
七、前向-后向算法(Forward-backward algorithm)
要理解前向-后向算法,首先需要了解两个算法:后向算法和EM算法。后向算法是必须的,因为前向-后向算法就是利用了前向算法与后向算法中的变量因子,其得名也因于此;而EM算法不是必须的,不过由于前向-后向算法是EM算法的一个特例,因此了解一下EM算法也是有好处的,说实话,对于EM算法,我也是云里雾里的。好了,废话少说,我们先谈谈后向算法。
1、后向算法(Backward algorithm)
其实如果理解了前向算法,后向算法也是比较好理解的,这里首先重新定义一下前向算法中的局部概率at(i),称其为前向变量,这也是为前向-后向算法做点准备:

相似地,我们也可以定义一个后向变量Bt(i)(同样可以理解为一个局部概率):
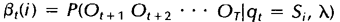
后向变量(局部概率)表示的是已知隐马尔科夫模型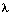 及t时刻位于隐藏状态Si这一事实,从t+1时刻到终止时刻的局部观察序列的概率。同样与前向算法相似,我们可以从后向前(故称之为后向算法)递归地计算后向变量:
及t时刻位于隐藏状态Si这一事实,从t+1时刻到终止时刻的局部观察序列的概率。同样与前向算法相似,我们可以从后向前(故称之为后向算法)递归地计算后向变量:
1)初始化,令t=T时刻所有状态的后向变量为1:

2)归纳,递归计算每个时间点,t=T-1,T-2,…,1时的后向变量:
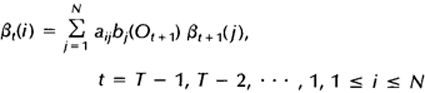
这样就可以计算每个时间点上所有的隐藏状态所对应的后向变量,如果需要利用后向算法计算观察序列的概率,只需将t=1时刻的后向变量(局部概率)相加即可。下图显示的是t+1时刻与t时刻的后向变量之间的关系:
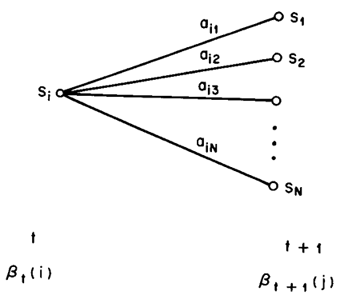
上述主要参考自HMM经典论文《A tutorial on Hidden Markov Models and selected applications in speech recognition》。下面我们给出利用后向算法计算观察序列概率的程序示例,这个程序仍然来自于UMDHMM。
后向算法程序示例如下(在backward.c中):
void Backward(HMM *phmm, int T, int *O, double **beta, double *pprob)
{
int i, j; /* state indices */
int t; /* time index */
double sum;
/* 1. Initialization */
for (i = 1; i <= phmm->N; i++)
beta[T][i] = 1.0;
/* 2. Induction */
for (t = T - 1; t >= 1; t--)
{
for (i = 1; i <= phmm->N; i++)
{
sum = 0.0;
for (j = 1; j <= phmm->N; j++)
sum += phmm->A[i][j] *
(phmm->B[j][O[t+1]])*beta[t+1][j];
beta[t][i] = sum;
}
}
/* 3. Termination */
*pprob = 0.0;
for (i = 1; i <= phmm->N; i++)
*pprob += beta[1][i];
}
好了,后向算法就到此为止了,下一节我们粗略的谈谈EM算法。
未完待续:前向-后向算法3
注:原创文章,转载请注明出处“我爱自然语言处理”:www.52nlp.cn
本文链接地址:https://www.52nlp.cn/hmm-learn-best-practices-seven-forward-backward-algorithm-2
博主您好,文中提到:“后向变量(局部概率)表示的是已知隐马尔科夫模型lamda及t时刻位于隐藏状态Si这一事实,从t+1时刻到终止时刻的局部观察序列的概率”。可是HMM假设观测值Ot只与当前的隐状态qt = Si有关。为什么后向变量Bt(i)可以定义成这样的一个条件概率呢?
[回复]
emnlp 回复:
9 5 月, 2011 at 19:40
当前的观测值确实只和当前的隐含状态相关,但是当前的隐含状态,却和其之前的隐含状态(观测值)相关了,... ,直到你逆推到t=0。如此以来,你想计算某时刻观测概率,那就得从头t=0一遍。。。 这里讲的几种算法,是提供如何有效计算这种概率的方法。
要不你先看看 前面的前向算法?
