_attn_values和cross_attn_values的形状与其对应的keys的形状只是最后一个维度上有区别(value_channels)。
self_attn相关的keys和values可以通过torch.ones()创造出来,cross_attn的keys和values则需要抽取decoder各层的k_proj和v_proj参数进行计算得到(需要微调模型结构)。