[回复]
博主您好:
对于后向变量我有个地方不理解:就是 初始化的时候,为什么 在 t = T
时候, βT(i) = 1 (1≤i≤N )
也就是在 最后一个 时间 T ,每个状态所对应的 后向变量值 为什么会是 1,为什么每个状态对应的 后向变量值会相等,这个地方我理解不了。
[回复]
helld123 回复:
23 1 月, 2014 at 14:19
文中提到:“后向变量(局部概率)表示的是已知隐马尔科夫模型lamda及t时刻位于隐藏状态Si这一事实,从t+1时刻到终止时刻的局部观察序列的概率”。所以在t=T时候,从t=T转到t=T+1(观察序列已经结束)时候的转换概率认为是1,t=T+1的隐藏状态到t=T+1时的观察状态的转换概率也为1。所以认为每个βT(i) = 1 (1≤i≤N )
[回复]
helld123 回复:
23 1 月, 2014 at 14:26
晕,回复过才发现楼下已经有人讨论过了,^~^
[回复]
博主您好:
对后向算法有个地方我不是很理解,就是在初始化的时候,令t=T时刻所有状态的后向变量为1:
βT(i) = 1 (1≤i≤N )
在 t = T时,为什么它的后向变量值会是 1 呢,该如何理解?是跟 “已知隐马尔科夫模型及t时刻位于隐藏状态Si这一事实” 相关吗?
[回复]
52nlp 回复:
31 1 月, 2013 at 14:22
sorry, 这个问题没仔细思考过,我理解初始值的设定对最终的结果影响不大,所以都初始化为1的。
[回复]
tt163789 回复:
31 1 月, 2013 at 18:21
我跟同学是这样认为的,T为最后一个时刻,假定在T+1时刻,有一个虚拟的状态和一个虚拟的观察值,这个虚拟的状态用来表示:T时刻状态的结束,虚拟的观察值表示T时刻的观察值为最后一个观察值,这样在T时刻时的后向变量,由于状态转移,由T时刻时的状态转移到T+1时刻的状态,并且由T+1时刻状态输出观察值O(T+1),由于T时刻为最后时刻,因此,这种转移是必然事件,所以,在T时刻,后向变量值为1,不知道这样的理解对不对?希望收到你的回复,谢谢。
[回复]
52nlp 回复:
1 2 月, 2013 at 21:57
赞穷根究底的精神,不过感觉你把这个问题考虑的太复杂了。建议去读读HMM的几篇英文PAPER,看看有没有解读。
biojamie 回复:
31 7 月, 2013 at 14:42
我觉得这里初始值的定义,可以从两个方面去理解,第一是从时刻T-1开始计算,会直接得到βT(i) = 1的结果,第二,从意义上来说,它代表“从oT到序列的停止,是一个必然过程”,因为模型初始假定的观察序列即到T时刻,我的博客,对隐马模型做了些解读,互相交流学习。
http://biojamie.blog.163.com/
[回复]
lalala 回复:
7 5 月, 2015 at 10:09
确实啊,可以看到后向算法中的转移概率是aij,而不是aji,而且,也是从左到右的计算概率和,这样的话,t=T-1时刻到t=T时刻便是最后一个概率值分量,因此,后向算法中BT(i)根本就不起作用,可有可无,又因为是乘法因子,所以就等于1了
[回复]
请问,用后向算法评估和前向算法评估出来的结果一致吗?如果不一致,请问为什么呢?
我自己编了一小段程序,前向结果与给的范例相符,但是后向的结果不一致。
盼复!
[回复]
liyi 回复:
2 6 月, 2013 at 23:08
不好意思,打扰您了!
我又仔细检查了一下,发现我对后向算法的理解有误。
顺便对您无私地翻译该文献表示万分感谢,对我的帮助非常大!
再次向您致敬!
[回复]
52nlp 回复:
2 6 月, 2013 at 23:13
抱歉,刚看到,自己解决就好。
[回复]
/* 3. Termination */
*pprob = 0.0;
for (i = 1; i N; i++)
*pprob += beta[1][i];
这代码算的结果和forward algorithm,exhaustion algorithm的结果不一样
正确的终结函数应该是
终结函数Pr(o|r) = sum(beta(1,i) * Pi(i) * b(i,o1))
[回复]
helld123 回复:
23 1 月, 2014 at 14:24
正解,自己写了一个前向和后向的算法,对比了一下最后的概率结果,UMDHMM的后向算法的最后一步确实有问题
[回复]
wen73 回复:
22 3 月, 2015 at 12:02
确实是这样 xiexie
[回复]
小鹿 回复:
11 6 月, 2016 at 11:29
请问正确是这个样子吗?
/* 3. Termination */
*pprob = 0.0;
for (i = 1; i N; i++)
*pprob += beta[1][i]*phmm->pi[i]*phmm->B[i][1];
你好,首先谢谢你的教程,对我们初学者帮助很大!
在这篇后向算法中,请问一下可否用向前算法得到同样的结果?以为t是确定的Si状态,那么t+1可否看成一个初始值,求给定HMM时Ot,Ot+1..O_T的概率?用前文提到的向前算法计算并求和?
[回复]
很抱歉,网络似乎有问题,发了三次,前两次还是未完稿。
请博主帮忙把之前的两个评论删除吧,我删不了
我对前向算法的intuition理解(不一定对,请博主点拨,再次感谢。
稍微涉及一点共轭先验和EM的思想;我看了博主关于EM的blog,写的很好,这里是尽量从intuition来解释):
先简单点,假设就1层,4个状态节点
1,假设各个节点的概率都是1/4,即我们有了P(State_i),注意这是Prior概率;
2,P(Observation|State_i)的含义是:根据观察Observation,各个状态节点的概率不应该都是prior=1/4,应该调整一下,有点后验概率的意思;所以P(Observation|State_i)*P(State_i)的含义是:根据观察,各个状态节点调整以后的概率分布,这才是我们真正要用的分布。
现在假设有2层:
1,第一层的prior概率已经有了,就是上面的P(Observation|State_i)*P(State_i)
2,第一层某节点i的prior概率 乘以 它的转移概率(转移到k状态),把这种东西全加起来(即sum i),自然就得到了第二层处于k的概率,这个很好理解。
3,还没完,由于第二层我们也有观察量Observation,它有信息含量,得用上,怎么用?类似上面的,P(Observation|State_k)*P(State_k)
结束
⚠:关于第2点,思想有点类似conjugate prior(共轭先验,https://en.wikipedia.org/wiki/Conjugate_prior)
例如,抛硬币、观察结果、估计硬币的正面概率x
Prior(x)=0.5是合理假设,因为我们没有任何信息
Obsersvation (即O): 拋个3次得到2个正面,那么应该更新一下P(x)分布
又抛了5次得到4个正面,应该再更新一次P(x)分布
{注:
Prob(x|O)= Prob(O|x)P(x)/P(O), 注意P(O)可以干掉,因为要估计的是参数x,与O没关系,事实上1/P(O)的实质作用只是归一化系数。Prob(O|x)P(x)对x作积分不等于1,不能成为一个概率函数;1/P(O)这个系数的作用是使得 Prob(O|x)P(x)/P(O)对x做积分等于1,即归一化使其成为一个概率函数。
}
Prob(x|O)= Prob(O|x)Prior(x)中的
Prob(O|x)是 “用先有参数x得到的观察量O的似然概率函数”
即:后验=似然*先验
其实,以后用这个后验的时候,是当作“新的先验”来用的,也就是每当有了新数据就迭代一次;这和HMM不断用新的观察量来更新的做法是一致的,
事实上是“共轭先验”+“动态规划”的思想。
[回复]
示在耳边 回复:
18 9 月, 2018 at 12:08
你的注部分说的很好。这也是这个系列文章中相关算法原理所默认的一点。
但问题是,1/P(O)是归一化系数,仅仅是从贝叶斯公式的形式上来看的,本质上,去掉1/P(O)之后的概率Prob(O|x)P(x)/P(O),并不是Prob(x|O)的计算结果,也不是为了计算Prob(x|O)而做近似处理。而是因为,算法的目标是找最优,即比较概率大小,而不需要知道确切的概率值。这样Prob(x|O)的计算,就跟1/P(O)没有关系了,可以直接用“似然*先验”的形式来更新这个“后验概率”。
但大多数的文章,一上来就做了这个处理,以至于后来的很多引用文献都默认“似然*先验”的计算结果是后验概率的值!严格意义上来说,这时不对的。这个问题在原作者这里也是存在的。因此,原作者对于这一系列文章中的局部概率的定义实际上并不准确。
[回复]